This article was published as a part of the Data Science Blogathon.
Introduction
Hello Everyone for this practical Introduction to Machine Learning using Simple Linear Regression. So, let’s get started:
So, let’s get familiarised with the terms to be used:
Machine Learning (ML): ML is an application of Artificial Intelligence (AI) that provides systems the ability to automatically learn themselves and improve from the experience without being explicitly programmed. ML focuses on the development of computer programs that can access data and use it to self-learn.
Data Set: A collection of related sets of information that is composed of separate elements but can be manipulated as a unit by a computer.
Data Visualisation: It is a representation of data or information in a graph, chart, or other visual formats which is helpful to conduct analyses such as predictive analysis which can serve as helpful Visualisation to present.
Data Cleaning: It is the process of fixing or removing incorrect, corrupted, incorrectly formatted, duplicate, or incomplete data within a dataset.
Supervised Learning: The model is trained using ‘labeled data’. Datasets are said to contain labels that contain both input and output parameters. To simplify – ‘Data is already tagged with the correct answer’.
Simple Linear Regression: It is a Regression Model that estimates the relationship between the independent variable and the dependent variable using a straight line [y = mx + c], where both the variables should be quantitative.
Models: Those are output by algorithms and are comprised of model data and a prediction algorithm.
Training Model: In supervised learning, an ML Algorithm builds a model by examining many examples and attempting to find a model that minimizes loss and improves prediction accuracy.
These are the few terms used in this article and to get familiar with. Now let’s get started with the analysis and prediction of the model. In this tutorial, I am going to use supervised data and simple linear regression for analysis and prediction. The Ultimate goal is the predict the height of a person provides his age using the trained model to the highest achievable accuracy using available data. I have used the universal favorite programming language for ML i.e. Python to build and train the ML model and Google Colab Environment.
Table of contents
1. Importing Data Set:
The first and foremost thing we need to do is import the dataset. We have various websites which have these datasets to be used by anyone. So similarly let’s get started on how to import the data set that we are going to use in this tutorial.

This single line of code helps us fetch the data used for the tutorial from the URL directly.
Dataset <- Click the link to fetch the dataset which is the above-mentioned URL.
2. Visualising the Data:
In this step after importing the data and mounting it with Colab let’s have an overview of the dataset by importing a Module called pandas. Since the dataset we have has an extension of .pkl we just view it by the function available in the pandas library.
We import the library to read the dataset and store it in a variable called raw_data. We then display the content of raw_data which is in a tabulated format.
import pandas as pd
raw_data = pd.read_pickle('AgesAndHeights.pkl')
print(raw_data.head())We can see the data which we have and it contains only 2 columns namely, Age (in years) and Height (in inches) and 100 rows which is actually the representation of a person.
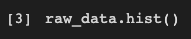
This single line of code has a great impact on the way we look at the dataset. We only had a numerical view of the dataset but we can now run this cell to get a histogram view of the dataset which is very helpful. It represents the data present in the individual columns as individual graphs.
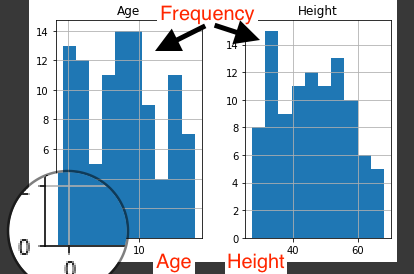
The Y-axis in both the plots refers to frequency and X-axis represents Age and Height respectively.
3. Data Cleaning:
We have to build the model using valid datasets and clean the unaccountable Data. In the above image, we can know that there are a few entries that have an age less than zero which is meaningless. Hence, we need to clean those data to get better accuracy.

