This article was published as a part of the Data Science Blogathon.
Note:
We split our data into two parts before building a machine learning model, one for training the model i.e., “Training Data” and another one for monitoring the model’s accuracy on unknown data i.e., “Testing Data”.
What are Bias and Variance?
1. Bias:
The overall error associated with “Training Data” is termed as bias. When the training data error increase, or training data accuracy decrease, it is referred to as high bias and when the training data error decreases or training data accuracy increases, it is referred to as low bias
High Bias: High training data error / low training data accuracy.
Low Bias: Low training data error / high training data accuracy.
2. Variance:
Note that variance is associated with “Testing Data” while bias is associated with “Training Data.” The overall error associated with testing data is termed a variance. When the errors associated with testing data increase, it is referred to as high variance, and vice versa for low variance.
High Variance: High testing data error / low testing data accuracy.
Low Variance: Low testing data error / high testing data accuracy.
Real-world example:
Consider the case of a student named ‘Shivam’ who is studying for the IIT entrance exam. Shivam enrolls in a coaching program to achieve his goal of being accepted into one of the IITs. This coaching has been working with Shivam for the past two years. In this coaching, Shivam will take multiple practice exams to assess his readiness. This is the ‘training data’ for Shivam. Finally, after two years of study, Shivam will sit for the JEE exam, which will serve as Shivam’s ‘testing data’. since it will assess Shivam’s output accuracy.
Assume that when taking the practice exams in the coaching, Shivam does exceptionally well. It’s regarded as having a low bias. Since the training accuracy is high and the training error is low. What if Shivam does badly on these coaching practice tests. Yeah…, you got it right; it is considered to have a high bias.
Let’s take a look at variance now because it is related to testing data. The final JEE exam serves as testing data for Shivam. Shivam will be either nervous or confident (depending upon the training) when he eventually appears for the JEE exam after 2 years of intensive preparation. Shivam is said to have gotten a high percentile on the test. This is a low-variance case. Since the testing accuracy is high and the testing error is low. It is a high variance if Shivam fails miserably in the JEE exam.
Bias Variance Trade-off
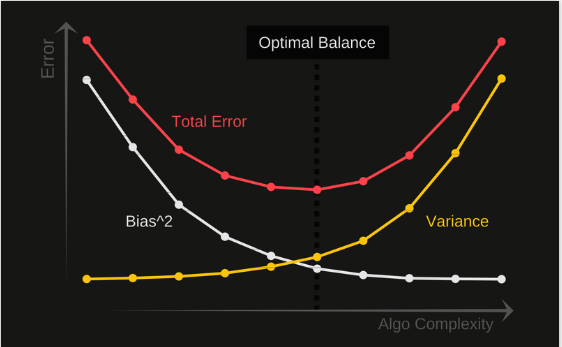
The relationship among bias, variance, and model error will be explored in this section of the article. In the following Figure, X-axis depicts the algorithm’s complexity or degree of the polynomial, while the Y-axis depicts the error provided by the model. The primary objective here is to reduce the error on the y-axis by balancing bias and variance.
The variance is represented by the yellow curve, and it is obvious that as the complexity of the algorithm or the degree of polynomial increases, the variance increases, causing the model error on the y-axis to increase exponentially. However, Bias in the white curve behaves differently: as the algorithm’s complexity increases on the x-axis, Bias^2 decreases exponentially, causing the model’s error on the y-axis to decrease.
Here, we’re supposed to find a sweet spot / optimal point where the error is low in terms of bias and variance. The overall error indicated by the yellow and white curves is depicted by the red curve. The optimum point on this red curve is the one with the lowest error value. This is exactly what we wanted.
Now that you’ve learned about bias and variation, you’re ready to move on. Let’s take a look at a few scenarios.
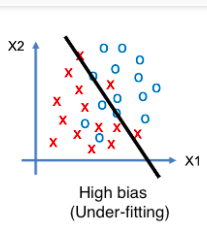
1) High Bias High Variance:
When the accuracy of both the training and testing data are poor, or when the error of both the training and testing data are high, ‘high variance’ is how it’s referred to. Terminology Alert!!!! The term “Under-fitting” is used to describe this situation. The state of under-fitting is depicted in the diagram below. As a result, it allows for a larger number of errors with the training data, resulting in a high bias state. This will result in a poor model that will be unable to perform well on new test data, resulting in a high variance scenario.
