This article was published as a part of the Data Science Blogathon.
In today’s AI-driven world, Machine Learning plays a vital role in automating many real-time applications and replicating human tasks. But can we automate Machine Learning itself? Yes, through AutoML(Automated Machine Learning).
Automated Machine Learning (AutoML)
As the name suggests, it is the process of automating major components of a machine learning project life cycle. In other words, AutoML automatically finds a reasonably good ML model pipeline for a given dataset with a little human intervention.
Generally, a better machine learning model necessitates good ML knowledge, programming skills, mathematical (linear algebra) expertise, domain knowledge. Being an expert in all these skills is not always easy at the beginning. Therefore, with AutoML following components of an ML pipeline can be optimized for a predictive modeling task.
- Data pre-processing
- Feature Engineering/Extraction and Feature Selection
- Model training by selecting an appropriate model family/algorithm
- Hyper-parameter tuning
- Model Evaluation
AutoML advantages
- Helps in quickly finding a good ML model pipeline with less user intervention.
- Less amount of code needs to be written and this makes modeling pretty easy and faster.
- Provides a leaderboard to compare various model families/algorithms for a given dataset.
- Beneficial especially for ML beginners, practitioners, non-experts and allows them to focus more on the problems rather than models.
There are numerous open-source AutoML libraries/frameworks available like Auto-Sklearn, TPOT, PyCaret, H2O AutoML, Hyperopt, Auto-Keras, etc. Additionally, nowadays many organizations like Google, Amazon, Microsoft, IBM, etc. offer AutoML as a service where just the dataset needs to be uploaded and a good ML model pipeline can be downloaded within a few clicks.
In this article, we will explore an AutoML library EvalML and learn how to use it for a binary classification task.
EvalML
EvalML is an open-source Python library for automatically building, optimizing, and evaluating machine learning pipelines for a given dataset. Like any other AutoML library, it also performs data pre-processing, feature engineering, selection, model building, hyper-parameter tuning, cross-validation, etc. automatically.
Installing EvalML
Use the following command in the terminal for installing EvalML.
pip install evalml
EvalML supports a wide variety of supervised learning tasks/problems like regression, classification (both binary and multi-class), time series analysis (including time series regression and classification). The complete list of available problem types can be obtained using the following command.
import evalml evalml.problem_types.problem_types.ProblemTypes.all_problem_types

The ML models are generally evaluated using some evaluation matrices/measures. The selection of the evaluation matrices depends on the type of problem at hand, dataset, business constraints, and requirements.
EvalML also includes a repository of objective functions (evaluation measures like R-squared, precision, recall, F1-score, etc.). By default in EvalML implementation, the objective function is log loss for classification and R-squared for regression problems but it can be easily customized.
Use the following command to get the complete list of available objective functions inside EvalML.
evalml.objectives.get_all_objective_names()
Income dataset
Having known EvalML, now let’s see the demo using the Income Classification dataset available on kaggle. Here, the prediction task is to determine whether the income exceeds $50K/year or not based on this census data.
The dataset contains 15 individual parameters (like age, work class, occupation, marital status, relationship, capital gain, capital loss, native country, etc.) of approx 32.5K people.
The dataset looks like this:
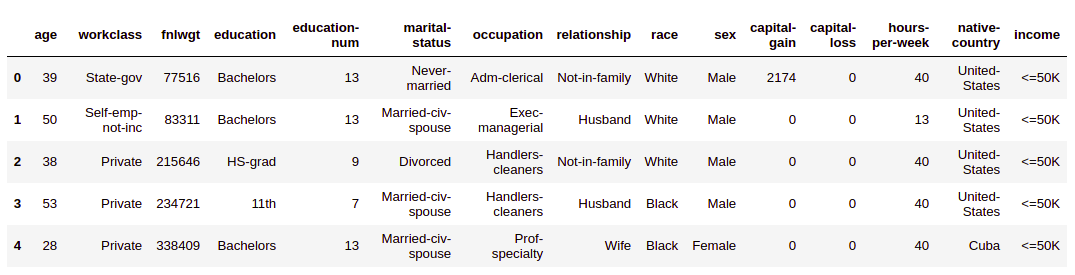
As per this census data, most of the individuals(~76%) make less than $50K a year whereas a small segment(~24%) makes over $50K a year.
df[" income"].value_counts().plot.pie(autopct="%.1f%%",figsize=(7,7))
plt.title("Pie chart of Income")
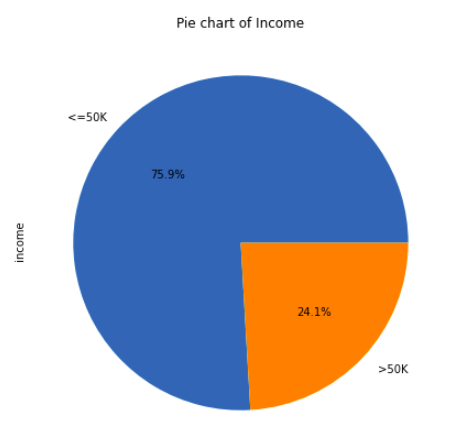
From the pie chart, we can observe that the income ratio of “<=50K” to “>50K” is almost 3:1.
Additional NOTE: In order to access the entire python code follow the kaggle kernel here(https://www.kaggle.com/vikashrajluhaniwal/automl-using-evalml).
Splitting into train-test set
First, let’s split the data into a train and test set for training and testing the model pipelines. EvalML provides a utility method split_data() to perform train-test splitting. Since our income classification is a binary classification task so we set the problem_type argument to “binary” and specified test_size argument value to 0.2 for an 80:20 split.
X = df.drop(" income", axis=1)
y = df[" income"]
X_train, X_test, y_train, y_test = preprocessing.split_data(X, y, problem_type='binary',test_size=.2)
print("Size of training data : ", X_train.shape[0])
print("Size of test data : ", X_test.shape[0])

