Artificial intelligence (AI) helps us solve real-world problems by processing data. We turn real-world information into numbers for AI models to understand and improve. But a big question remains: How do we make sense of AI results in the real world? This is where Explainable AI comes in. It’s all about making AI’s decisions easy to understand and apply in real-life situations. In this article, we’ll explore Explainable AI, its importance, and how it helps bridge the gap between AI models and practical use.
Explainable AI (XAI) refers to methods and techniques in the application of artificial intelligence technology such that the results of the solution can be understood by humans. In the early phases of AI adoption, it was okay to not understand what the model predicts in a certain way, as long as it gives the correct outputs. Explaining how they work was not the first priority. Now, the focus is turning to build human interpretable models.
Explainable AI (XAI) matters because it helps us understand how AI systems work and make decisions. This is important for several reasons:
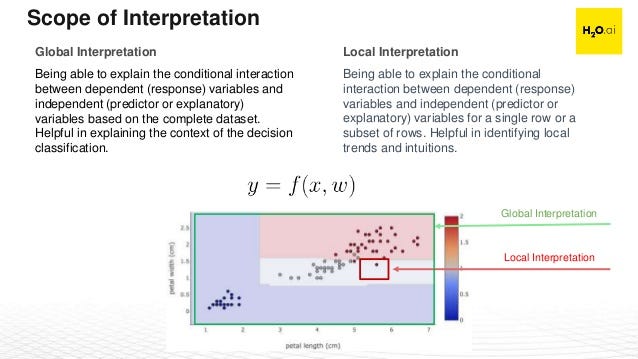
Model interpretability can be examined in two levels:
There are three main components that hoq explainable ai works:
Creating an easily understandable model involves selecting or designing models that are inherently more simple for humans to comprehend. An example of this is when a decision tree articulates its logic through a sequence of branching queries.
Describing post-analysis: This includes utilizing different techniques to evaluate a current model and generate interpretations for its results. Methods such as feature importance identify the data inputs that had the biggest impact on the decision.
Concentrating on the utilization of data: This may include examining biases in the training data or confirming the data’s relevance to the current task. Ultimately, the concept of “garbage in, garbage out” is also relevant in the context of AI.
In the industry, you will often hear that business stakeholders tend to prefer models that are more interpretable like linear models (linear\logistic regression) and trees which are intuitive, easy to validate, and explain to a non-expert in data science.
In contrast, when we look at the complex structure of real-life data, in the model building & selection phase, the interest is mostly shifted towards more advanced models. That way, we are more likely to obtain improved predictions.
Models like these (ensembles, neural networks, etc.) are called black-box models. As the model gets more advanced, it becomes harder to explain how it works. Inputs magically go into a box and voila! We get amazing results.
But, HOW?
When we suggest this model to stakeholders, will they completely trust it and immediately start using it? NO. They will ask questions and we should be ready to answer them.
We should consider both improving our model accuracy and not get lost in the explanation. There should be a balance between both.
![Resource: DPhi Advanced ML Bootcamp — Explainable AI [2]](https://miro.medium.com/max/774/1*0WgMRSF0kzTCqQPKFMldAw.png)
Here, I would like to share a sentence from Dipanjan Sarkar’s medium post about explainable AI:
Any machine learning model at its heart has a response function which tries to map and explain relationships and patterns between the independent (input) variables and the dependent (target or response) variable(s).
So, models take inputs and process them to get outputs. What if our data is biased? It will also make our model biased and therefore untrustworthy. It is important to understand & be able to explain to our models so that we can also trust their predictions and maybe even detect issues and fix them before presenting them to others.
To improve the interpretability of our models, there are various techniques some of which we already know and implement. Traditional techniques are exploratory data analysis, visualizations, and model evaluation metrics. With the help of them, we can get an idea of the model’s strategy. However, they have some limitations. To learn more about traditional ways and their limitations.
Other model interpretation techniques and libraries have been developed to overcome limitations. Some of these are :
These libraries use feature importance, partial dependence plots, individual conditional expectation plots to explain less complex models such as linear regression, logistic regression, decision trees, etc.
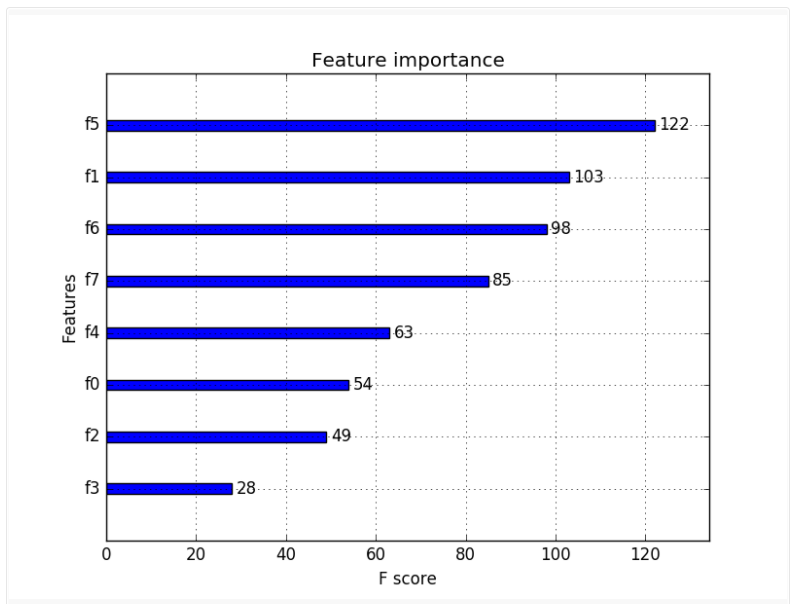
Feature importance shows how a feature is important for the model. In other words, when we delete the feature from the model, how our error changes? If the error increases a lot, this means that a feature is important for our model to predict the target variable.
