This article was published as a part of the Data Science Blogathon.
Introduction
In the application of the Convolution Neural Network(CNN) model, there is a lot of scope for improvement due to its complex architecture. Researchers had tried a lot of different ways to improve the results of the model. They had tried different image classification methods, altered learning rate used regularization techniques like Dropout, and so on.
All these different methods produced better results but for the Convolution Neural Network model, activation function remains at its core. So, considering the fact that activation function plays an important role in CNNs, proper use of activation function is very much necessary.
Depending on the function it represents, activation functions can be either linear or non-linear and are used to control the outputs neural networks. They are being used across different domains from object recognition and classification to speech recognition, segmentation, cancer detection systems, fingerprint detection, weather forecast, self-driving cars, and other domains to mention a few.
So, while implementing we had doubts about which activation function is to be used. In this article, we will go one by one to different activation functions and look deeper into their pros and cons.
What is an Activation Function?
The input layer of the neural network receives data for training which comes in different formats like images, audio, or texts. From the dataset, input features with weights and biases are used to calculate the linear function. Then, this resultant from the linear function is used by the activation function as input and calculated activations are further fed as input to the next layer.
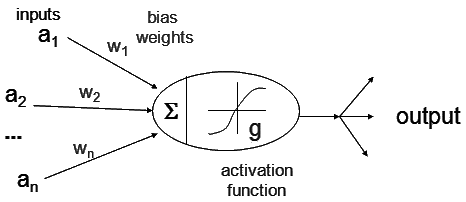
Basically, three important steps took place in a single iteration of deep neural architectures: Forward Propagation, Backward Propagation, and Gradient Descent(Optimization).
1. Forward Propagation: In this step input data is fed in the forward direction through each layer of the neural network. The linear calculation takes place in this step and the activation function is applied.
2. Back Propagation: This step helps in calculating all the derivatives which will be further used for Optimization or updating the parameters.
3. Optimization: This step helps in the convergence of the loss function by continuously updating the parameters in each iteration. Some optimization algorithms are as follows: Gradient Descent, Momentum, Adam, AdaGrad, RMSProp, etc.
Let us discuss Activation Functions
1. Sigmoid Function
· The biggest advantage that it has over other steps and linear functions is its non-linearity. The function ranges from 0 to 1 having an S shape. Also known by the name of the logistic or squashing function in some literature. The sigmoid function is used in output layers of the DNN and is used for probability-based output.
Its major drawbacks are sharp damp gradients during backpropagation, gradient saturation, slow convergence, and non-zero centered output thereby causing the gradient updates to propagate in different directions
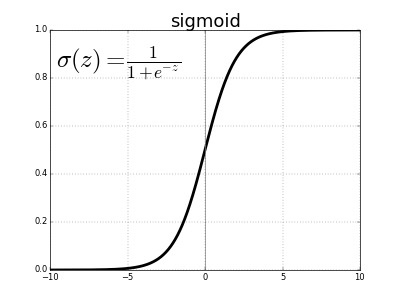
f(x)=1/(1+e^(-x)
Other Variants:
I. Hard Sigmoid Function
II. Sigmoid Weigted Linear Units(SiLU)
2. TanH Function
· The hyperbolic tangent function is a zero-centered function and its range lies between -1 to 1
· As this function is zero centered, this makes it easier to model inputs that have strongly negative, neutral, and strongly positive values
· It is advised to use tanh function instead of sigmoid function if your output is other than 0 and 1
· The tanh functions have been used mostly in RNN for natural language processing and speech recognition tasks
