This article was published as a part of the Data Science Blogathon.
Introduction
As ML applications are maturing over time and becoming an indispensable component of industries for making faster and accurate decisions for critical and high-value transactions.
For example,
1. Recommendation system to increase click-through rate for e-commerce.
2. Increasing engagement time users for social media apps.
3. Applications in the medical field and self-driving cars.
In all the above scenarios, the expected ML response is accurate, fast, and reliable. Scalability, maintainability, and adaptability also become critical as we move towards making ML one of the main components of enterprise-level applications. Hence, designing of end to end system keeping requirements of ML becomes important.
Machine Learning System Design
System design for machine learning refers to the process of designing the architecture and infrastructure necessary to support the development and deployment of machine learning models. It involves designing the overall system that incorporates data collection, preprocessing, model training, evaluation, and inference.
The process of defining an interface, algorithm, data infrastructure, and hardware for ML Learning system to meet specific requirements of reliability, scalability, maintainability, and adaptability.
Reliability
The system should be able to perform the correct function at the desired level of performance under a specified environment. Testing for the reliability of ML systems where learning is done from data is tricky as its failure does not mean it will give an error, it may simply give garbage outputs i.e. it may produce some outputs even though it does not have seen that corresponding ground truth during training.
The normal system fails: you get an error message e.g. There is some technical issue, the team is working on, will come back soon…
ML system fails: It fails silently, e.g. sometimes in language translation system (English to Hindi or vice versa), even though the model has not seen some words, it still might give some translation, which does not make sense.
Scalability
As the system grows (in data volume, traffic volume, or complexity), there should be reasonable ways of dealing with that growth. There should be automatic provision to scale compute/storage capacity because for some critical applications even 1 hour of downtime/failure can cause in loss of millions of dollars/credibility of the app.
As an example, if for an e-commerce website on a prime day, if certain feature failure i.e. not working as expected, that may turn into revenue loss in order of millions.
Maintainability
Over the time period, data distribution might get change, and hence model performance. There should be a provision in the ML system to first identify if there is any model drift/data drift, and once the significant drift is observed, then how to re-train/re-fresh and enable updated ML model without disturbing the current operation of the ML system.
Adaptability
other changes that most frequently comes in the ML systems are the availability of new data with added features or changes in business objectives e.g. conversion rate vs engagement time from customers for e-commerce. Thus, the system should be flexible to quick updates without any service interruptions.
Schematic Diagram for ML System
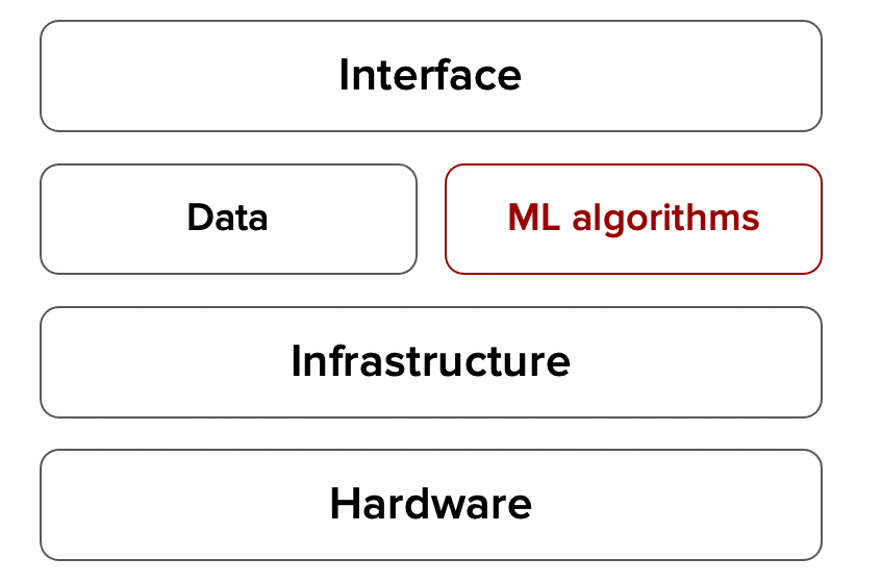
For, designing the ML system we need to consider all the above-Data, ML algorithms, related infrastructure, hardware, and Interface.
