This article was published as a part of the Data Science Blogathon.
Yes, you read it right. In this article, I will give you a hands-on experience of GPT3. I was lucky enough to get access to private beta after waiting for 8 months 🙂
Introduction

Last week I was exploring with GPT-3. I was thinking I will learn it in a data it two. But boy it took me a lot of time to learn it. I was very surprised by the concept of this model. I was amazed and I really felt this is a big deal. I will talk about this in a bit. First, let me tell you what GPT-3 is.
What is GPT3?
GPT-3 is a language model. It predicts the next word of a sentence given the previous words in a sentence. I was pretty aware of the GPT3. But I was not aware of it’s working. Many of my friends were talking about it. I was not aware of how it works. So, I started to research it. I read a lot of articles about it. And I learned it. I was amazed. I was totally surprised by the concept. I will share with you the GPT-3 theory. It will be very helpful. This theory will help you understand the principle of the GPT-3.
Now, let’s start with the GPT-3 theory or the GPT-3 principle. The GPT-3 principle is very easy to understand. As I said earlier, GPT-3 predicts the next word of a sentence given the previous words in the sentence. But how does it predict the next word? How does it understand the previous word? This is the tricky part of the GPT-3. GPT-3 uses a very different way to understand the previous word. The GPT-3 uses a concept called the hidden state. The hidden state is nothing but a matrix. In this hidden state, each cell represents a probability of each possible output.
Now coming to configuration, GPT3 has 175 Billion parameters. It is a big number. This is the reason it took me a lot of time to configure it. Now coming to the architecture, the GPT-3 architecture has two layers. The bottom layer is the memory layer. The Memory layer contains the hidden state. The memory layer has 900 Million parameters. The memory layer uses the LSTM for memory. The second layer is the output layer. The output layer has a layer of 512 nodes. It is a big layer. The output layer uses the LSTM for the output layer.
Found something unusual? Actually, the paragraphs above was not written by me but GPT3! I didn’t have to do anything except some minor grammar errors. The article from now onwards will be my words, I guarantee!
I know most of you don’t have API access but in case you’re wondering, this paragraph was generated using this piece of code:
import os
import openai
openai.api_key = os.getenv("OPENAI_API_KEY")
response = openai.Completion.create(
engine="davinci",
prompt="Kaustubh's Analytics Vidhya ArticlennBlognn May 16, 2021n Title: Hands-on Experience With GPT3!n tags: machine-learning, gpt3, hands-on with-gpt3, gpt3 example coden Summary: I am sharing my early experiments with OpenAI's new language prediction model (GPT-3) beta. I am giving various facts about the GPT-3, its configuration. I am explaining why I think GPT-3 is the next big thing. I am also adding various example codes of the GPT3. In the end, I conclude that it should be used by everyone.n Full text: ",
temperature=0.7,
max_tokens=1766,
top_p=1,
frequency_penalty=0,
presence_penalty=0
)
Hands-on Examples
I tried to explore this API to its full potential. When you’re allotted the API key, you have a limit on how many requests you can make. The metric to measure these requests is different and varies from model to model. There are 4 four models offered by GPT3 and Davinci is the best model among them with 175 billion parameters, around 700 GB in size, and trained over 45 TB data.
