Reinforcement Learning, seems intriguing, right? Here in this article, we will see what it is and why is it so much talked about these days. This acts as a guide to learn the fundamentals of reinforcement learning for beginners. Reinforcement Learning is definitely one of the evident research areas at present which has a good boom to emerge in the coming future and its popularity is increasing day by day. Lets, get it started.
It is basically the concept where machines can teach themselves depending upon the results of their own actions. Without further delay, let’s start this tutorial.
This article was published as a part of the Data Science Blogathon.
Reinforcement Learning is a part of machine learning. Here, agents are self-trained on reward and punishment mechanisms. It’s about taking the best possible action or path to gain maximum rewards and minimum punishment through observations in a specific situation. It acts as a signal to positive and negative behaviors. Essentially an agent (or several) is built that can perceive and interpret the environment in which is placed, furthermore, it can take actions and interact with it.
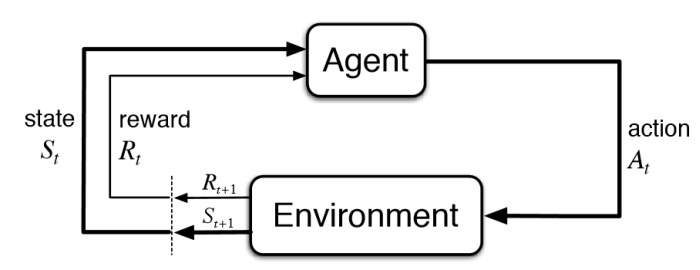
To know the meaning of reinforcement learning, let’s go through the formal definition.
Reinforcement learning, a type of machine learning, in which agents take actions in an environment aimed at maximizing their cumulative rewards – NVIDIA
Reinforcement learning (RL) is based on rewarding desired behaviors or punishing undesired ones. Instead of one input producing one output, the algorithm produces a variety of outputs and is trained to select the right one based on certain variables – Gartner
It is a type of machine learning technique where a computer agent learns to perform a task through repeated trial and error interactions with a dynamic environment. This learning approach enables the agent to make a series of decisions that maximize a reward metric for the task without human intervention and without being explicitly programmed to achieve the task – Mathworks
The above definitions are technically provided by experts in that field however for someone who is starting with reinforcement learning, but these definitions might feel a little bit difficult. As this is a reinforcement learning guide for beginners, let’s create our reinforcement learning definition in an easier way.
Through a series of Trial and Error methods, an agent keeps learning continuously in an interactive environment from its own actions and experiences. The only goal of it is to find a suitable action model which would increase the total cumulative reward of the agent. It learns via interaction and feedback.
Well, that’s the definition of reinforcement learning. Now how we come to this definition, how a machine learns and how it can solve complex problems in the world through reinforcement learning, is something we are going to see further.
The state represents the current situation of the agent in the environment. It can be a simple representation (e.g., robot’s location on a grid) or a more complex one (e.g., all objects and their positions in a room). The agent needs to understand the current state to make informed decisions about its actions.
Based on its current policy (essentially a strategy for choosing actions), the agent selects an action to perform in the environment. This action could be anything from moving to a new location to manipulating an object. The policy can be random initially, but the goal is to learn and improve it over time.
The environment provides feedback to the agent in the form of a reward signal. This reward can be positive (for achieving a desired outcome) or negative (for making a mistake). In some cases, there might be no reward (neutral), indicating the action didn’t bring the agent closer to its goal. This reward signal is crucial for the agent to learn the consequences of its actions.
After taking the action, the environment transitions to a new state. This new state reflects the outcome of the action. The agent observes this new state, which becomes its starting point for the next decision cycle.
This is the heart of the learning process. Based on the reward received, the agent updates its policy to favor actions that lead to higher rewards in the long run. Various algorithms exist for updating the policy, but they all aim to learn from past experiences and improve future decision-making.
