Introduction to Convolutional Neural Networks (CNN)
Introduction
In the past few decades, Deep Learning has proved to be a very powerful tool because of its ability to handle large amounts of data. The interest to use hidden layers has surpassed traditional techniques, especially in pattern recognition. One of the most popular deep neural networks is Convolutional Neural Networks (also known as CNN or ConvNet) in deep learning, especially when it comes to Computer Vision applications.
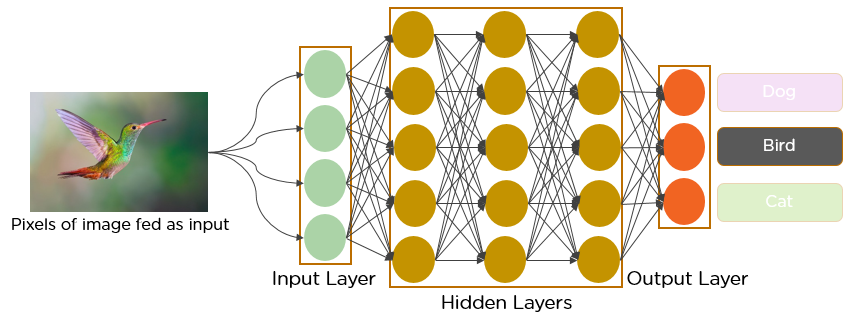
Since the 1950s, the early days of AI, researchers have struggled to make a system that can understand visual data. In the following years, this field came to be known as Computer Vision. In 2012, computer vision took a quantum leap when a group of researchers from the University of Toronto developed an AI model that surpassed the best image recognition algorithms, and that too by a large margin.
The AI system, which became known as AlexNet (named after its main creator, Alex Krizhevsky), won the 2012 ImageNet computer vision contest with an amazing 85 percent accuracy. The runner-up scored a modest 74 percent on the test.
At the heart of AlexNet was Convolutional Neural Networks a special type of neural network that roughly imitates human vision. Over the years CNNs have become a very important part of many Computer Vision applications and hence a part of any computer vision course online. So let’s take a look at the workings of CNNs or CNN algorithm in deep learning.
This article was published as a part of the Data Science Blogathon.
Table of contents
What are Convolutional Neural Network (CNN) ?
In deep learning, a convolutional neural network (CNN/ConvNet) is a class of deep neural networks, most commonly applied to analyze visual imagery. Now when we think of a neural network we think about matrix multiplications but that is not the case with ConvNet. It uses a special technique called Convolution. Now in mathematics convolution is a mathematical operation on two functions that produces a third function that expresses how the shape of one is modified by the other.
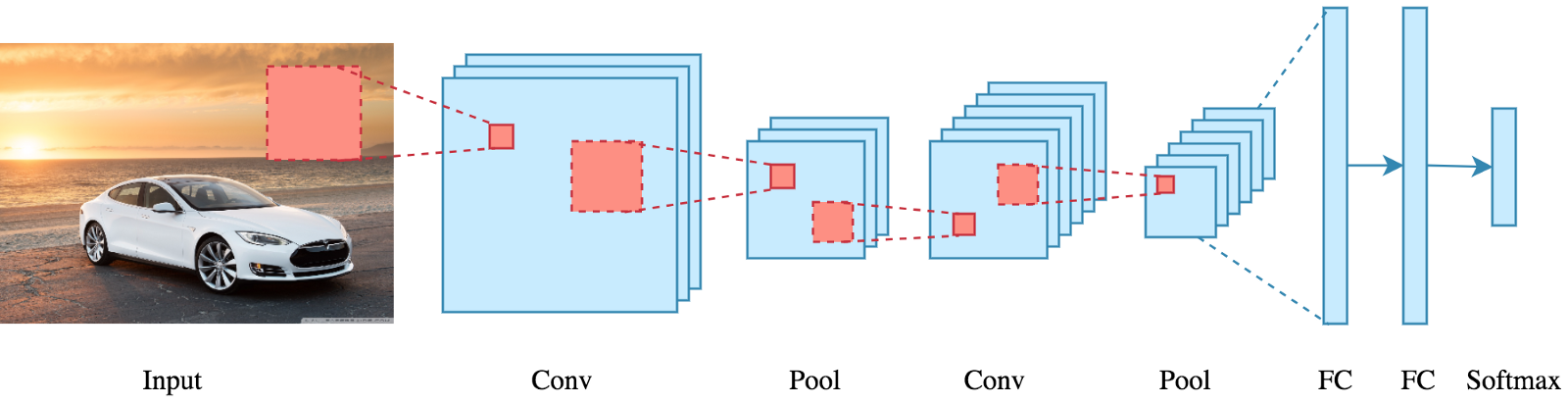
But we don’t really need to go behind the mathematics part to understand what a CNN is or how it works.