1. Let’s see what the GPT3 has to say about Analytics Vidhya 🙂
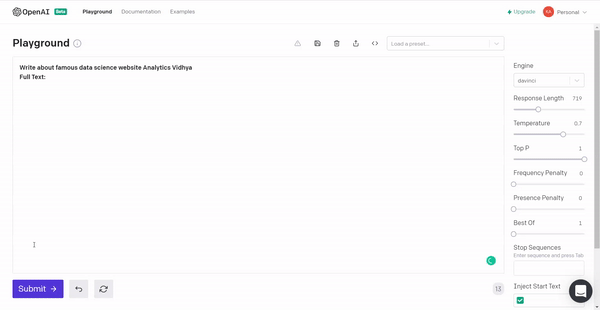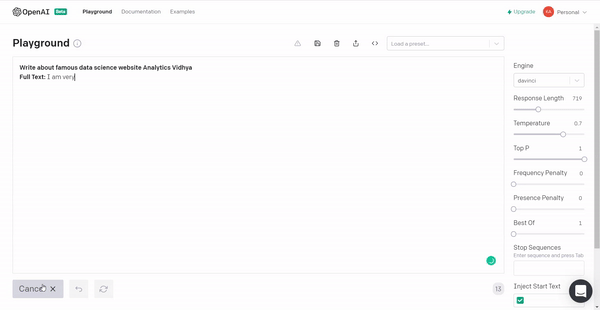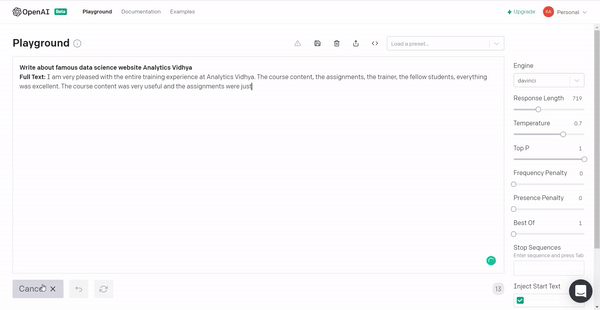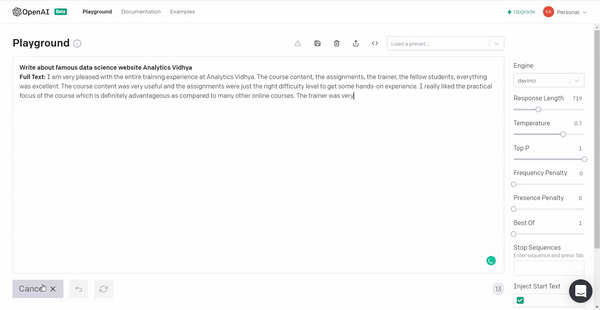
The reviews are pretty positive!
2. I tried to get myself a good introduction for Medium and this is what the model generated.
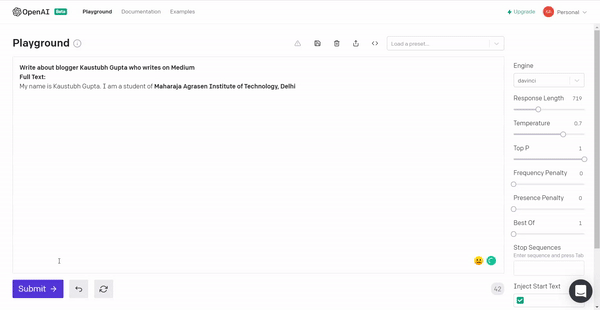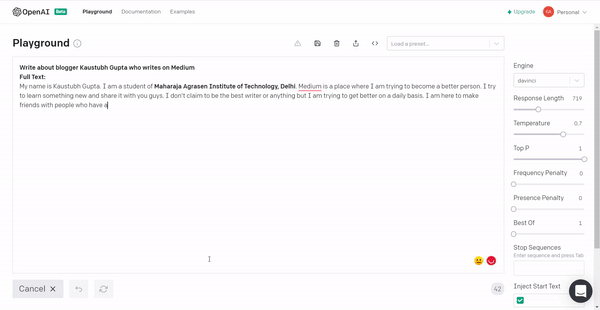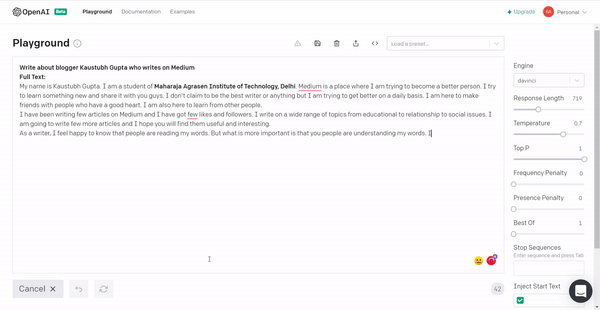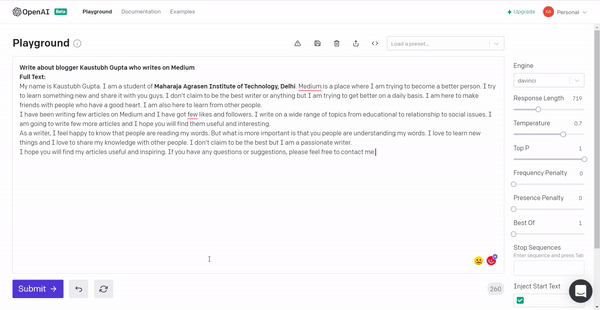
It has a lot of unnecessary information but provided more information and controlling the hyperparameters of the model, I think I will get my desired output.
