This article was published as a part of the Data Science Blogathon.
Pre-requisites
- Understanding of Machine Learning using Python (sklearn)
- Basics of Django
- Basics of HTML,CSS
In this article, you will learn Machine Learning (ML) model deployment using Django. We will also discuss the ML Problem Statement which is HR Analytics.
I have taken this problem from Analytics Vidhya. A special thank you to them for providing such amazing problem statements.
Now before we start, take a look at this website-HR Analytics. This is what we are going to make. I have deployed the website on Heroku.
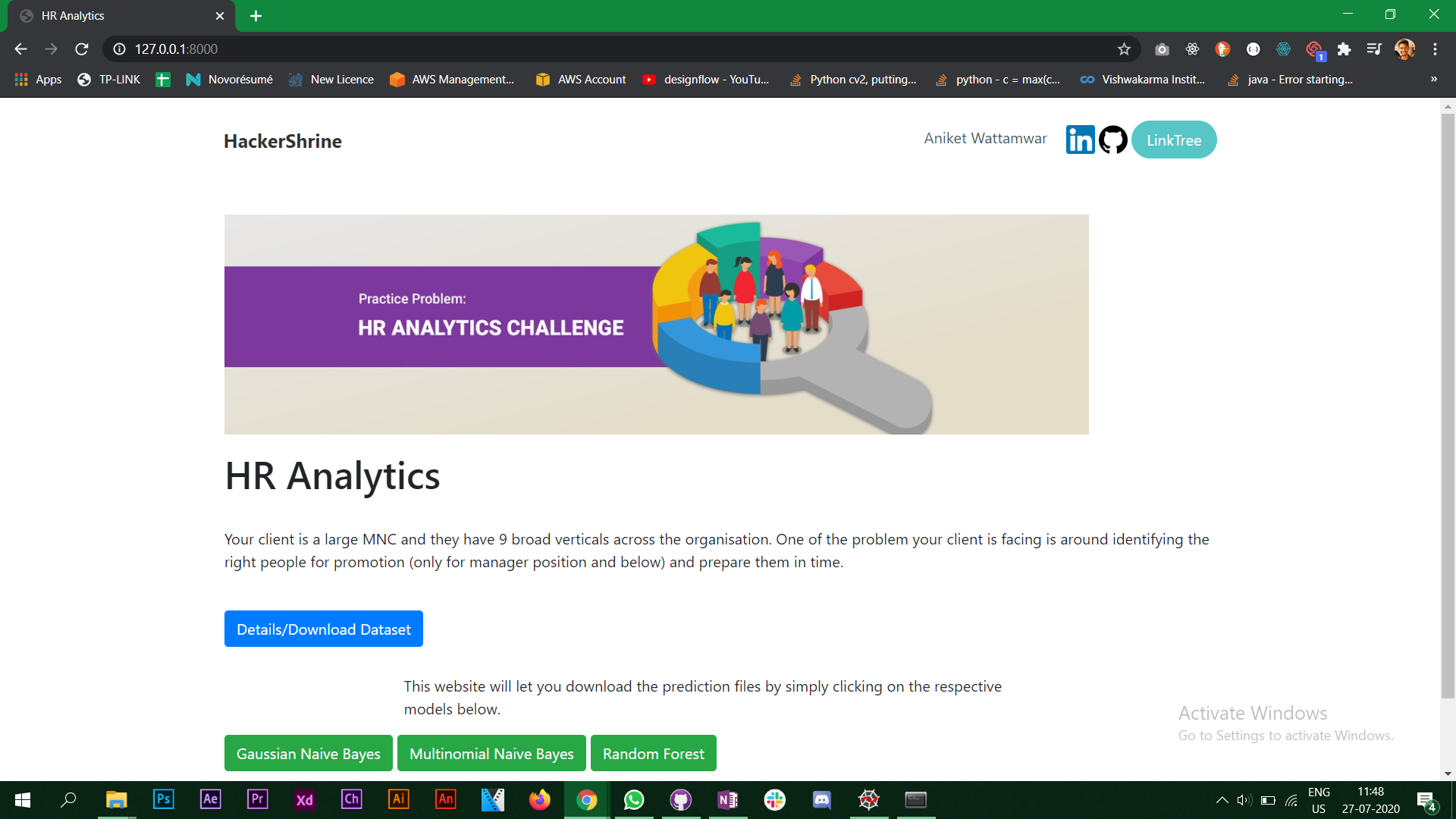
Let’s understand what the website does. You will see three buttons with the model name. When you click on any one of the buttons it is going to download a prediction file of that particular model. To do this we are using Django. Also, make sure the headings of that .csv file are what you see in the sample submission file that you have downloaded.
