Speed Up Text Pre Processing Using TextHero Python Library
Introduction

Natural Language Processing, typically abbreviated as NLP, is a branch of artificial intelligence that manages the connection among PCs and people utilizing the regular language. A definitive target of NLP is to peruse, unravel, comprehend, and figure out the human dialects in a way that is significant. Most NLP strategies depend on AI to get significance from human dialects.
NLP involves applying calculations to recognize and separate the characteristic language decides to such an extent that the unstructured language information is changed over into a structure that PCs can comprehend.
At the point when the content has been given, the PC will use calculations to extricate the importance related to each sentence and gather the fundamental information from them. Here and there, the PC may neglect to comprehend the significance of a sentence well, prompting dark outcomes. For instance, a diverting episode happened during the 1950s during the interpretation of certain words between the English and the Russian dialects.

Why is NLP difficult?
Natural Language processing is viewed as a troublesome issue in software engineering. It’s the idea of the human language that makes NLP troublesome. The guidelines that direct the death of data utilizing regular dialects are difficult for PCs to comprehend.
A portion of these principles can be high-evened out and theoretical; for instance, when somebody utilizes a mocking comment to pass data. Then again, a portion of these principles can be low-evened out; for instance, utilizing the character “s” to mean the majority of things.

Exhaustively understanding the human language requires understanding both the words and how the ideas are associated with convey the proposed message. While people can undoubtedly dominate a language, the equivocalness and loss attributes of the characteristic dialects are what makes NLP hard for machines to carry out.
What is Texthero Library?
Texthero is a python library or toolkit to work with text-based datasets rapidly and easily. It is exceptionally easy to learn and intended to be utilized on top of Pandas. It has similar expressiveness and force to Pandas and is broadly reported. It is present-day and imagined for software engineers of the multi-decade with little information if any is etymological.
You can consider Texthero Library an apparatus to assist you with comprehension and work with a text-based dataset. Given a plain dataset, it’s not difficult to get a handle on the principle idea. All things considered, given a text dataset, it’s harder to have fast experiences into the underline information. With Texthero, preprocessing text data, mapping it into vectors, and visualizing the obtained vector space takes only a few lines of code.
It is free, open-source, and has a well documented ( even beginner can learn easily- best thing )

Texthero includes the following tools:
1. Data (Text) Visualization: Used for vector space visualization and used for place localization on maps.
2. Text Representation: It is used for the representation of text data into vectors. For example, it offers term frequency, Term Frequency-Inverse Document Frequency (TF-IDF), and custom word-embeddings
3. Natural language Processing: Used for keywords and keyphrases extraction, and named entity recognition.
4. Vector Space Analysis: It is used to analyze vector space. It offers clustering algorithms like K-means, DBSCAN, Hierarchical, and Meanshift)
5. Preprocess text data: it offers both out-of-the-container arrangements but on the other hand, it’s adaptable for custom arrangements.
Installation
Use the below code to install via pip. Open a terminal and execute:
pip install texthero
Under the hoods, Texthero utilizes various NLP and AI tool compartments like Gensim, NLTK, SpaCy and scikit-learn. You don’t have to install them all independently, pip will deal with that.
If you already have it, then upgrade to the latest version using the below command:
pip install texthero -U
Import the library
import texthero as hero
Getting Started