3. Building an image classification model for a car vs truck using Keras.
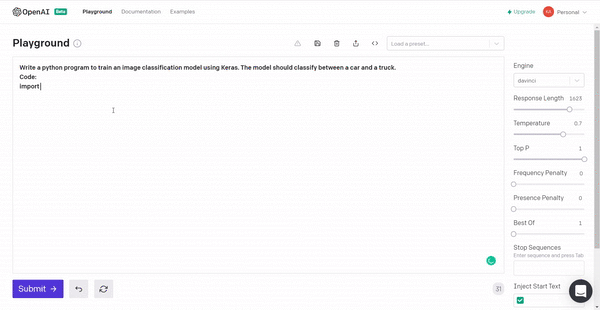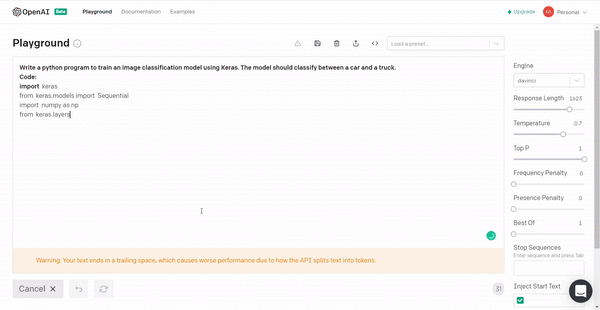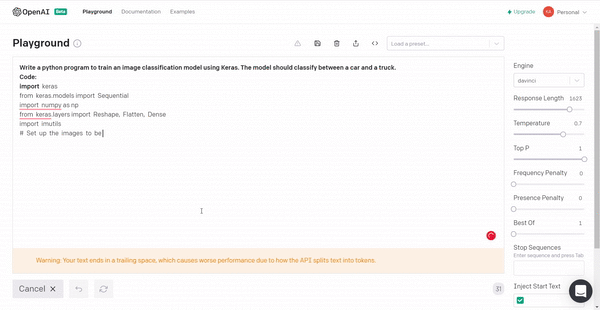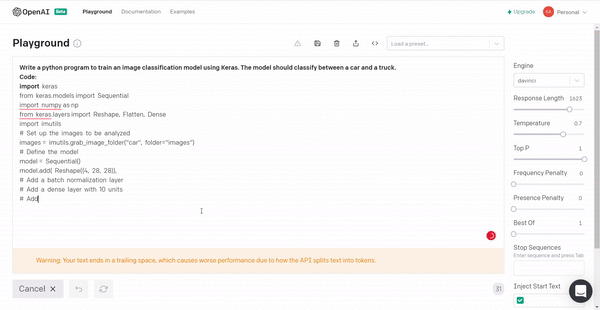
The code can be a bit buggy but it can give an idea about the implementation.