Few of the high-level considerations for design,
Data
1. Feature expectations are captured in a schema – ranges of the feature values well captured to avoid any un-expected value, which might result in garbage response e.g. human age/height have expected value range, it can’t be very large e.g. age value 150+, hight – 10 feet, etc.
2. All features are beneficial – features added in the system should have some usefulness in terms of predictive power or some identifier because each feature added has an associated handling cost.
3. No feature’s cost is too much– trade-off of cost vs benefits must be done for each feature added to remove features which has too little to add and too much to handle.
4. Features adhere to meta-level requirements – features used should match the project requirements e.g. there might be certain features that can’t be used in the model e.g. sex, age, race, etc.
5. The data pipeline has appropriate privacy controls – e.g. personally identifiable information (PII) should be properly handled, because any leakage of this data may lead to legal consequences.
6. New features that can be added quickly-this will help in adding new features to improve system performance if any new external factor is impacting the system.
7. All input feature code is tested – all features e.g. one hot encoding/binning features or any other transformations code must be tested to avoid any intermediate values going off the expected range e.g. handling of unseen levels in one-hot encoded features.
Model
1. Model specs are reviewed and submitted– proper versioning of the model learning code is needed for faster re-training.
2. Offline and online metrics correlate– model metrics (log loss, mape, mse) should well correlated with the objective of application e.g. revenue/cost/time.
3. All hyperparameters have been tuned– hyperparameters, such as learning rates, number of layers, layer sizes, max depth, and regularization coefficients must be tuned for the use case. Because the choice of hyperparameter values can have a dramatic impact on prediction quality.
4. The impact of model staleness is known-how frequently re-train models based on changes in data distribution should be known to serve the most updated model in production.
5. A simpler model is not better-benchmarking models with baseline i.e. simple linear model with high-level features is an effective strategy for functional testing and doing cost/benefit trade-off analysis against sophisticated models.
6. Model quality is sufficient on important data slices-model performance must be vetted against sufficiently representative data.
7. The model is tested for considerations of inclusion-model features should be well-vetted against importance in forecasting as in some applications certain features may bias results towards certain categories mostly for fairness purposes.
Infrastructure
1. Training is reproducible-training twice on the same data should produce two identical models. Generally, there might be some variations based on the precision of the system/infra used. But, there should not be any major difference.
2. Model specs are unit tested-It is important to unit test model algorithm correctness and model API service through random inputs to detect any error in code/response.
3. The ML pipeline is Integration tested– complete ML pipeline – assembling of training data, feature generation, model training, model verification, and deployment to a serving system must be tested for the correct function of the ML system.
4. Model quality is validated before serving-After a model is trained but before it actually serves the real requests, an offline/online system needs to inspect it and verify that its quality is sufficient.
5. The model is debuggable-When someone finds a case where the model is behaving bizarrely, it should be well logged to make it easy to debug.
6. Serving models can be rolled back- considering the behavior of ML systems which performance very much depends on non-stationary quality/distribution of input data, there should be well designed fallback mechanism if something went wrong in ML response.
Monitoring
1. Dependency changes result in notification-any changes in the downstream inputs of the ML system should be immediately notified to quickly check for any ML performance deterioration.
2. Data invariants hold for inputs-input data quality and distribution should remain statistically constant, and if any significant data drift is observed, the model should be refreshed/re-trained accordingly.
3. Training and serving are not skewed– feature generation code for both training and inference should be the same.
4. Models are numerically stable-Invalid or implausible numeric values that can potentially crop up during model training without triggering explicit errors, and knowing that they have occurred can speed diagnosis of the problem.
5. Computing performance has not regressed-model has not experienced regressions in training speed, serving latency, throughput.
6. Prediction quality has not regressed– Check for model performance metrics as soon as in production, after serving prediction request, true levels are available. If there is any significant model performance drift is observed, re-fresh/re-train the model.