I use variable cleaned_data to store the valid age values and display them to the user.
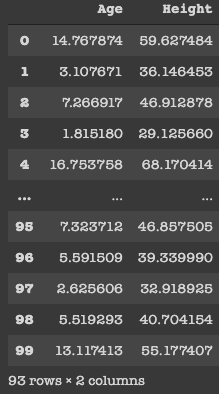
Initially, we had 100 rows but after performing Data Cleaning it’s pretty clear that there are seven rows which we had age < 0 and we have removed them. As a professional, we aren’t supposed to delete the data as we are reducing the data and thereby accuracy of our model gets reduced. To keep it simple I have just removed them.
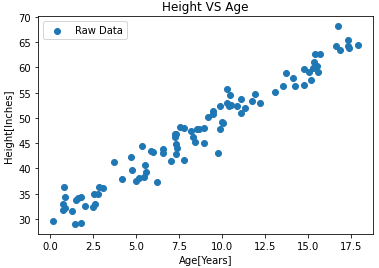
Visualize the Cleaned Data: I have now used the cleaned data and visualized it in the form of a graph.
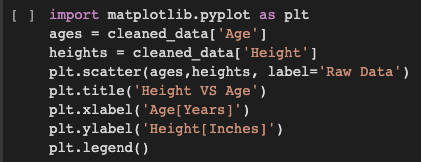
To plot graphs in python I import matplotlib.pyplot library. I represent Age on X-axis and Height on Y-axis. The points in the plot refer to the Raw data.
4. Build the Model and Train it:
This is where the ML Algorithm i.e. Simple Linear Regression comes into play.
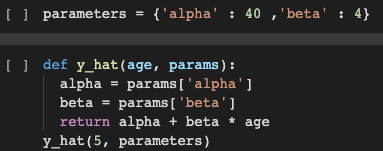
I used a dictionary named parameters which has alpha and beta as key with 40 and 4 as values respectively. I have also defined a function y_hat which takes age, and params as parameters. This function uses the basic straight-line equation and returns y i.e. height as in our case. If we pass the required parameters and run the function, we find that the height we get for the age as input is not matched. Hence, we use the function mentioned below to rain the model.
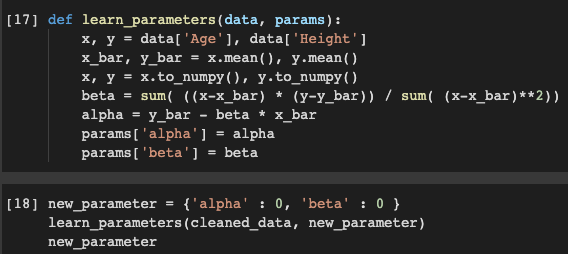
This is where we use a method to find the correct alpha and beta. The function learn_parameters takes cleaned_data and a dummy dictionary new_parameter which can have any value for alpha and beta. So, when we pass them as arguments to parameters and function runs and we can get the correct value of alpha and beta which is found to close to 30 and 2 respectively and replace the old values with the new ones.
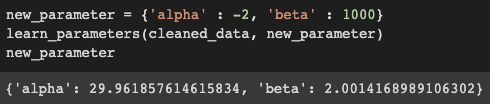
We have accurately found the values of alpha and beta, and our next goal is to train the data. But let me the untrained predicted values to what extent they are accurate.

I use a list named spaces_ages that has values from 0 to 18 (end – 1). Then another list named spaced_untrained_predictions that has the predicted values for the height uses the y_hat function defined earlier to predict it. These values are plotted in a graph and visualized.
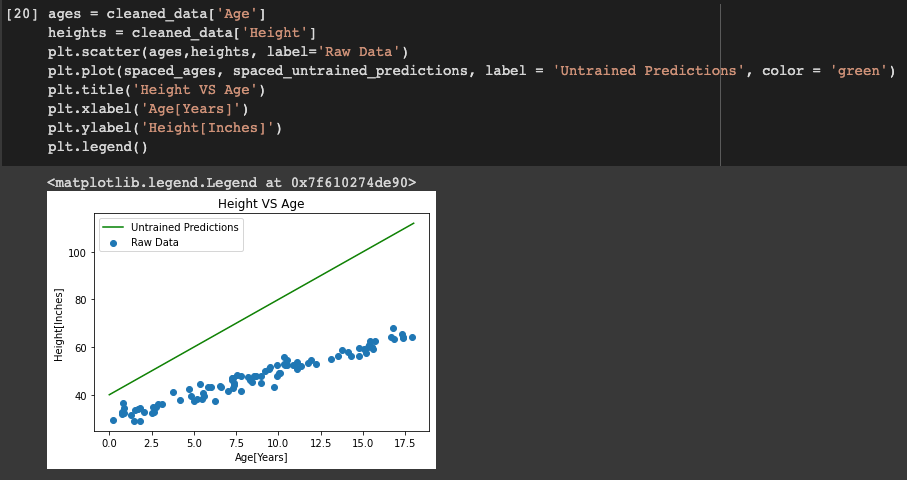
The green line shows that the spaced_untrained_predictions have largely deviated from the actual values and the accuracy is very poor. Hence, accuracy needs to be increased for which we need to train the data.