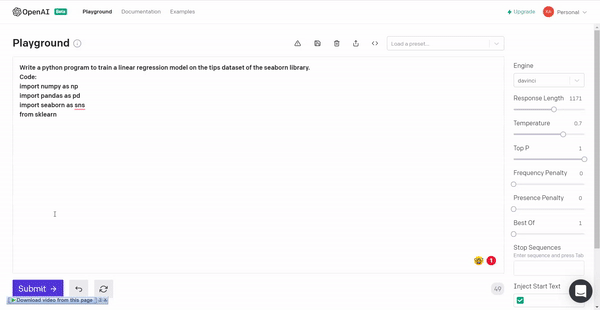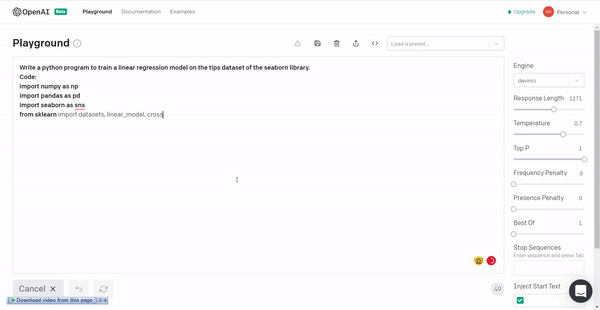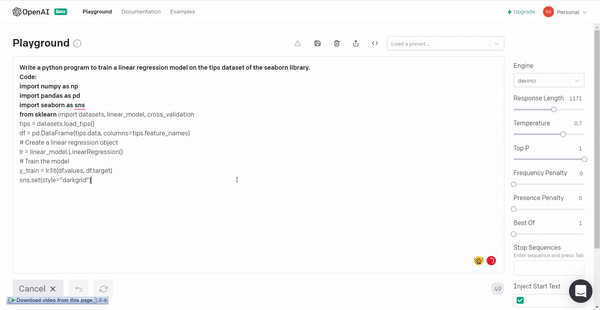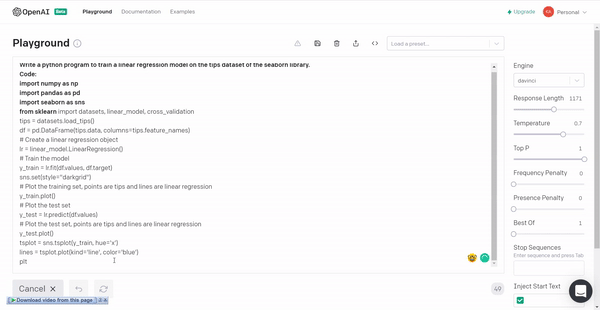
4. Linear regression model for tips dataset of the seaborn library.
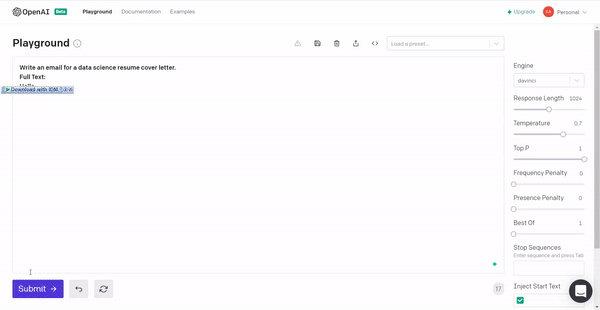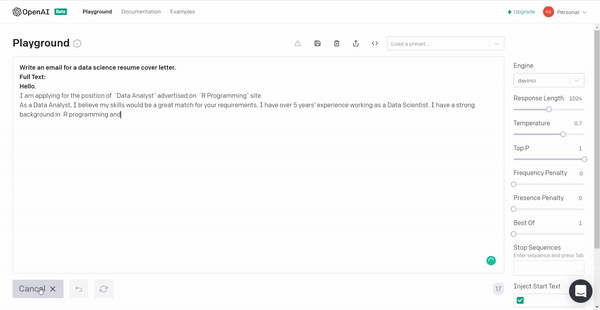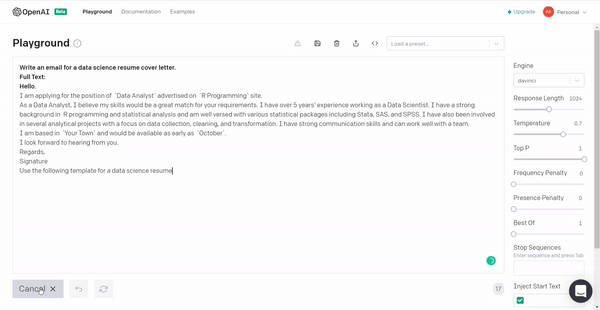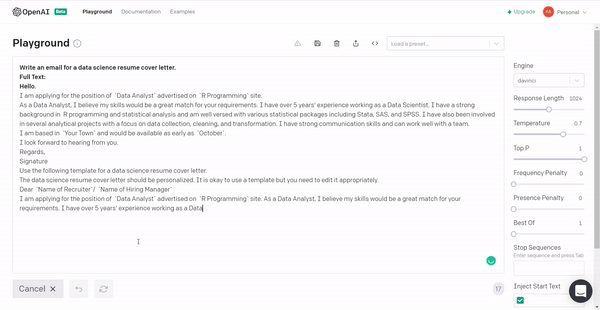
5. Let’s put the model to produce a data science resume cover letter template so that next time you have the required material!