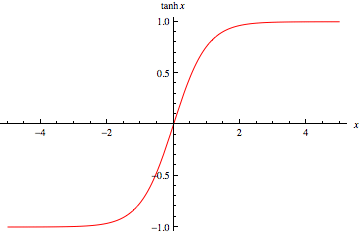
f(x)=(e^x-e^(-x))/(e^x+e^(-x)
3. Rectified Linear Unit(ReLU)
· ReLU has been the most widely used activation function for DL applications with state-of-the-art results
· It provides the upper hand in performance and generalization compared to the Sigmoid and Tanh activation functions
· Along with the overall speed of computation enhanced, ReLU provides faster computation since it does not compute exponentials and divisions
· It easily overfits compared to the sigmoid function and is one of the main limitations. Some techniques like dropout are used to reduce the overfitting
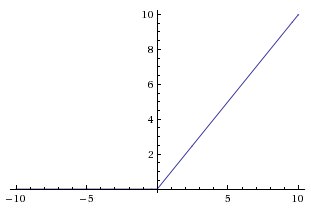
f(x)=x if x≥0 and 0 if x<0
fx=x if x≥0 and 0
if x<0
Other variants:
I. Leaky ReLU(LReLU)
II. Parametric ReLU(PReLU)
III. Randomised Leaky ReLU(RReLU)
IV. S-Shaped ReLU(SReLU)
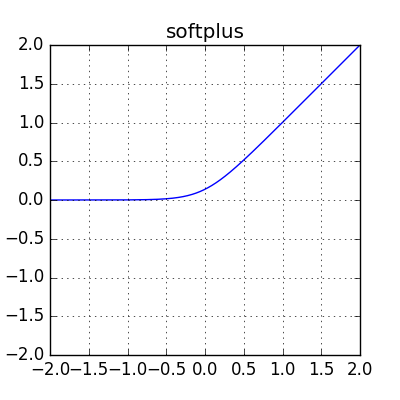
4. Softplus Function
· Softplus was proposed by Dugas in 2001, given by the relationship,
f(x)=log (1+e^x)
· Softplus has smoothing and nonzero gradient properties, thereby enhancing the stabilization and performance of DNN designed with soft plus units
· The comparison of the Softplus function with the ReLU and Sigmoid functions showed improved performance with lesser epochs to convergence during training
5. Exponential Linear Units(ELUs)
· Exponential Linear Unit was proposed by Clevert in 2015
· As it decreases bias shifts by pushing mean activation towards zero during training, ELU represents a good alternative to the ReLU
· A limitation of the ELU is that the ELU does not center the values at zero
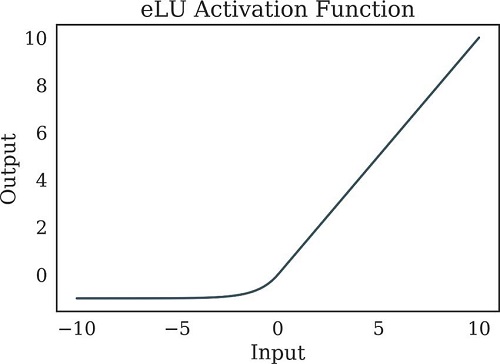
f(x)=x if x>0 and f(x)=∝〖(e〗^x-1) if x<0
Other Variants:
I. Parametric ELU(PELU)
II. Scaled ELU(SELU)
6. Swish Function
· Ramachandran in 2017 proposed the Swish activation function
· It is one of the first compound function proposed by the combination of the sigmoid function and the input function
· The smoothness property makes it produce better optimization and generalization results when used in training deep learning architectures
· This function does not suffer from vanishing gradient problems
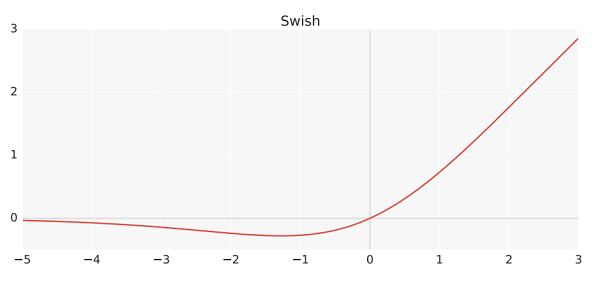
f(x)=x*sigmoid(x)=x/(1+e^(-x)
Choosing the Right One
After going through so many activation functions we need some know-how when and where to use each activation function
Now, depending upon the type of problem we are solving and taking other factors into consideration we should keep the following points in mind:
1.Use the ReLu function in hidden layers only
2.In binary classification remember to use the Sigmoid function in the output layer
3.In multi-class classification(when classes to predict are more than 2) problem use Softmax function in the output layer
4.Due to the vanishing gradient problem ‘Sigmoid’ and ‘Tanh’ activation functions are avoided sometimes in deep neural network architectures
5.Always remember you can also invent your own activation function and can check its performance with the other functions
End Notes
In this article, I had listed the different types of activation functions and the types of advantages and disadvantages one could have while using each of them. I would suggest beginning with a ReLU function for hidden units and explore other functions as you learn further. Always, remember to use the Sigmoid function for binary classification and softmax for multi-class classification.
You can also try your own activation function and can track its performance on your dataset.
Thanks and Keep Learning!!!
The media shown in this article are not owned by Analytics Vidhya and is used at the Author’s discretion.


