This article was published as a part of the Data Science Blogathon.
Introduction
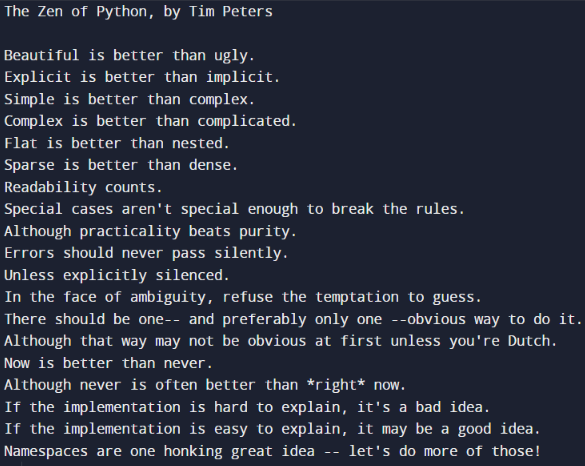
Python is the new up-and-coming language in some of the major fields. There are several why it is popular among the Data Science community. It is guided by a set of principles known as the “Zen of Python” written by Tim Peters. Anyone can view the 19 principles by typing:
import this
One of the reasons Python gets its popularity is because it supports modular programming. What modular programming essentially means is that the whole code can be broken down into small separate subparts, or modules, which collectively work like cogs and wheels and make the program function properly.

Some of the advantages of modular programming are:
- Simplicity
- Maintainability
- Reusability
The constructs that provide modularity in Python are Functions, Modules, and Packages. And in this article, we are going to talk about the module called Collections. The reason is that the Collections module provides us with improved functionalities and highly optimized alternatives to inbuilt Python containers like List, Tuple, Dictionary, etc., and why you should use more of them in your Data Science projects.
First, let us describe what Python Modules and Packages are because the terms might be confusing for beginners.
Module
A module can simply be described as a .py file that contains a set of logically organized python code. This code might contain useful Functions, Classes, or Variables, which are not readily available in the Python programming language but might come quite handy while working on real-life projects. The standard modules can be used by using the import statement.
Packages vs Modules
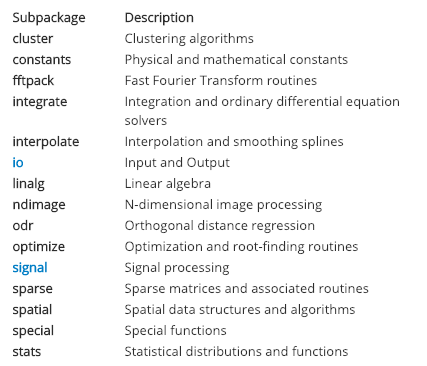
The package is what is created when multiple modules are stacked up together. Some of the core packages, like NumPy, Pandas, SciPy, of Data Science and Machine learning, are made up of thousands of modules. Packages are also sometimes referred to as libraries. Here are some of the modules that make up the SciPy library.
You can view the inbuilt documentation of any Library or module while using Jupyter notebooks. This can be done by using dir() and ?.
dir( numpy )
You can also view any of the methods or functions inside Numpy using ? . For example let us see the docstring of arange function
numpy.arange?
>Docstring: Return evenly spaced values within a given interval. Values are generated within the half-open interval ``[start, stop)`` (in other words, the interval including `start` but excluding `stop`). For integer arguments, the function is equivalent to the Python built-in `range` function, but returns an ndarray rather than a list. When using a non-integer step, such as 0.1, the results will often not be consistent. It is better to use `NumPy.linspace` for these cases. arange([start,] stop[, step,], dtype=None)
This is a fraction of what’s displayed. The docstring provided has in-depth details of the method.
The Collections Module
The Collections module consists of highly specialized and optimized container datatypes like namedtuple(), deque, OrderedDict, counter, etc which are a much better alternative to default Python containers like lists, tuple, and dictionary. Let us go through the Collections containers one by one:
1. namedTuple()
Using built-in Tuples in Python, you can access the elements using their indexes only, as we can see in the example below:
normal_tuple = ( 5, 6, 7, 8, 9 ) normal_tuple[1] > 6 normal_tuple[4] > 9
Thus we cannot access individual elements using unique names which are obviously easier to remember. This is where namedTuple() will come in handy. Using namedTuple allows for a more readable and user-friendly code, and can be used when working with a larger amount of data since it makes accessing the required data easy and effective. In addition to that namedTuple is also a memory-efficient alternative when defining an immutable class in Python.