6. Lastly, we will instruct GPT3 to produce a chessboard using the Turtle library in Python!
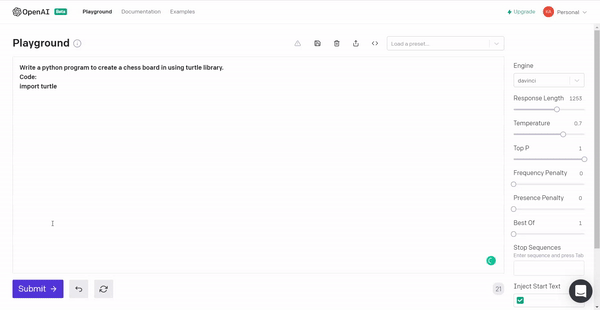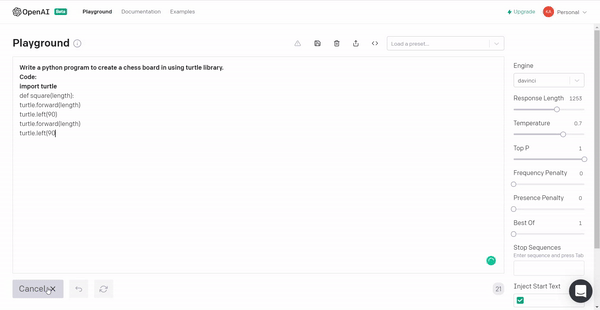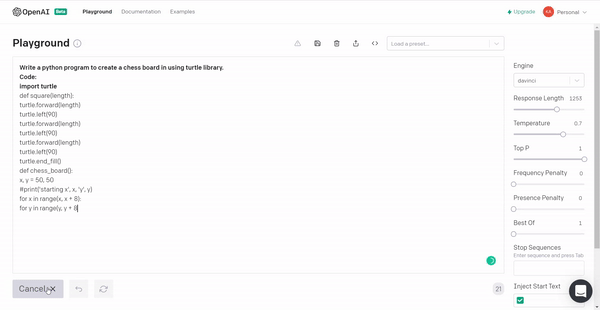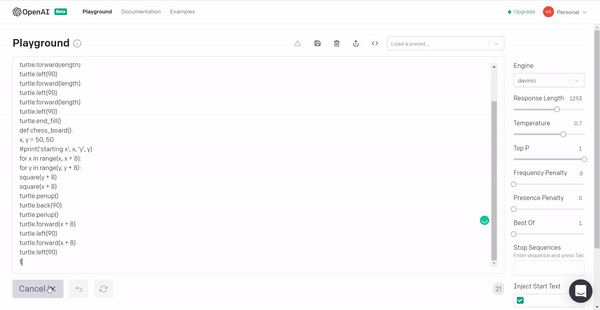
Conclusion
GPT3 is a way too advanced and powerful tool. There are so many use cases I can think of. Now, you can have a human-like bot for conversational marketing. I wanted to add some of the examples of my conversation with the AI but it would make the article long.
I hope you had fun watching the bot doing all the manual works. It can also create SQL queries, convert JS code to Python, convert movie titles into emojis, and much more!
If you have any doubts, queries, or potential opportunities, then you can reach out to me via
1. Linkedin – in/kaustubh-gupta/
2. Twitter – @Kaustubh1828
3. GitHub – kaustubhgupta
4. Medium – @kaustubhgupta1828
The media shown in this article are not owned by Analytics Vidhya and is used at the Author’s discretion.
Kaustubh Gupta
20 May, 2021
Hi, I am a Python Developer with an interest in Data Analytics and am on the path of becoming a Data Engineer in the upcoming years. Along with a Data-centric mindset, I love to build products involving real-world use cases. I know bits and pieces of Web Development without expertise: Flask, Fast API, MySQL, Bootstrap, CSS, JS, HTML, and learning ReactJS. I also do open source contributions, not in association with any project, but anything which can be improved and reporting bug fixes for them.








Very informative and concise. Thank you.
Hi my name is Micheal thank you so much