This article was published as a part of the Data Science Blogathon.
In any Data Science project, the steps of Importing Data followed by Data Cleaning and Exploratory Data Analysis(EDA) are extremely important.
Let us say we have the required dataset in a CSV file, but the dataset is stored across multiple files, instead of a single file. We would ideally like to read in the data from multiple files into a single pandas DataFrame for use in subsequent steps. The most straightforward way to do it is to read in the data from each of those files into separate DataFrames and then concatenate them suitably into a single large DataFrame.
This can be memory inefficient and involves writing redundant code. So, is there a better way to do it? Yes, there is. In this blog post, let us try to understand through simple examples.
Let us import pandas under its usual alias pd.
import pandas as pd
Build DataFrame from multiple files (row-wise)
We shall use a sample dataset for our example; let us read the data from http://bit.ly/smallstocks into a DataFrame stocks using the read_csv() method of pandas.
import pandas as pd
stocks = pd.read_csv('stocks.csv', parse_dates=['Date'])
print(stocks)
Let us say, this data was stored in 3 separate CSV files, one for each day, named stocks1.csv, stocks2.csv and stocks3.csv as shown below.
stocks1 = pd.read_csv('data/stocks1.csv')
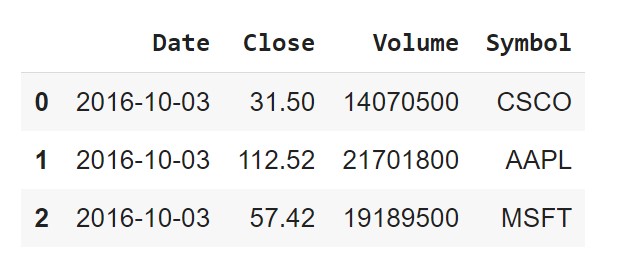
stocks2 = pd.read_csv('data/stocks2.csv')
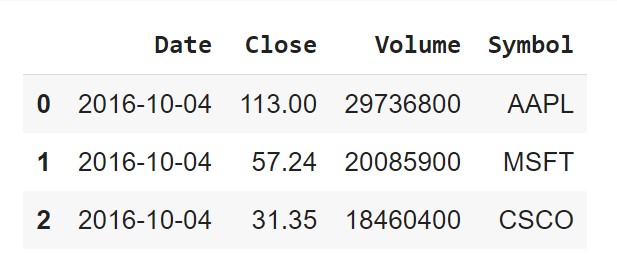
stocks3 = pd.read_csv('data/stocks3.csv')
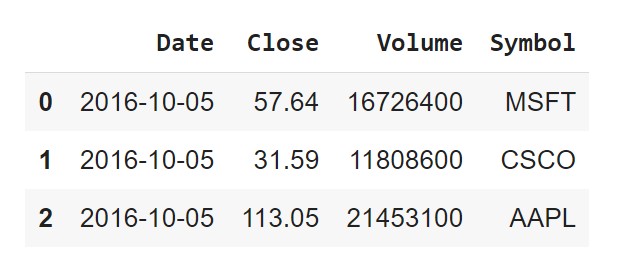
As said earlier, a naive approach would be to read in each of these CSV files into separate DataFrames, as shown above, and then concatenate them, but this would become cumbersome as the number of such files increases. A better solution is to use the built-in glob module. Let us import glob.
We can pass in a pattern to glob(), including wildcard characters, and it will return a list of all files that match that pattern.
stock_files = sorted(glob('data/stocks*.csv'))
In this case, glob is looking in the “data” subdirectory for all CSV files that start with the word “stocks” . glob returns filenames in an arbitrary order, which is why we have sorted the list using Python’s built-in sorted() method.