Here we are taking an example of BBC Sports Dataset for our further tutorial. This dataset consists of 737 documents from the BBC Sport website.
There are five different areas in this dataset namely football, tennis, rugby, cricket, and athletics.
The original dataset comes as a zip file with five distinctive folders containing the article as text information for every point.
For comfort, we created this script to read all content information and store it into a Pandas Dataframe. So let’s get started by writing some code.
Import the required libraries – texthero and pandas
Import texthero as hero Import pandas as pd
Loading Dataset: Loading BBC Sports Dataset using pandas in pandas data frame
df = pd.read_csv(‘sample.csv’) df.head(2)
Here is the output of the above code:
text topic 0 "Claxton hunting first major medalnnBritish h..." athletics 1 "O'Sullivan could run in WorldsnnSonia O'Sull..." athletics
Data Preprocessing
Let’s clean the data by writing some code. To clean the data, we just have to write a single line of code.
df['clean_data'] = hero.clean(df['text_data'])
You can achieve the same result by using the pipe function as well. Check this below code:
df['clean_data'] = df['text_data'].pipe(hero.clean)
Some of the default pipelines for the clean method is given below:
- Lowercase(string): to lowercase all text
- fillna(s): fill null values with empty spaces
- remove_digits(): To remove all the block of digits
- remove_stopeords(): to remove all the stop words like and, but, how, or, and many more.
For more information click here: Click
We can also use custom pipelines to perform different cleaning tasks at the same time.
from texthero import preprocessing as ppe custom_pipeline = [ ppe.fillna, ppe.lowercase, ppe.remove_whitescape ] df['clean_data'] = hero.clean(df['text_data'], custom_pipeline)
Representation
Once the data is cleaned, the next step is to change the text into a vector. It is used for the representation of text data into vectors. For example, it offers term frequency, Term Frequency-Inverse Document Frequency (TF-IDF), and custom word embeddings. Sol let’s get started.
TFIDF representation:
Below is the code to represent a tet-data pandas series using TF-IDF:
df['clean_text_tfidf'] = hero.tfidf(df['clean_text']
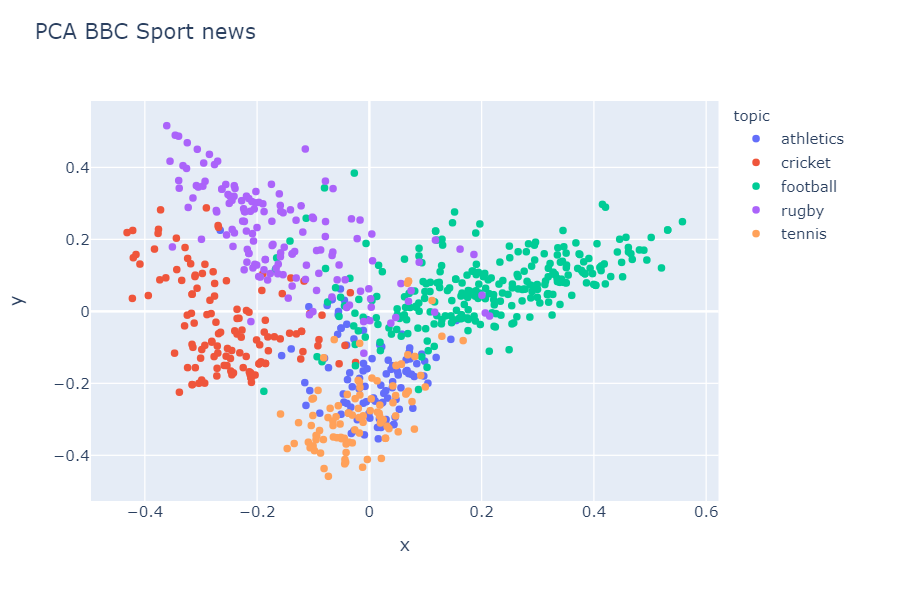
Principal Component Analysis (PCA)
For principal component analysis on pandas series, use the below code:
df['clean_text_pca'] = hero.pca(df['clean_text_tfidf']
All in one step
We can accomplish every one of the three stages shows above, TF-IDF, cleaning, and dimensionality reduction in a single step. Isn’t remarkable?
df['pca] = ( df['text'].pipe(hero.clean).pipe(hero.tfidf).pipe(hero.pca) )
For more information click here: Click

Visualizations
For more information click here: Click
For more information, check the official documentation: Link
Final Note
You can check my articles here: Articles
Thanks for reading this article and for your patience. Do let me in the comment section about feedback. Share this article, it will give me the motivation to write more blogs for the data science community.
Email id: gakshay1210@gmail.com
Follow me on LinkedIn: LinkedIn
The media shown in this article on TextHero library are not owned by Analytics Vidhya and is used at the Author’s discretion.