Bottom line is that the role of the ConvNet is to reduce the images into a form that is easier to process, without losing features that are critical for getting a good prediction.
How Does CNN work?
Before we go to the working of Convolutional neural networks (CNN), let’s cover the basics, such as what an image is and how it is represented. An RGB image is nothing but a matrix of pixel values having three planes whereas a grayscale image is the same but it has a single plane. Take a look at this image to understand more.
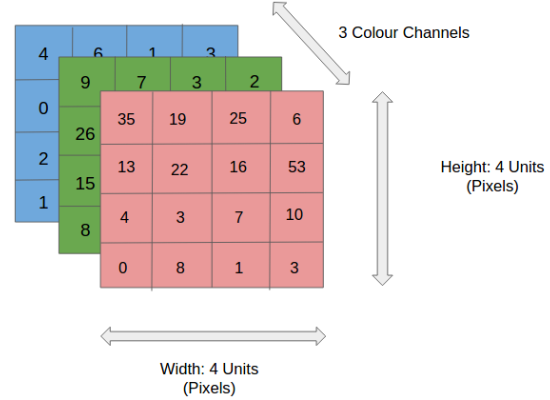
For simplicity, let’s stick with grayscale images as we try to understand how CNNs work.
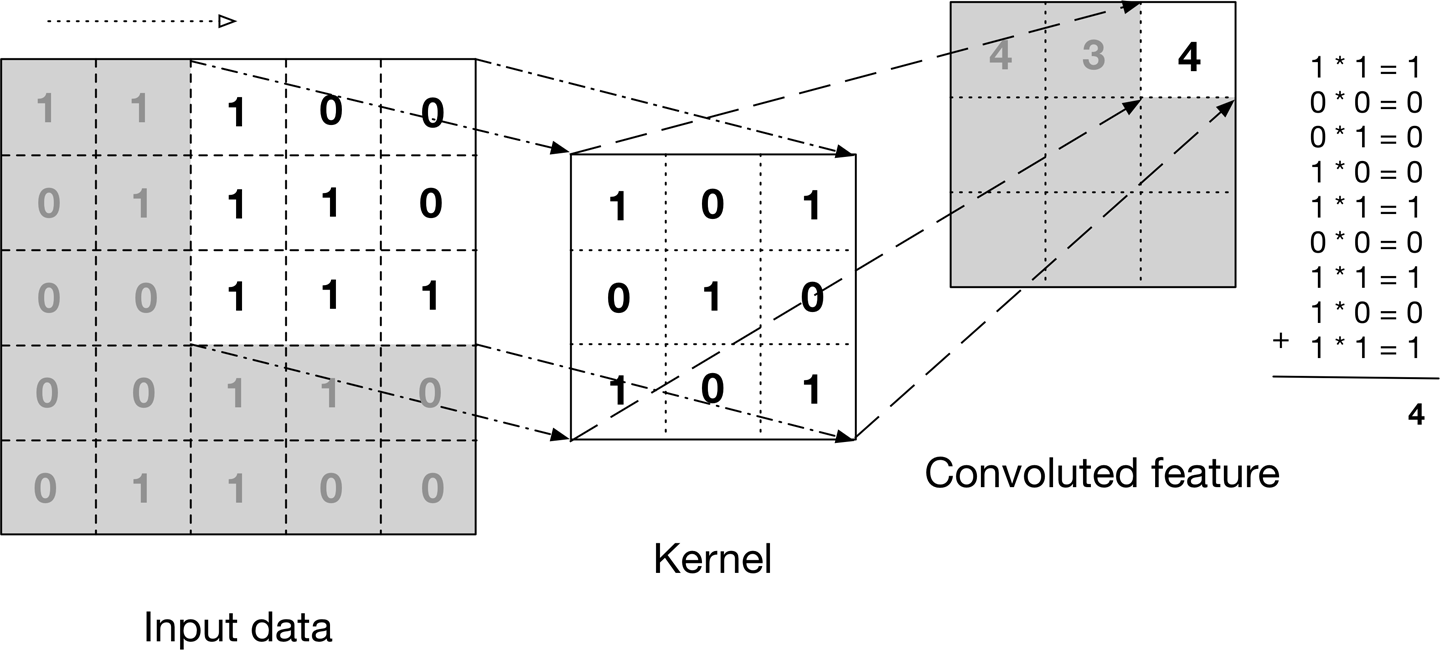
The above image shows what a convolution is. We take a filter/kernel(3×3 matrix) and apply it to the input image to get the convolved feature. This convolved feature is passed on to the next layer.
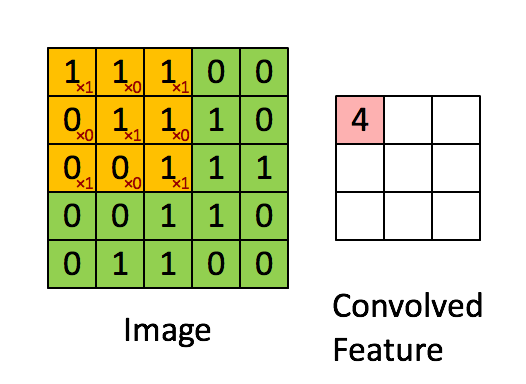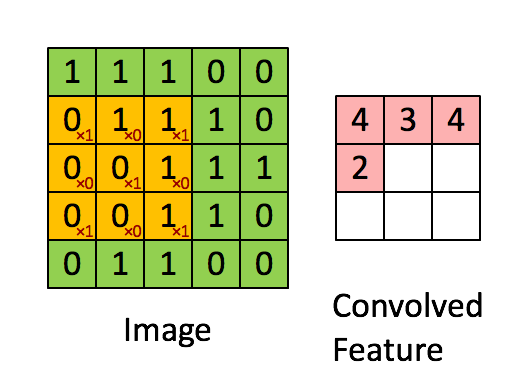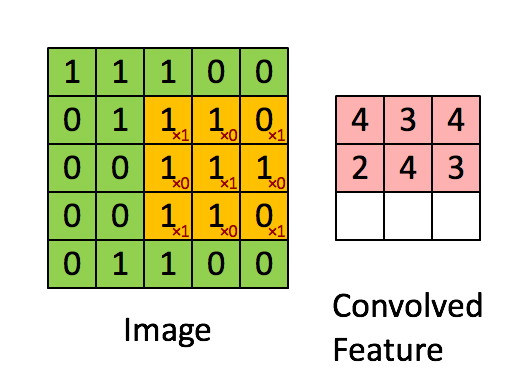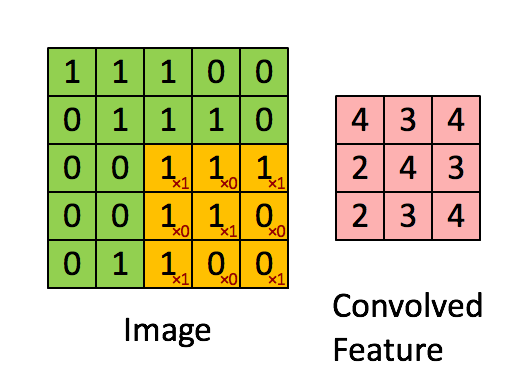
In the case of RGB color, channel take a look at this animation to understand its working