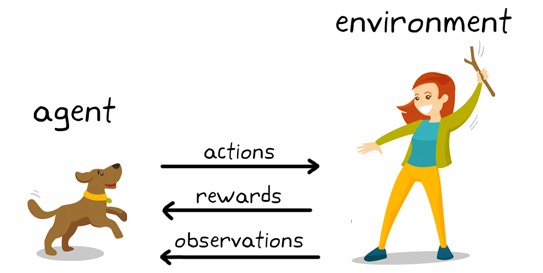
By exploring the environment and trying different actions, the agent gradually learns the best course of action for different situations. These learned behaviors are like a set of guidelines, or a policy, that helps the agent choose its next action. The goal is to maximize its total reward over time. However, the agent faces a dilemma: should it keep exploring new possibilities to discover potentially even better rewards, or should it stick with actions that have already proven successful? This is known as the exploration-exploitation trade-off.
You can see a dog and a master. Let’s imagine you are training your dog to get the stick. Each time the dog gets a stick successfully, you offered him a feast (a bone let’s say). Eventually, the dog understands the pattern, that whenever the master throws a stick, it should get it as early as it can to gain a reward (a bone) from a master in a lesser time.
In supervised learning, the model is trained with a training dataset that has a correct answer key. The decision is done on the initial input given as it has all the data that’s required to train the machine. The decisions are independent of each other so each decision is represented through a label.
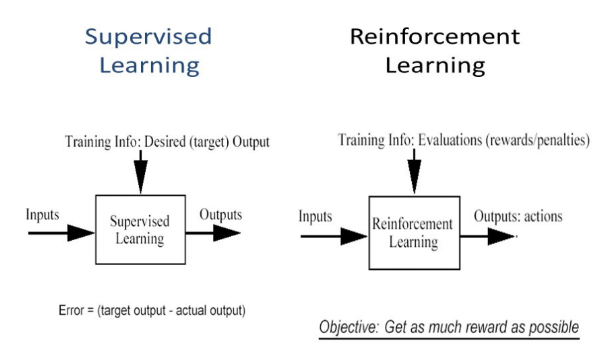
The world of reinforcement learning (RL) offers a diverse toolbox of algorithms. Some popular examples include Q-learning, policy gradient methods, and Monte Carlo methods, along with temporal difference learning. Deep RL takes things a step further by incorporating powerful deep neural networks into the RL framework. One such deep RL algorithm is Trust Region Policy Optimization (TRPO).
