This article was published as a part of the Data Science Blogathon.
Introduction
Quite often, we use data verification and data validation interchangeably when we talk about data quality. However, these two terms are distinct. In this article, we will understand the difference in 4 different context –
- Dictionary meaning of verification and validation
- Difference between data verification and data validation in general
- Difference between verification and validation from a software development perspective
- Difference between data verification and data validation from a machine learning perspective
1) Dictionary meaning of verification and validation
Table 1 explains the dictionary meaning of the words verification and validation with a few examples.

To summarize, verification is about truth and accuracy, while validation is about supporting the strength of a point of view or the correctness of a claim. Validation checks the correctness of a methodology while verification checks the accuracy of the results.
2) Difference between data verification and data validation in general
Now that we understand the literal meaning of the two words, let’s explore the difference between “data verification” and “data validation”.
Data verification: to make sure that the data is accurate.
Data validation: to make sure that the data is correct.
Let us elaborate with examples in Table 2.

Table 2: “Data verification” and “data validation” examples
3) Difference between verification and validation from a software development perspective
From a software development perspective,
- Verification is done to ensure the software is of high quality, well-engineered, robust, and error-free without getting into its usability.
- Validation is done to ensure software usability and capacity to fulfill the customer needs.
As shown in Fig 1, proof of correctness, robustness analysis, unit tests, integration tests, and others are all verification steps where tasks are oriented to verify specifics. The software output is verified against desired output. On the other hand, model inspection, black box testing, usability testing are all validation steps where tasks are oriented to understand if the software meets the requirements and expectations.
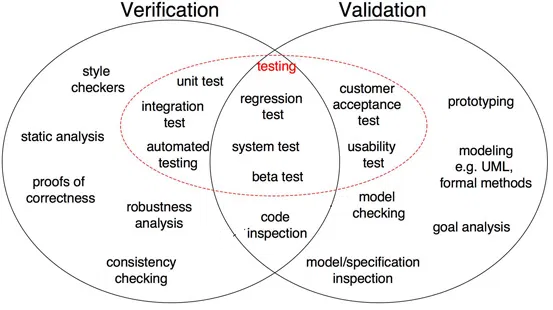
Fig 1: Differences between Verification and Validation in software development
4) Difference between data verification and data validation from a machine learning perspective
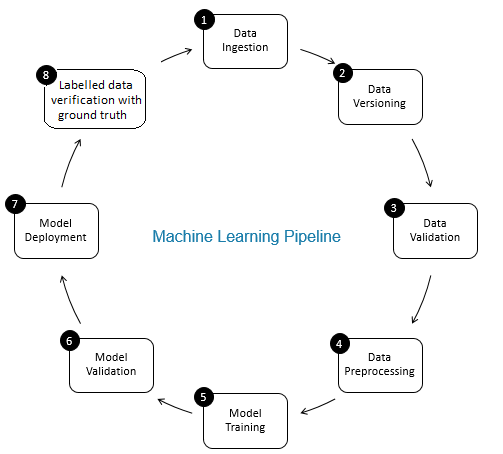
The role of data verification in the machine learning pipeline is that of a gatekeeper. It ensures accurate and updated data over time. Data verification is made primarily at the new data acquisition stage i.e. at step 8 of the ML pipeline, as shown in Fig. 2. Examples of this step are to identify duplicate records and perform deduplication, and to clean mismatch in customer information in fields like address or phone number.
On the other hand, data validation (at step 3 of the ML pipeline) ensures that the incremental data from step 8 that is added to the learning data is of good quality and similar (from a statistical properties perspective) to the existing training data. For example, this includes finding data anomalies or detecting differences between existing training data and new data to be added to the training data. Otherwise, any data quality issue/statistical differences in incremental data may be missed and training errors may accumulate over time and deteriorate model accuracy. Thus, data validation detects significant changes (if any) in incremental training data at an early stage that helps with root cause analysis.
Authors:
1. Aditya Agarwal: Aditya Aggarwal serves as Data Science – Practice Lead at Abzooba Inc. With more than 12+ years of experience in driving business goals through data-driven solutions, Aditya specializes in predictive analytics, machine learning, business intelligence & business strategy across a range of industries. As the Advanced Analytics Practice Lead at Abzooba, Aditya leads a team of 50+ energetic data science professionals at Abzooba that are solving interesting business problems using machine learning, deep learning, Natural Language Processing, and computer vision. He provides thought leadership in AI to clients to translate their business objectives into analytical problems and data-driven solutions. Under his leadership, several organizations have automated routine tasks, reduced operational cost, boosted team productivity, and improved top-line and bottom-line revenues. He has built solutions such as subrogation engine, price recommendation engine, IoT sensor predictive maintenance, and more. Aditya holds a Bachelor of Technology and Minor Degree in Business Management from the Indian Institute of Technology (IIT), Delhi.
2. Dr. Arnab Bose: Dr. Arnab Bose is Chief Scientific Officer at Abzooba, a data analytics company, and an adjunct faculty at the University of Chicago where he teaches Machine Learning and Predictive Analytics, Machine Learning Operations, Time Series Analysis, and Forecasting, and Health Analytics in the Master of Science in Analytics program. He is a 20-year predictive analytics industry veteran who enjoys using unstructured and structured data to forecast and influence behavioral outcomes in healthcare, retail, finance, and transportation. His current focus areas include health risk stratification and chronic disease management using machine learning, and production deployment and monitoring of machine learning models. Arnab has published book chapters and refereed papers in numerous Institute of Electrical and Electronics Engineers (IEEE) conferences & journals. He has received Best Presentation at American Control Conference and has given talks on data analytics at universities and companies in the US, Australia, and India. Arnab holds MS and Ph.D. degrees in electrical engineering from the University of Southern California, and a B.Tech. in electrical engineering from the Indian Institute of Technology at Kharagpur, India.
The media shown in this article are not owned by Analytics Vidhya and is used at the Author’s discretion.







This Blog is very Informative. Thanks for Sharing.
This is a nice blog about Data Validation and Data Verification, where data validation checks that the data is correct, while data verification checks to see if it is accurate. Thank you for sharing.