Real-World Example
Let’s use Shivam as an example once more. Let’s say Shivam has always struggled with HC Verma, OP Tondon, and R.D. Sharma. He did poorly in all of the training practice exams in coaching and then in the JEE exam as well. Since both the training and testing accuracy are poor in this situation, it is regarded as a high bias, high variance situation. (His mother is going to thrash him to death….and he is well aware of this. poor boy!!!)
Understand with Code
To understand this idea, we will use the K-Nearest Neighbour (KNN) algorithm in this section. We know that K is the hyperparameter that needs to be tuned.
Before you begin, there is something you must understand: –
When the k value is large, the condition is said to be under-fitting. As a consequence, the model will give poor accuracy on the training data.
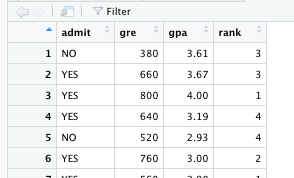
As shown in the following figure, we have used admission data with three independent variables (“gre”, “gpa”, and “rank”) and one dependent variable (“admit”).
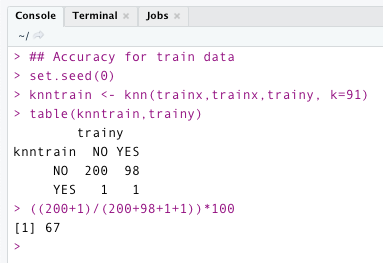
The following code is written in R. The code below illustrates the model’s accuracy on training data. I’ve chosen a very high value of k in this case (91). On training data, it has an accuracy of 67%. —–> High Bias
It is now time to assess the model’s accuracy using test data. The code below shows that the model has an accuracy of 71 % on testing data. – —> High variance.
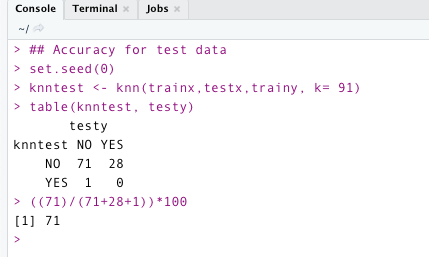
2) Low Bias High Variance:
when the accuracy of the training data is high and the accuracy of the testing data is poor It is referred to as a condition of low bias and high variance. Warning: Terminology!!! To describe this situation, the word “overfitting” is used.
The overfitting scenario is depicted in the diagram below. In this scenario, the model would collect all of the information about the training data, including unnecessary noise, resulting in high model accuracy for training data but failure for new testing data.
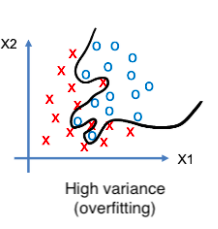
Real-World Example
Shivam appears once more to explain things to you. This is the case when Shivam had been doing well in all of the practice exams in the coaching but has performed badly in the JEE exam due to nerves or other factors.
Understand with Code
When k is low, it is considered an overfitting condition, which means that the algorithm will capture all information about the training data, including noise. As a result, the model will perform extremely well with training data but poorly with test data. In this example, we will use k=1 (overfitting) to classify the admit variable.
The following code evaluates the model’s accuracy for training data with (k = 1). We can see that the model not only captured the pattern in training but noise as well. It has an accuracy of more than 99 % in this case. —> low bias
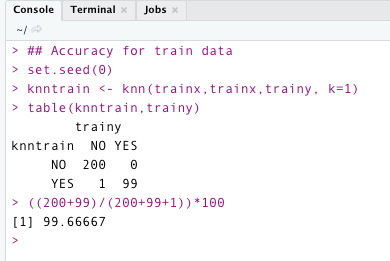
So, we’ve finished evaluating the accuracy of the training data. Let’s look for test data. It is clear from the code below that the model failed to provide good accuracy. It only provides an accuracy of 65% for test data. ——> high variance.