Another important consideration that comes into ML system design is how to serve prediction, batch vs online based on business and resource availability requirements.
Batch prediction
1. Periodical e.g. hourly, weekly, etc.
2. Processing accumulated data when you don’t need immediate results (e.g. recommendation systems)
3. High throughput
4. Finite: need to know how many predictions to generate
Online prediction
1. As soon as requests come
2. When predictions are needed as soon as data sample is generated e.g., fraud detection
3. Low latency
4. Can be infinite
But, in some cases based on the business requirements, prediction can be served in a hybrid way- batch & online. Online prediction is the default, but common queries are precomputed and stored e.g., Restaurant recommendations use batch predictions, within each restaurant, item recommendations uses online predictions
Another consideration that comes, is cloud vs edge computing,
Cloud computing
1. Done on cloud
2. Need network connections for speedy data transfer
3. E.g., Most queries to Alexa, Siri, Google Assistant
Edge Computing
1. Done on edge devices (browsers, phones, tablets, laptops, smartwatches, etc.)
2. Need high power hardware for system -memory, compute power, energy for doing computations
3. E.g., Unlocking with fingerprint, faces
Benefits of Edge Computing
1. Can work without (Internet) connections or with unreliable connections
2. Don’t have to worry about network latency
3. Fewer concerns about privacy
4. Cheaper
On the ML learning side also, once the system is in production, the ML model can continually improve based on new data with offline and online learning mode, here are some of the highlights of the offline/online learning systems,
Offline Learning
1. Cadence of learning – weekly/monthly etc. depending on the use case
2. Batch Size- larger sample size, the order of millions
3. Mostly offline evaluations
4. Most of the systems follow this routine
Online Learning
1. Cadence of learning – continually (minutes)
2. Batch Size – Micro batches- hundreds of samples
3. Most relying on A/B testing kind of validation
4. Twitter #hashtag trending
Conclusion
As above described, we see creating production-level ML systems brings on a lot of challenges not found in small POC or even large offline research experiments e.g., system-level requirements- reliability, scalability, adaptability, and ML specific requirements – data, algorithms, model monitoring-model drift/covariate shift, model serving infrastructure – cloud/edge, model serving type-batch/online and model retraining -offline/online. Each step based on criticality and business requirements is important for the success of the ML-based systems.
Though, in most of the companies, the general process of data science is – Data Scientist completes POC for the specific business use case, fine-tune model based on business logic and specific model metrics, and then ship to software team for putting into production. This puts lots of system-level challenges e.g., the language of scripting mismatch – data scientist wrote code in R while production system needs in python/java, python libraries- version issue, other compatibility issue, latency requirements i.e., prediction request takes longer time than expected, etc.
Therefore, the data science team/data scientist needs to have high-level visibility about the production system, its functional requirements, and overall ML application objective/function.
Frequently Asked Questions
Q1. What is system design for machine learning?
A. System design for machine learning involves designing the overall architecture, components, and processes necessary to develop and deploy machine learning models effectively. It encompasses considerations such as data collection, preprocessing, model selection, training, evaluation, and deployment infrastructure, ensuring scalability, reliability, and performance to create a robust and efficient machine learning system.
Q2. What are the steps in designing a machine learning system?
A. Designing a machine learning system typically involves the following steps:
1. Problem Definition: Clearly define the problem you want to solve with machine learning.
2. Data Collection: Gather relevant and representative data for training and evaluation.
3. Data Preprocessing: Clean, transform, and normalize the data to make it suitable for training.
4. Model Selection: Choose the appropriate machine learning algorithm or model architecture.
5. Training: Train the selected model using the prepared data.
6. Evaluation: Assess the performance of the trained model using appropriate metrics.
7. Deployment: Integrate the model into a production environment for real-world use.
8. Monitoring and Maintenance: Continuously monitor the model’s performance, update it when necessary, and maintain its reliability and effectiveness.
References
The media shown in this article are not owned by Analytics Vidhya and is used at the Author’s discretion.