So instead of using parameters, we use new_parameters as it contains the accurate value of alpha and beta and stores it in a list named spaced_trained_predictions. So, when we plot a graph for this, we can see a visible difference and the accuracy has increased a lot. Therefore, we have successfully built and trained the model. Proof for that is the values of spaced_trained_predictions and the graph.
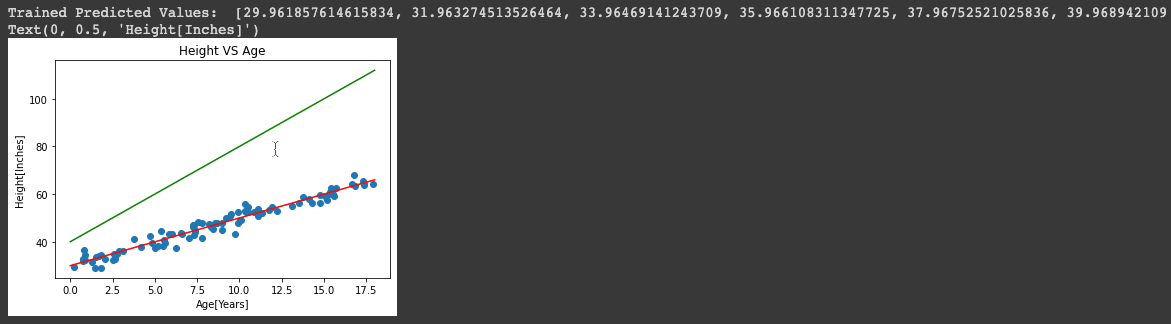
The Greenline refers to the values of spaced_untrained_predictions and Redline refers to the values of spaced_trained_predictions.
5. Make Predictions on Unseen Data:
With the help of this trained model, we can now make accurate predictions.

So, we can see for any given age we find the possible height in inches. Finally, we have successfully trained the model and with utmost accuracy which is the ultimate goal of this tutorial.
Conclusion
In summary, this hands-on guide to Simple Linear Regression with Python walks you through crucial steps: importing data, visualizing it, cleaning, building, training the model, and making predictions. Mastering these basics will boost your ability to analyze data effectively. Ready to enhance your skills
For reference, I have pasted the Link to Notebook you play around with it. Hope to get connected through LinkedIn as well and share your valuable feedback. Stay tuned for more blogs of this kind😊 .
Frequently Asked Questions
Q1.What is the formula for linear regression in Python?
The formula is y=mx+b, and in Python, use scikit-learn’s LinearRegression class.
Q2.What are the Steps in Simple Linear Regression:
1.Import Libraries:
Use numpy, matplotlib, and scikit-learn.
2.Prepare Data:
Create or load the dataset with X and Y variables.
3.Split Data:
Divide into training and testing sets with train_test_split.
4.Train Model:
Create and train the model using LinearRegression.
5.Make Predictions:
Predict values for test data.
6.Evaluate Model:
Assess performance by comparing predicted and actual values, often with a plot.
7.Use for Predictions:
Apply the model to predict Y values for new X values.
The media shown in this article are not owned by Analytics Vidhya and is used at the Author’s discretion.
A seasoned software and ML developer with likes to share knowledge on the latest skills, frameworks, and technologies. Writes about Data Science and Machine learning and love to build and ship projects.







can you please explain me the Analyse the performance of the model for AgesAndHeights.pkl