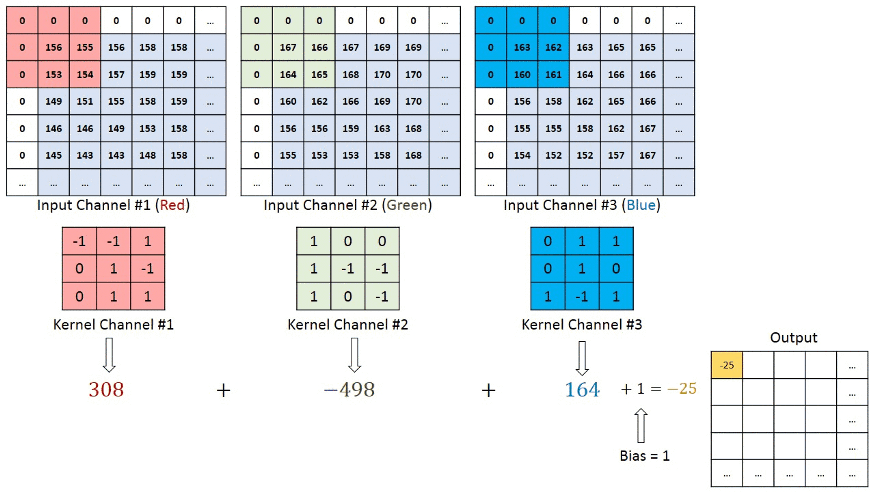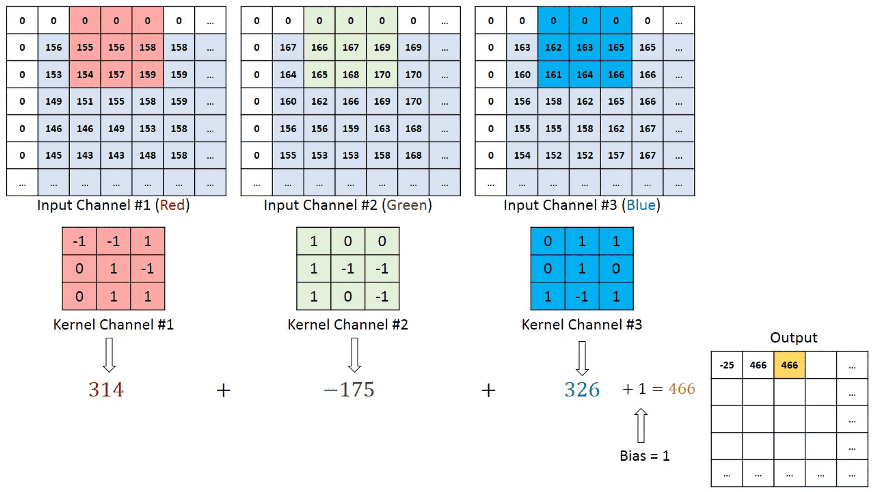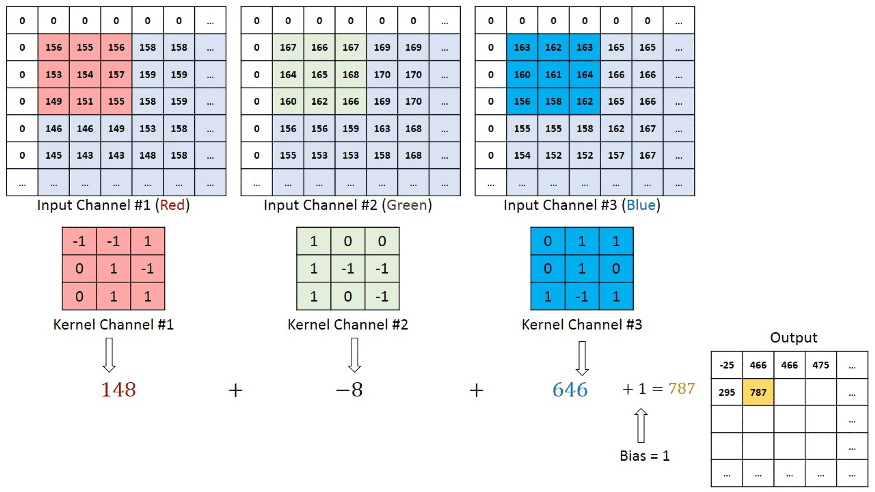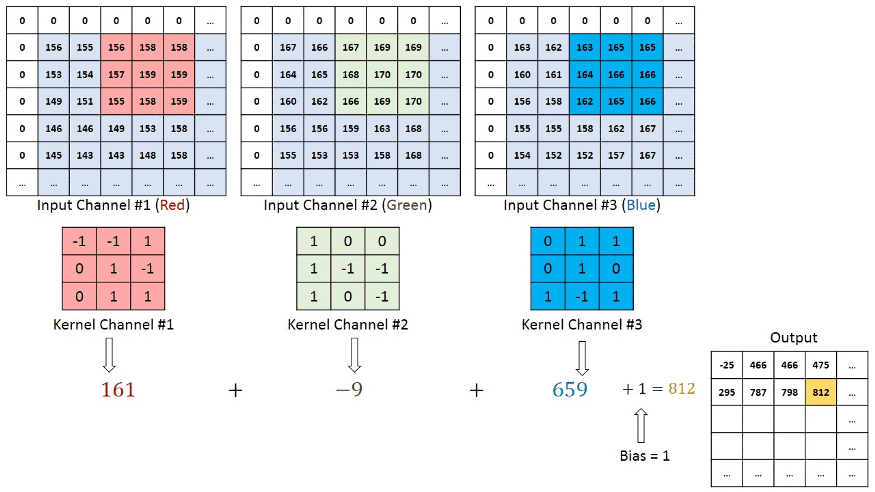
Convolutional neural networks are composed of multiple layers of artificial neurons.
Artificial Neurons
Artificial neurons is a rough imitation of their biological counterparts, are mathematical functions that calculate the weighted sum of multiple inputs and outputs an activation value. When you input an image in a ConvNet, each layer generates several activation functions that are passed on to the next layer.
The first layer usually extracts basic features such as horizontal or diagonal edges. This output is passed on to the next layer which detects more complex features such as corners or combinational edges. As we move deeper into the network it can identify even more complex features such as objects, faces, etc.

Based on the activation map of the final convolution layer, the classification layer outputs a set of confidence scores (values between 0 and 1) that specify how likely the image is to belong to a “class.” For instance, if you have a ConvNet that detects cats, dogs, and horses, the output of the final layer is the possibility that the input image contains any of those animals.