Now that we’ve collected all the files over which our dataset is spread across, we can use a generator expression to read in each of the files using read_csv() and pass the results to the concat() function, which will concatenate the rows into a single DataFrame.
pd.concat((pd.read_csv(file) for file in stock_files))
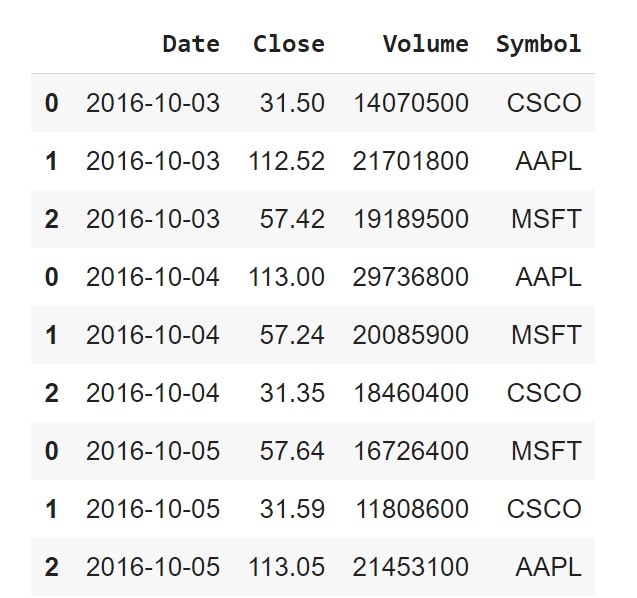
Looks like we’ve successfully accomplished bringing in all data from the three files into a single DataFrame, but, there are duplicate values in the index. To avoid that, we can set the ignore_index argument to True to tell the concat() function to ignore the index and use the default integer index instead.
pd.concat((pd.read_csv(file) for file in stock_files), ignore_index=True)
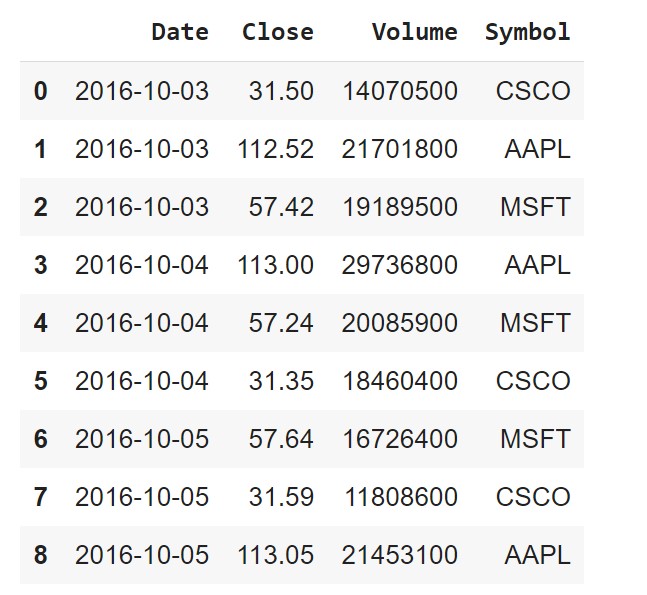
This method is useful when each file contains rows from our dataset.
But what if each file instead contains columns from our dataset?
Build DataFrame from multiple files (column-wise)
Here’s an example, in which the drinks the dataset has been split into two CSV files, and each file contains three columns.
drinks = pd.read_csv('http://bit.ly/drinksbycountry')
Here’s an example in which the drinks dataset has been split into two CSV files, and each of the files drinks1.csv and drinks2.csv contain three columns.