from collections import namedtuple Complex = namedtuple( 'Complex' , [ 'i' , 'j' ] ) v1 = Complex(11,12) # instantiate with positional argument v1 > Complex( i = 11, j = 12 ) v2 = Complex( j = 5, i = 6) # instantiate with keyword argument in any order v2 > Complex( i = 6, j = 5 )
There are several ways with which you can access the values, like :
v1.i # accessing with names > 11 v2.j > 5 v1[1] # accessing with indexing > 12
2. deque
deque objects are a very fast alternative for Python lists. they support thread-safe and memory-efficient from either side of the deque. deque shares some of its methods with lists and has some of its own. Some of the more useful ones are:
- append(n): adds a new element “n” to the right side of the deque
- appendleft(n): adds a new element to the left side of the deque
- count(e): returns the number of occurrences of the value “e”
- extend(iterable): extends the deque from the right by appending the elements from iterable
- extendleft(iterable): extends the deque from the left by appending the elements from iterable
- insert( i , e ): Inserts new element “e” in position “i”
- reverse(): reverses the elements of the deque
Let us see some examples:
from collections import deque l = deque( [ 10, 12, 11, 12, 13, 14 ] ) l.appendleft(12) l > [12, 10, 12, 11, 12, 13, 14] l.count(12) > 3 l.reverse() l > [ 14, 13, 12, 11, 12, 10, 12 ]
3. defaultdict
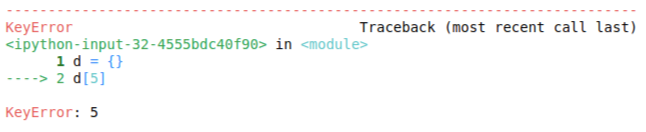
Dictionaries are a very crucial container to keep and retrieve data in key, value format. The keys have to be unique and immutable. If one is trying to access a key that is not present in the dictionary, the python dict raises a KeyError. This can be avoided with defaultdict, it never raises a KeyError, but returns a default value that is specified by the programmer. The remaining functionality is almost the same.
d = {}
d[5]
let’s see what defaultdict does:
from collections import defaultdict
d1 = defaultdict(object)
d1[5]
> <object object at 0x7f3eaa7d1780>
4.OrderedDict
As the name suggests, OrderedDict is a dictionary that ensures that the order of appending of key-value pairs is maintained. Even if the Key is changed later, the pair retains its position.
You can read more about OrderedDict here.
5. Counter
This is probably one of the most useful containers while working with strings. It is mainly used to count hashable items. A dictionary is created with the elements as keys, and their counts as the value. The Counter can be used in multiple ways, let us start exploring that, and start by importing it:
from collections import Counter
A. Strings
s = "dsfffffarfaerarfaffbbgnnan" #this is a random string
Counter(s)
> Counter( { 'd': 1,
's': 1,
'f': 9,
'a': 5,
'r': 3,
'e': 1,
'b': 2,
'g': 1,
'n': 3 } )
B. Lists
l = [ 9, 1, 8, 1, 2, 1, 7, 6, 4, 6, 6, 2 ]
Counter( l )
> Counter({ 9: 1, 1: 3, 8: 1, 2: 2, 7: 1, 6: 3, 4: 1 })
C. Sentences
s = "A set of words that is complete in itself"
Counter(s)
> Counter({'A': 1,
' ': 8,
's': 4,
'e': 4,
't': 5,
'o': 3,
'f': 2,
'w': 1,
'r': 1,
'd': 1,
'h': 1,
'a': 1,
'i': 3,
'c': 1,
'm': 1,
'p': 1,
'l': 2,
'n': 1})
Some extra new methods introduced in version 3.7 are:
- elements(): Returns an iterator with each element specified, as many times as that of the count.
l = Counter( 'a' = 2, 'b' = 3, 'c' = 1,'d' = 2 )
sorted( c.elements() )
> [ 'a', 'a', 'b', 'b', 'b', 'c', 'd', 'd' ]
- most_common( [n] ): Returns a list with the most common elements as well as their counts. The number of elements to be returned has to be specified.
s = "dsfffffarfaerarfaffbbgnnan"
Counter(s).most_common(3) # top 3 most occuring elements
> [('f', 9), ('a', 5), ('r', 3)]
As you can see, the containers in the Collections module can be really useful for business-level projects and models and can add soo much extra usability to generic python containers, with higher optimization and execution speed.
These are the ones I personally try to use more and more in my codes. There are a few other containers that might be useful for you, you can check them out in the official documentation. If it is the speed you want, there is another awesome Python library known as Numba, which can speed your python code up to 1000x faster!! check out my article about Numba here, and get familiar with the basics of it. Thank you for reading, cheers!!
The media shown in this article are not owned by Analytics Vidhya and is used at the Author’s discretion.