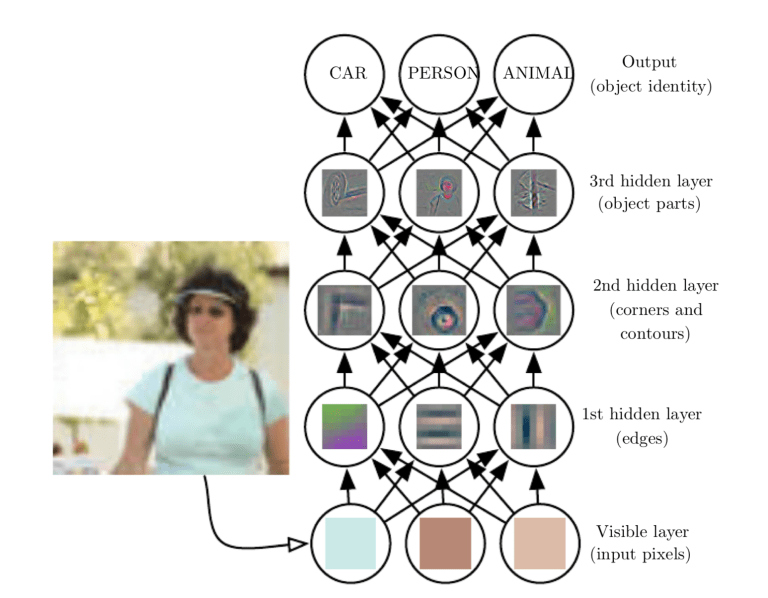
Background of Convolutional neural networks (CNNs)
CNN’s were first developed and used around the 1980s. The most that a Convolutional Neural Networks (CNN) could do at that time was recognize handwritten digits. It was mostly used in the postal sectors to read zip codes, pin codes, etc. The important thing to remember about any deep learning model is that it requires a large amount of data to train and also requires a lot of computing resources. This was a major drawback for CNNs at that period and hence CNNs were only limited to the postal sectors and it failed to enter the world of machine learning.
In 2012 Alex Krizhevsky realized that it was time to bring back the branch of deep learning that uses multi-layered neural networks. The availability of large sets of data, to be more specific ImageNet datasets with millions of labeled images and an abundance of computing resources enabled researchers to revive CNNs
What Is a Pooling Layer?
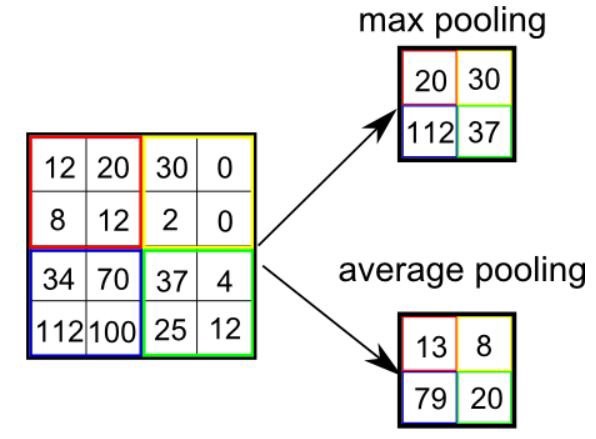
Similar to the Convolutional Layer, the Pooling layer is responsible for reducing the spatial size of the Convolved Feature. This is to decrease the computational power required to process the data by reducing the dimensions. There are two types of pooling average pooling and max pooling. I’ve only had experience with Max Pooling so far I haven’t faced any difficulties.
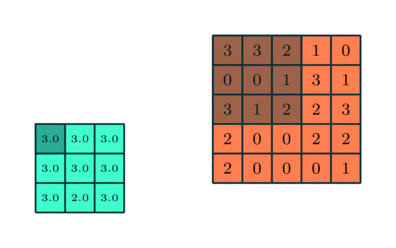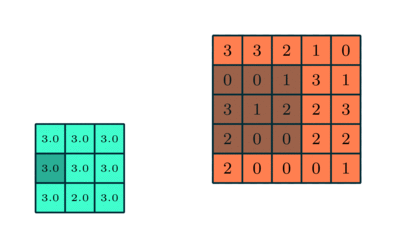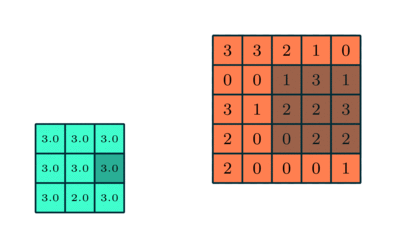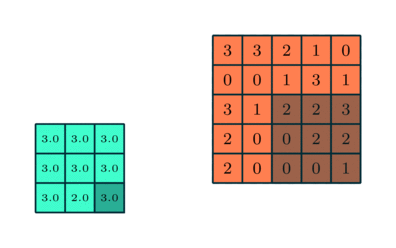
So what we do in Max Pooling is we find the maximum value of a pixel from a portion of the image covered by the kernel. Max Pooling also performs as a Noise Suppressant. It discards the noisy activations altogether and also performs de-noising along with dimensionality reduction.