1.) ML code
First, let’s understand the ML code. We import the libraries first
import pandas as pd import matplotlib.pyplot as plt import numpy as np import seaborn as sns import pickle
Import the data that we downloaded and combine our train and test data. So we can do the pre-processing on the entire data directly. Copy the output column in another variable and then drop that column from the data.
import pandas as pd
train_data = pd.read_csv('train_.csv')
test_data = pd.read_csv('test_.csv')
data = train_data.append(test_data, ignore_index=True)
y = data['is_promoted']
data = data.drop(['is_promoted'],axis = 1)
print(data)Now we do pre-processing on the entire data. Look at the below code.
dept_counts = data['department'].value_counts()
region_count = data['region'].value_counts()
region_data = data['region'].str.replace("[a-zA-Z_]","")
data['region']= data['region'].str.replace("[a-zA-Z_]","")
region = data['region'].astype(int)
region = region.astype(int)
data = pd.get_dummies(data, columns=['gender']) data = data.drop(['gender_f'],axis = 1) data = pd.get_dummies(data, columns=['education']) data = data.drop(['education_Below Secondary'],axis = 1) data = pd.get_dummies(data, columns=['recruitment_channel']) data = data.drop(['recruitment_channel_referred'],axis = 1)
from sklearn.preprocessing import LabelBinarizer lb_style = LabelBinarizer() lb = lb_style.fit_transform(data["department"]) data['previous_year_rating'] = data['previous_year_rating'].fillna(data['previous_year_rating'].median()) data = data.drop(['department'],axis = 1) d1 =data.insert(1,'Region',region) data = data.drop(['region'],axis = 1) d = data count_ofall_nan = data.isna().sum() X= data.iloc[:,0:14].values X= np.hstack((X,lb)) count_ = np.isnan(np.sum(lb)) data = data.astype(np.int64)
If you have worked a little on solving machine learning problems you will understand the pre-processing part easily. Basically what we are doing is converting our categorical variables into numeric values and filling our nan values with either median or mean. Here I have replaced them with a median. Pandas have a function of get_dummies that does the encoding part for us. We also have the labelbinarizer from sklearn. I have done some basic pre-processing here you need to study the dataset properly and can use better techniques to increase your accuracy.
Now that we are done with pre-processing let’s divide our dataset back to our train and test data. Also, add the output column back into the training variable since we will be needing it for the model to learn. Save the test data into a .csv file. To do this…
#divide into train and test
train = X[:length of train data,:]
test = X[length of train data:,:]
test.to_csv('test_preprocessed.csv')
Next, we use different models and fit them into our training data. Here, I am just using 3 models, you can try different models and tune them that will give you maximum accuracy. Now we need to save the model since we are going to predict the output using Django from our website. To save the model, I am using pickle and then with the dump function, saving the model.
from sklearn.naive_bayes import GaussianNB
nb = GaussianNB()
nb.fit(X, y)
pickle.dump(nb, open('gNB.sav','wb'))
#random forest classifier
from sklearn.ensemble import RandomForestClassifier
random = RandomForestClassifier(n_estimators=100)
random.fit(X,y)
pickle.dump(random, open('random_forest.sav','wb'))
from sklearn.naive_bayes import MultinomialNB
classifier_multi = MultinomialNB()
classifier_multi.fit(X, y)
pickle.dump(classifier_multi, open('classifier_multi_NB.sav','wb'))
2.) Django
Now we are ready with our models saved using pickle. Let’s get into Django to predict the values from the website. On the frontend, you will have three buttons in the form tag that are going to interact with Django. The form action is pointing to the link ‘download’, we will see that later. Below is only that part. The bold text is quite important.