type(X_train)

EvalML has a different data structure, called DataTable which helps in dealing with each feature according to its data type for pre-processing, feature extraction purposes.
Introducing DataTable
Ever wondered how EvalML will use different featurization techniques (like a bag of words, one-hot encoding, etc.) for text and categorical (non-text) data even if they have the same object data type in pandas?
In order to detect and treat each feature correctly, EvalML makes use of the Woodwork open-source library. EvalML offers a different data structure DataTable to treat columns with the same physical data type differently. For e.g. we should treat text columns in NLP style whereas the text columns with single unique categories as categorical columns even if they have the same object data type.
X_train[[" workclass", " occupation"]].head().T

Here, “workclass” column’s logical type is automatically detected as “Categorical” whereas the “occupation” column’s logical type is “NaturalLanguage”. EvalML also allows you to manually customize the logical type of a text column if needed.
Finding the best ML model pipeline using EvalML
EvalML has a built-in interface/tool called AutoMLSearch to automatically select the best pipeline from a collection of pipelines that works well in determining whether the income exceeds $50K/year or not.
Rather than explicitly performing various things like data pre-processing (missing value imputation, standardization, one-hot encoding, etc.), model training, evaluation, hyper-parameter tuning, etc. AutoMLSearch automates such steps and returns the best model pipeline.
AutoMLSearch also provides plenty of customization options (like problem_type, objective, allowed_pipelines, allowed_model_families, ensembling, etc.) to improve prediction results.
from evalml.automl import AutoMLSearch automl = AutoMLSearch(X_train=X_train, y_train=y_train, problem_type="binary", objective="F1")
Here, while instantiating the AutoMLSearch object, we passed the training data, problem_type as “binary” and the objective as “F1”. Further, we call the search() method on the created object to start the AutoML process and it starts trying out different pipelines to get the best model pipeline.
automl.search()
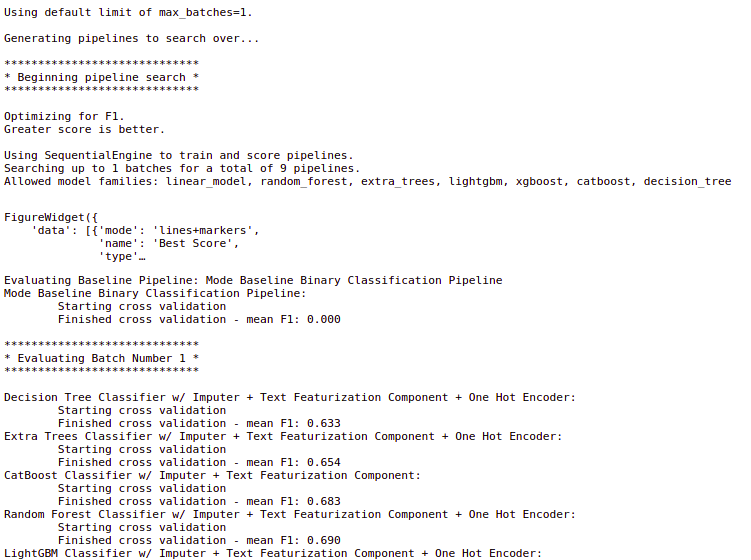
Interacting with the pipelines
Having used AutoMLSearch, now let’s see how to different pipelines rankings, their components, performance, etc.
Use the automl.rankings to get a comparison of different pipelines as per the objective function score.
automl.rankings
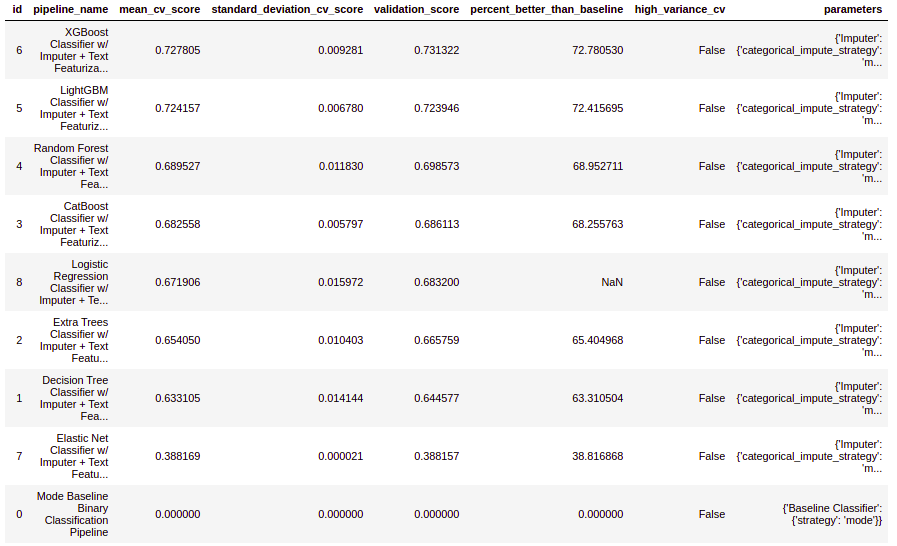
Here, the best pipeline is obtained using the XGBoost classifier. Use the describe_pipeline() function to get more details about a pipeline like its components, performance, etc. by passing the pipeline id.
Get the best pipeline detail as follows.
automl.describe_pipeline(automl.rankings.iloc[0]["id"])
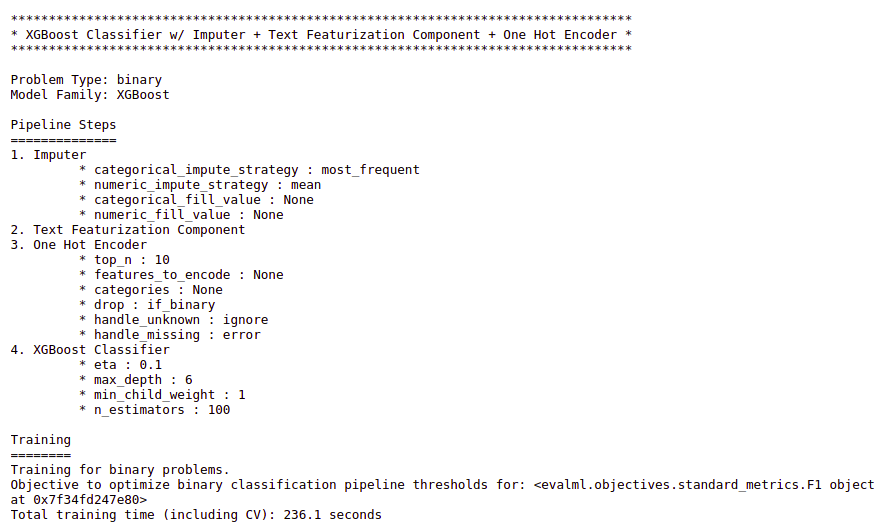
We can also get the visual flow of pipeline components by calling graph() function on the best pipeline.
best_pipeline = automl.best_pipeline
best_pipeline.graph()