drinks1 = pd.read_csv('data/drinks1.csv').head()
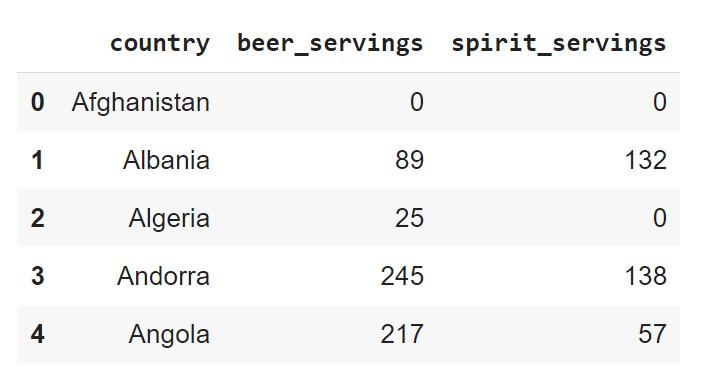
drinks2 = pd.read_csv('data/drinks2.csv').head()

Similar to the procedure we followed earlier, we’ll start by using glob()
drink_files = sorted(glob('data/drinks*.csv'))
And this time, we’ll tell the concat() function to concatenate along with the columns by specifying the axis argument as ‘columns’.
pd.concat((pd.read_csv(file) for file in drink_files), axis='columns').head()
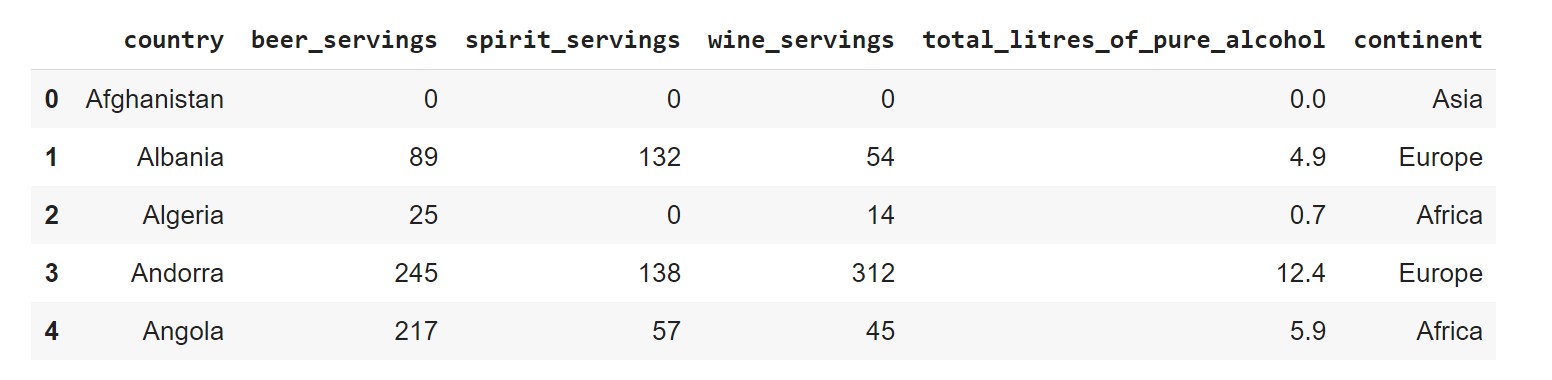
We see that we’ve obtained a single DataFrame with all six columns. We had considered simple examples to illustrate the use. In practice, where we have datasets chunked across multiple files, this could be a lot more helpful.
Thank you for reading!
References
- https://docs.python.org/3/library/glob.html
- https://github.com/justmarkham/pandas-videos/blob/master/top_25_pandas_tricks.ipynb
- https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.read_csv.html
The media shown in this article are not owned by Analytics Vidhya and is used at the Author’s discretion.







This is great article. Very easy to follow. Please also include this: 1. Create a file wise index level to the final dataframe, if one wants to merge all into one dataframe but still wants to know which data is from which file. For this, keep this as the level 0 index and the level 1 can be the reset index as mentioned in the above article. 2. Include conversion of multiple columns as datetime along with mentioning specific dtypes for particular columns. 3. Include examples with NaN values in the column. 4. Include dealing with multi-dtype columns. If you write a tutorial article with that heading, one should include all relevant matters about it.