<form action="download" method="POST">
{% csrf_token %}
<input type="submit" name="gNB" value="Gaussian Naive Bayes" class="btn btn-success">
<input type="submit" name="multiNB" value="Multinomial Naive Bayes" class="btn btn-success">
<input type="submit" name="rf" value="Random Forest" class="btn btn-success">
</form>
Next, go to your views.py file and first import the test data so that we can use it.
test_data_preprocessed = pd.read_csv('test_preprocessed.csv')
test_data_preprocessed = test_data_preprocessed.drop(['Unnamed: 0'],axis =1)
test_data_preprocessed = test_data_preprocessed.iloc[:,:].values
Create a function named home in the views.py file so that you can see the 3 buttons as well as all the other HTML content of your website.
def home(request): return render(request,"index.html")
In the urls.py file add the following..
urlpatterns = [
path('',views.home, name = 'home')
]
Now, we work on the functionality of the buttons. In the views.py file again, we will create a function named as models. In the HTML file above, we had named our buttons (bold text). Here, we are going to use those names to understand which one of the buttons was clicked by the user, and then it will predict values based on that model. See the below code.
def models(request):
if 'gNB' in request.POST:
gaussian = pickle.load(open('gNB.sav','rb'))
y_pred = gaussian.predict(test_data_preprocessed)
output = pd.DataFrame(y_pred)
output.to_csv('gaussianNB.csv')
filename = 'gaussianNB.csv'
response = HttpResponse(open(filename, 'rb').read(), content_type='text/csv')
response['Content-Length'] = os.path.getsize(filename)
response['Content-Disposition'] = 'attachment; filename=%s' % 'gaussianNB.csv'
return response
if 'multiNB' in request.POST:
multi = pickle.load(open('classifier_multi_NB.sav','rb'))
y_pred = multi.predict(test_data_preprocessed)
output = pd.DataFrame(y_pred)
output.to_csv('multi_NB.csv')
filename = 'multi_NB.csv'
response = HttpResponse(open(filename, 'rb').read(), content_type='text/csv')
response['Content-Length'] = os.path.getsize(filename)
response['Content-Disposition'] = 'attachment; filename=%s' % 'multi_NB.csv'
return response
if 'rf' in request.POST:
rf = pickle.load(open('random_forest.sav','rb'))
y_pred = rf.predict(test_data_preprocessed)
output = pd.DataFrame(y_pred)
output.to_csv('rf.csv')
filename = 'rf.csv'
response = HttpResponse(open(filename, 'rb').read(), content_type='text/csv')
response['Content-Length'] = os.path.getsize(filename)
response['Content-Disposition'] = 'attachment; filename=%s' % 'rf.csv'
return response
The If statement will check the button name then we load the test data that we imported earlier. After that, we use the predict function to predict the values. Convert it into a dataframe and then create a CSV file of it. But our main task was to download the file, so for that, we have in Django an HTTP response that will send the file to our browser for the user to download as an attachment. This is how you download the prediction files.
Lastly, we have to update our urls.py file also, since we have created a function called models. Add the following
urlpatterns = [
path('',views.home, name = 'home'),
path('download',views.models)
]
The download parameter is what we saw in the HTML page in the form tag. So when the user clicks on any one of the buttons this particular path is triggered which runs the function models in the views.py file.
That’s it !!!
You just ML model deployment on the website using Django.
You can find the entire code on my GitHub. I have also uploaded a video on YouTube.
Thank you!
The media shown in this article are not owned by Analytics Vidhya and are used at the Author’s discretion.