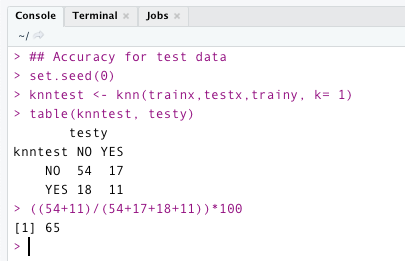
3) Low Bias Low Variance:
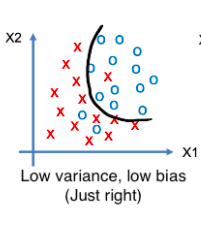
This is the best-case scenario. Both training and testing accuracies are high here. This is referred to as having low bias and low variance. This is the exact situation we would want. We will be able to achieve this case by training the model with hyperparameter tuning.
The following Figure represents the situation of low bias low variance. This model will not capture the noise present in the training data and will perform admirably well for both training and testing data with decent accuracy.
Real-World Example
Assume, Shivam excelled in all of the practice exams in the coaching, and when he finally took the JEE, he received a good percentile and was admitted to his dream IIT (Now his mother is happy and he will be able to eat his favorite meal tonight :)).
Understand with Code
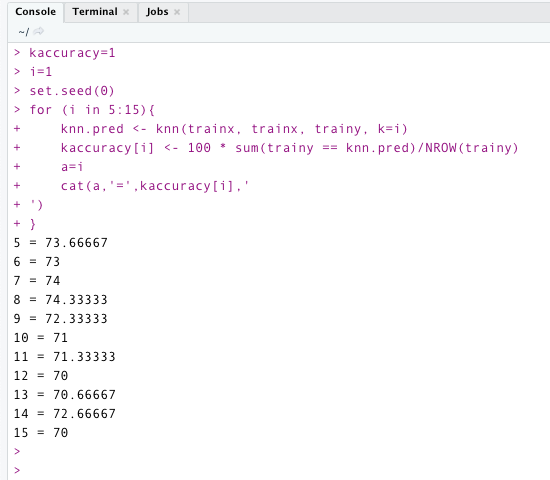
By tuning the hyperparameters, we should be able to find the best value for k. Let’s look at the correct k value for the training data. The code below illustrates the model’s accuracy for various values of k. For k=8, it provides the highest accuracy. That is, “74.33 %”. So we’ll stick with this value of k.
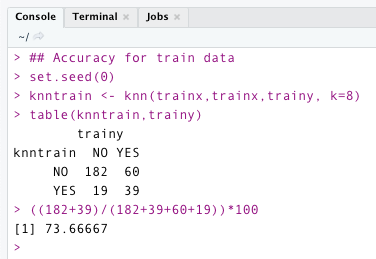
As per the following code, the model’s accuracy for training data with k=8 is 73.66 percentage.
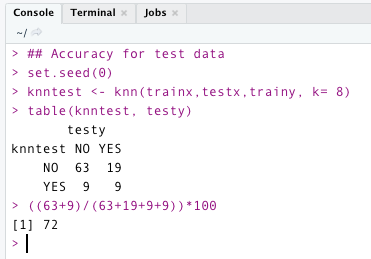
The model’s accuracy for testing data with k=8 is 72%. It works well with both training and testing data in this case. Overfitting and underfitting conditions are not present in this case.
I hope this article has helped you understand the concept better. We learned about bias and variance and the different cases associated with them, such as low bias low variance, low bias high variance, and high bias high variance. In addition, we looked into the concepts of underfitting and overfitting.
Thank You,
Shivam Sharma.
Phone: +91 7974280920
E-Mail: [email protected]
LinkedIn: www.linkedin.com/in/shivam-sharma-49ba71183
The media shown in this article are not owned by Analytics Vidhya and is used at the Author’s discretion.
Meet Shivam, a data scientist with two years of experience currently working at Mercedes Benz. I have worked on multiple projects related to natural language processing, classical machine learning, and deep learning. With my learnings in data science, I am also skilled at analyzing complex data sets to uncover insights and trends that drive business decisions.