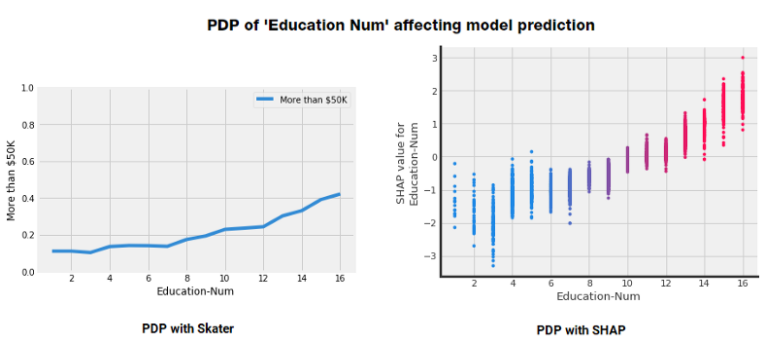
Partial dependence plots visualize the effect of the change for a certain feature when everything else is held constant (with a cooler phrase: ceteris paribus). With the help of these, we can see a possible limit value, where this value is exceeded, it directs the model predictions the other way. When we are visualizing partial dependence plots, we are examining the model globally.
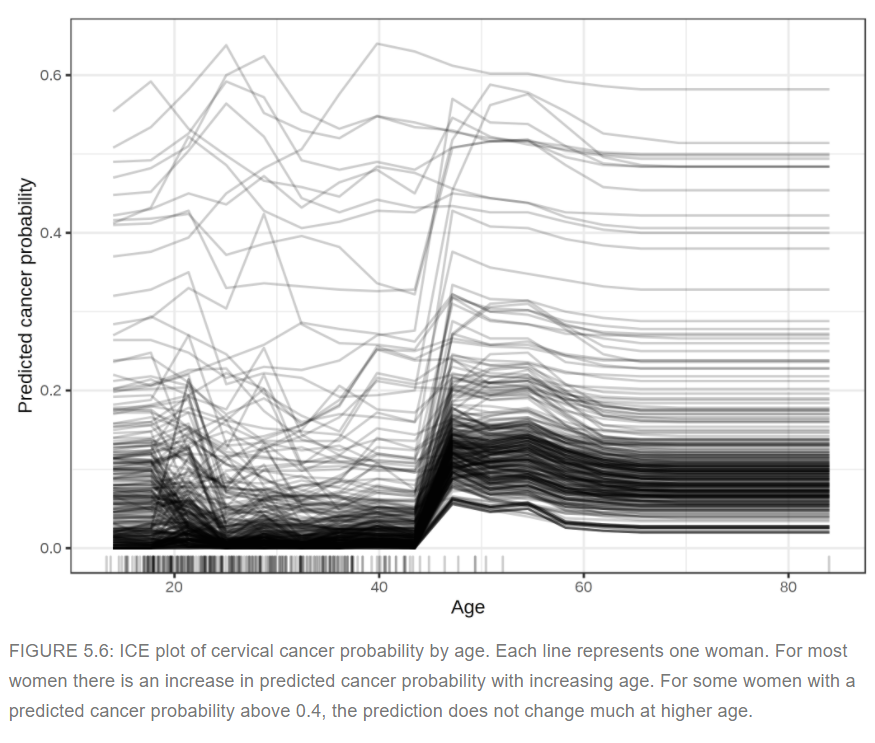
Individual conditional expectation plots show the effect of changes for a certain feature, just like partial dependency plots. But this time, the point of view is local. We are interested to see the effect of changes for a certain feature for all instances in our data. A partial dependence plot is the average of the lines of an ICE plot.
When it comes to explaining more advanced models, model-agnostic (does not depend on the model) techniques are used.
Global surrogate models take the original inputs and your black-box machine learning predictions. When this new dataset is used to train and test the appropriate global surrogate model (more interpretable models such as linear model, decision tree, etc.), it basically tries to mimic your black-box model’s predictions. By interpreting and visualizing this “easier” model, we get a better understanding of how our actual model predicts in a certain way.
Other interpretability tools are LIME, SHAP, ELI5, and SKATER libraries. We will talk about them in the next post, over a guided implementation.
The imperative to demystify these complex models is undeniable in a world increasingly shaped by AI. The power of Explainable AI lies in its ability to bridge the gap between inscrutable “black-box” algorithms and human understanding.
As this article has elucidated, integrating Explainable AI techniques equips us with the means to provide convincing explanations for AI model decisions. By doing so, we foster trust, ensure accountability, and enable better decision-making. As we journey into the age of AI, embracing transparency through Explainable AI is not just a choice; it’s a necessity. It empowers us to harness the full potential of AI, making its inner workings accessible to all. Also, in this article we have talk about the Explainable ai Examples.
A. An example of explainable AI is a decision tree model used for credit scoring. It provides a clear, step-by-step explanation of how it assigns credit scores based on income and credit history.
A. The difference between explainable AI and AI is that explainable AI focuses on making the decision-making process of AI models transparent and interpretable for humans, while AI, in general, encompasses a broader range of machine learning and problem-solving techniques.
A. Explainable AI for question answering involves AI models that can provide both answers and transparent explanations for how they arrived at those answers, helping users understand the reasoning behind the responses.
A. The methodology of explainable AI often involves techniques such as feature importance analysis, partial dependence plots, and model-agnostic methods like LIME and SHAP. These methods aim to elucidate how AI models make decisions while maintaining transparency and interpretability.
The media shown in this article are not owned by Analytics Vidhya and is used at the Author’s discretion.
Lorem ipsum dolor sit amet, consectetur adipiscing elit,







