This article was published as a part of the Data Science Blogathon.
As the “No Free Lunch Theorem” states that there is no algorithm superior to the others. So we can come up with multiple models for a particular problem, hence to select the best out of it we have many performance measures to judge upon. One of which is “CONFUSION MATRIX” which is used for checking the performance of a model based on any classification algorithm.
In this article we will look at the following key points:
- What is Confusion Matrix?
- Terms associated with Confusion Matrix.
- Will also explore more on the terms with an example.
What is Confusion Matrix?
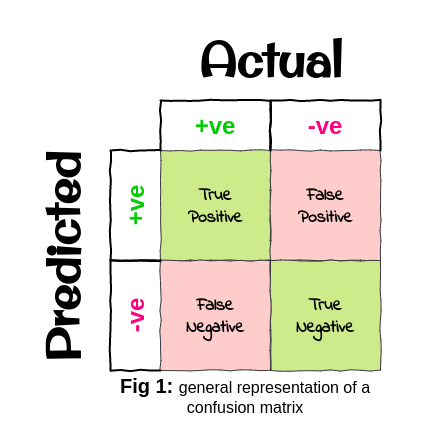
Let’s understand how a confusion matrix works and how it looks with the help of an example that I will be referring to throughout the article.
Let’s imagine we are to build a classification model for a crofter who grows two types of crops viz.
- Yam
- Potato

Yams are sold at a higher price compared to the price of Potatoes.
So the task of the classifier that we have built is to classify both the crops correctly so the crofter can maximize his profit by selling the crops at their right market price.
So the crofter sends 20 samples to us for checking how the classifier performs, out of these 20 samples 11 samples are of Yam and 9 samples are of Potatoes.
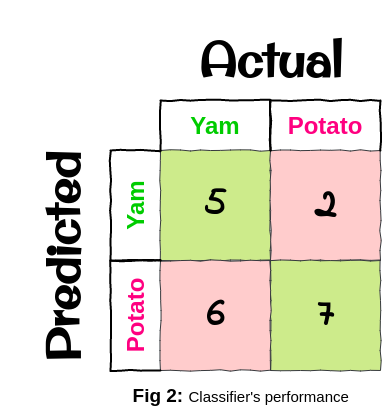
Fig 2 gives us the confusion matrix for our classifier that we built for the crofter, which basically tells us that the columns are our actual classes(crops here) and the rows are our predicted classes(crops here) predicted by the classifier, it also tells us that:
Out of 11 Yam samples, 5 were correctly classified to be Yam and 6 were incorrectly classified to be Potato. Similarly out of 9 Potato samples, 2 were incorrectly classified to be Yam and 7 were correctly classified to be Potato.
That means out of 20 samples 12 were correctly classified(sum of green boxes in fig 2) and 8 were incorrectly classified(sum of red boxes in fig 2). Also from fig 2 we get to know that the classifier is performing really bad for rightly classifying Yam but is doing a faily good job for rightly classifying Potatoes.
So, if we are to define a confusion matrix in simple words then we can say that:
“Confusion Matrix helps us to know the number of correct and incorrect classifications for each class.”
Terms associated with Confusion Matrix
Whenever we come across discussions related to the confusion matrix we often hear words such as “Recall”, “Precision” and “F1-score”, which makes us ponder upon their meaning and usage.
Don’t worry we will discuss it all here in this article, so to begin we will start with their definitions and formulae.
Recall

So recall is the ratio of TP/(TP+FN) where TP is the number of True Positives and FN is the number of False Negatives.
In other words, it lets us know the number of correct classifications of a particular class over the total number of samples of that class.
Let’s understand it with the crofter’s example taking “Yam” as the crop that we are interested in:
so if we calculate the recall be placing the values from fig2 to the formula we got:
recall = 5/(5+6) = 5/11 = 0.454 = 45.4%,
where TP = 5 and FN = 6
As we saw that the recall percentage was quite low that shows that our classifier is not classifying Yam correctly most of the time and often mistaking it to be a potato.
Precision
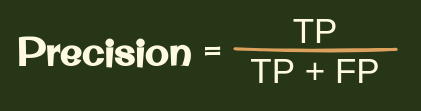
So precision is the ratio of TP/(TP+FP) where TP is the number of True Positives and FP is the number of False Positives.
In other words, it lets us know the number of correct classifications of a particular class over the total number of predictions for that class.
Let’s understand it by again taking the crofter’s example, we still consider “Yam” as the crop that we are interested in:
so if we calculate the precision be placing the values from fig2 to the formula we got:
precision = 5/(5+2) = 5/7 = 0.714 = 71.4%,
where TP = 5 and FP = 2
So from the above calculation, we got the insight that the classifier 5 times correctly predicted the Yam sample to be the “Yam” but 2 times wrongly predicted a Potato sample to be a “Yam”. In other words, the significantly lower values of FP in comparison to TP, the higher the precision of the classifier will be.
Note: There’s always a trade-off between the recall and the precision.
F1- score
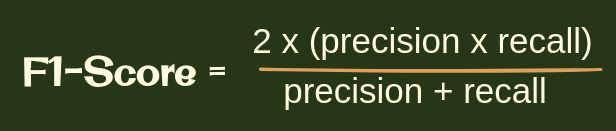

The F1-score is a measure of a model’s overall performance on a particular dataset. The F1-score is a way of combining the precision and recall of the model, and it is defined as the harmonic mean of the model’s precision and recall.
So if we calculate F1-score from the above-calculated precision and recall we have it as below:
F1-score = (2 x (0.454 x 0.714)) / (0.454 + 0.714) = 0.648/1.168 = 0.554
This tells us that the performance of the classifier that we did build for the crofter is not performing that very great in terms of correctly classifying the Yam crop.
You Know What!
We can similarly find the recall, precision, and f1-score for potatoes too, wondering how! Well, let me give you a hint, i.e “By considering them as our positive class or the class of interest”. For that, we would just have to swap the columns of the actual classes and will also have to swap the rows of the predicted classes in fig2. Then the confusion matrix will look as in fig3. BUT WAIT BEFORE LOOKING AT IT WHY NOT TRY IT YOURSELF! later you can verify it for yourself from fig3.
HAPPY SOLVING!!
.png)
Well done! pal you’ve finally reached the end of the article, I hope this article has helped you to clear your confusion on CONFUSION MATRIX.
The media shown in this article are not owned by Analytics Vidhya and is used at the Author’s discretion.







Thanks for nice explanation. It's clear my queries.