However, despite their variety, all these algorithms can be neatly categorized into two main groups:
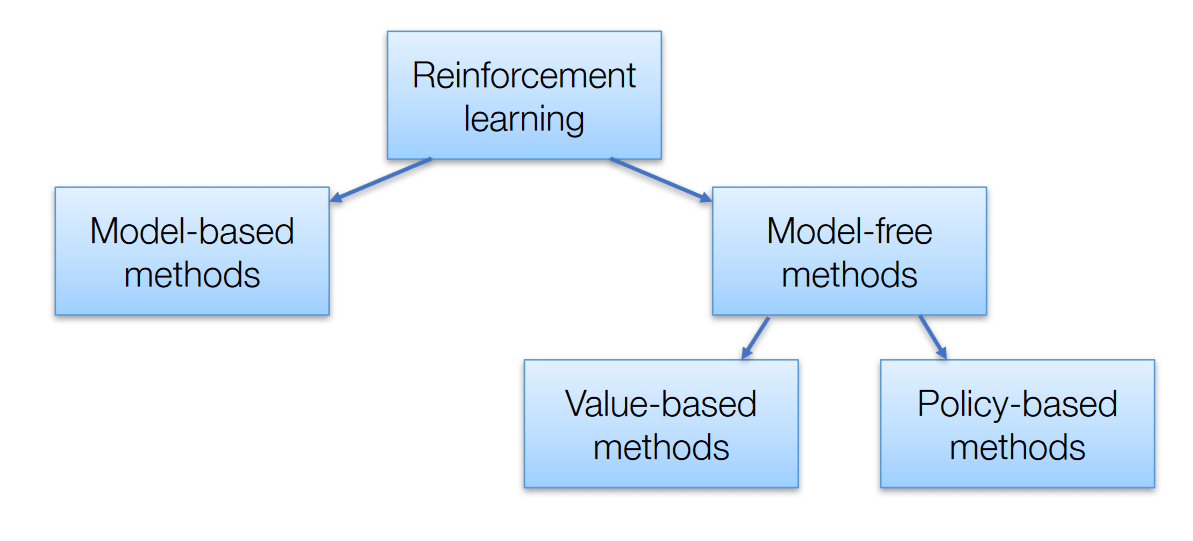
The choice of approach depends on several factors, including:
There are two types :
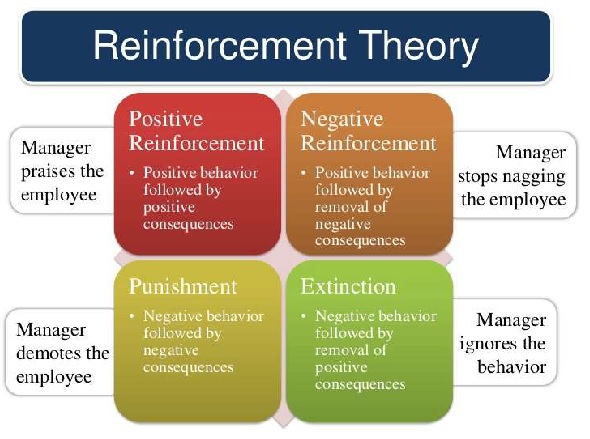
Positive reinforcement is defined as when an event, occurs due to specific behavior, increases the strength and frequency of the behavior. It has a positive impact on behavior.
Advantages
Disadvantage
Negative Reinforcement is represented as the strengthening of a behavior. In other ways, when a negative condition is barred or avoided, it tries to stop this action in the future.
Reinforcement learning (RL) tackles problems where an agent interacts with an environment, learning through trial and error to maximize rewards. Two main categories of models are used:
Markov Decision Process (MDP’s) are mathematical frameworks for mapping solutions in RL. The set of parameters that include Set of finite states – S, Set of possible Actions in each state – A, Reward – R, Model – T, Policy – π. The outcome of deploying an action to a state doesn’t depend on previous actions or states but on current action and state.
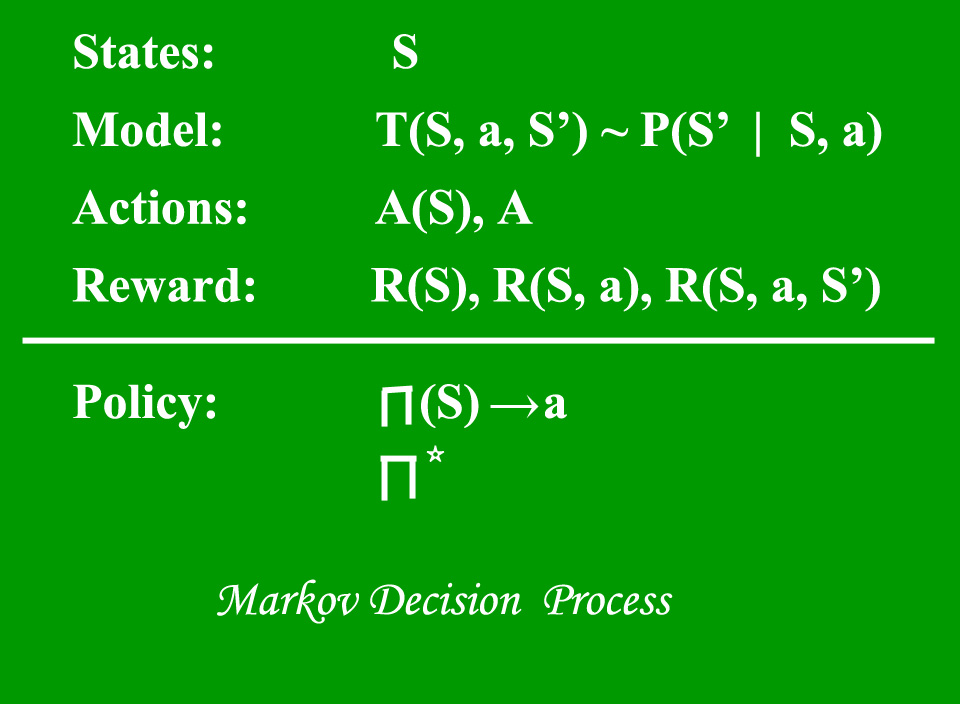
It’s a value-based model free approach for supplying information to intimate which action an agent should perform. It revolves around the notion of updating Q values which shows the value of doing action A in state S. Value update rule is the main aspect of the Q-learning algorithm.