On the other hand, Average Pooling returns the average of all the values from the portion of the image covered by the Kernel. Average Pooling simply performs dimensionality reduction as a noise suppressing mechanism. Hence, we can say that Max Pooling performs a lot better than Average Pooling.
Limitations of Convolutional neural networks (CNNs)
Despite the power and resource complexity of CNNs, they provide in-depth results. At the root of it all, it is just recognizing patterns and details that are so minute and inconspicuous that it goes unnoticed to the human eye. But when it comes to understanding the contents of an image it fails.
Let’s take a look at this example. When we pass the below image to a CNN it detects a person in their mid-30s and a child probably around 10 years. But when we look at the same image we start thinking of multiple different scenarios. Maybe it’s a father and son day out, a picnic or maybe they are camping. Maybe it is a school ground and the child scored a goal and his dad is happy so he lifts him.

These limitations are more than evident when it comes to practical applications. For example, CNN’s were widely used to moderate content on social media. But despite the vast resources of images and videos that they were trained on it still isn’t able to completely block and remove inappropriate content. As it turns out it flagged a 30,000-year statue with nudity on Facebook.
Several studies have shown that CNNs trained on ImageNet and other popular datasets fail to detect objects when they see them under different lighting conditions and from new angles.
Does this mean that CNNs are useless? Despite the limits of convolutional neural networks, however, there’s no denying that they have caused a revolution in artificial intelligence. Today, CNN’s are used in many computer vision applications such as facial recognition, image search, and editing, augmented reality, and more. As advances in ConvNets show, our achievements are remarkable and useful, but we are still very far from replicating the key components of human intelligence.
Conclusion
In this article, we’ve explored Convolutional Neural Networks (CNNs), delving into their functionality, background, and the role of pooling layers. Despite their effectiveness in image recognition, CNNs also come with limitations, including susceptibility to adversarial attacks and high computational requirements.
Frequently Asked Questions
A. Convolutional Layers: These layers extract features from input data through convolution operations.
Activation Functions: They introduce non-linearities into the network to help it learn complex patterns.
Pooling Layers: These layers downsample feature maps, reducing computational complexity and preventing overfitting.
Fully Connected Layers: They process extracted features for tasks like classification or regression.
Flattening Layer: Converts multidimensional feature maps into a one-dimensional vector for input into fully connected layers.
Output Layer: Produces the final prediction or output of the network.
A. The main advantage of using CNNs is that they do not require human supervision for image classification and identifying important features in images.
The three layers of a Convolutional Neural Network (CNN) are:
Convolutional Layer: Extracts features from input data.
Pooling Layer: Reduces spatial dimensions of feature maps.
Fully Connected Layer: Performs classification or regression tasks based on extracted features.
CNN algorithms are used in various fields such as image classification, object detection, facial recognition, autonomous vehicles, medical imaging, natural language processing, and video analysis. They excel at processing and understanding visual data, making them indispensable in numerous applications.
The media shown in this article are not owned by Analytics Vidhya and is used at the Author’s discretion.









Thank you. Well explained!
The article is precise and brief. Thank you for presenting it in this manner.
What platform can I use to do a CNN I mean like a website
This article is amazing. It's helped greatly in aiding my understanding of CNNs. Thank you so much.
It is very helpful in understanding CNN calculations. Concepts are cleared with pictures. Thanks
Nice article, helped to conceptualise the CNN method
This article is amazing and easy to understand . Thank you for sharing