Here, the best pipeline has the following components.
- Imputer: EvalML attaches an Imputer to a pipeline for handling missing values. By default, the Imputer imputes the missing values in a numeric column by the mean of that column and imputes by the mode (most frequent category) for a categorical column.
- Text Featurization Component: It does featurization for the text columns (Natural Language columns). It also performs some sort of text pre-processing (like lower-case conversion, removing non-alphanumeric characters, etc.) before text featurization.
- One Hot Encoder: It performs data encoding for categorical columns.
- XGBoost Classifier: Every pipeline needs an estimator (ML model) to learn from the training data and to make predictions. Here, XGBoost Classifier is the estimator in the best pipeline found. Similarly, we have the Extra Trees Classifier, CatBoost Classifier, Random Forest Classifier, etc. in the other pipelines found for this income dataset.
Evaluating the best pipeline on test data
Now let’s see the performance of the best model pipeline on the test (unseen) data for evaluation measures like accuracy and F1-score.
best_pipeline.score(X_test, y_test, objectives = ["auc","f1"])
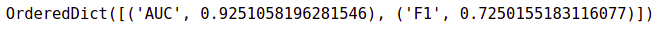
So the best model pipeline obtained through EvalML is 92.51% accurate on the test data. Similarly, it has an F1-score of 0.72 on test data.
End Notes
In this journey so far, we discussed AutoML (especially EvalML), its features, and its advantages. Further, we discovered how to find out a good model pipeline for a binary classification task using EvalML.
This article was published as a part of the Data Science Blogathon.
The media shown in this article are not owned by Analytics Vidhya and is used at the Author’s discretion.
A Data Science professional with 7.5 years of experience in data science, machine learning, and programming. Hands-on experience in different domains like data analytics, deep learning, big data, and natural language processing.




after splitting the train and test it will not be converting data table format.Its on dataframe then how to convert datatable format?