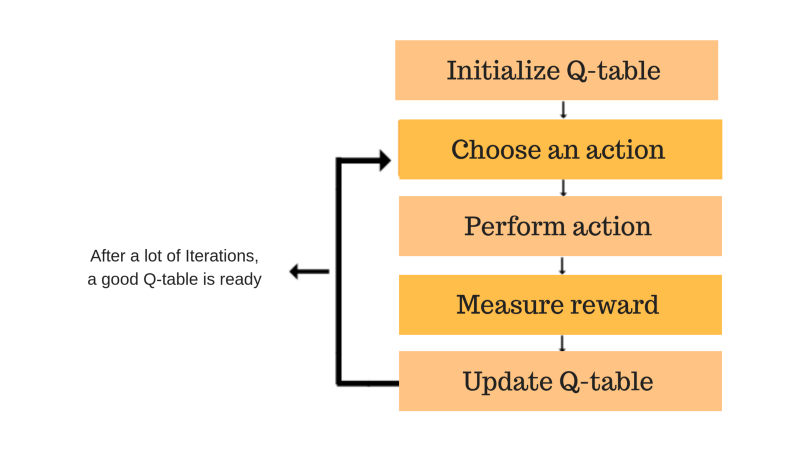
Similar to Q-Learning but focuses on learning the value of the specific action taken in the current state, considering the next state reached. This can be computationally more efficient than Q-Learning in some cases.
These models often use techniques like Monte Carlo methods to estimate the value of states or state-action pairs. Monte Carlo methods involve simulating multiple playthroughs of the environment to gather reward information and update the agent’s policy accordingly.
Reinforcement learning guides us in determining actions that maximize long-term rewards. However, it may struggle in partially observable or non-stationary environments. Moreover, its effectiveness diminishes when ample supervised learning data is available. A key challenge lies in managing parameters to optimize learning speed.
Hope now you got the feel and certain level of the description on Reinforcement Learning. Thanks for your time.
1. To solve complex problems in uncertain environments
2. To enable agents to learn from their own experiences
3. To develop agents that can adapt to new situations.
An example of reinforcement learning is teaching a computer program to play a video game. The program learns by trying different actions, receiving points for good moves and losing points for mistakes. Over time, it learns the best strategies to maximize its score and improve its performance in the game.
Reinforcement learning is a method of machine learning where an agent learns to make decisions by interacting with an environment. It receives feedback in the form of rewards or penalties based on its actions, allowing it to learn the optimal behavior to achieve its goals over time.
There are two types of reinforcement learning:
Model-Based: The agent learns about the environment and uses that knowledge to plan its actions.
Model-Free: The agent learns from experience without needing to understand the environment in detail.
– On-policy learning: The agent learns and improves the same policy it’s currently using to take actions. Imagine an agent learning to navigate a maze. On-policy learning refines its path based on the choices it’s already making (exploration and some successful moves).
– Off-policy learning: The agent learns a policy different from the one it’s currently using. This could be based on pre-collected data or a separate exploration policy. Think of an agent learning from a maze map (pre-collected data) while still exploring the maze itself (different policy).
The media shown in this article are not owned by Analytics Vidhya and are used at the Author’s discretion.
Lorem ipsum dolor sit amet, consectetur adipiscing elit,







