This article was published as a part of the Data Science Blogathon
Introduction
With the advancement in technology, the growth of social media like Facebook, Twitter, Instagram has been a platform for the customers to give feedback to the businesses based on their satisfaction. The reviews posted by customers are the globally trusted source of genuine content for other users. Customer feedback serves as the third-party validation tool to build user trust in the brand. For understanding these customer feedbacks on an entity, sentiment analysis is becoming an augment tool for any organization.
Sentiment analysis involves examining online conversations like tweets, blog posts, or comments about particular services or topics and segregating the opinions of the users (positive, negative, and neutral) which allows businesses to identify customer sentiment towards the products. It helps businesses with a deep pulse on how customers truly “feel” about their brand and process huge amounts of data in an efficient and cost-effective manner. By automatically analyzing customer feedback, from survey responses to social media conversations, brands are able to listen attentively to their customers, and tailor products and services to meet their needs.
Sentiment analysis can be categorized as Fine-grained, emotion detection, aspect-based sentiment analysis, and intent analysis. The fine-grained sentiment analysis deals with the interpretation polarity in the review while emotion detection involves the emotional expression of the user about a product.
Aspect-based Sentiment Analysis is a variety of sentiment analysis that helps in the improvement of the business by knowing the features in their product which they need to improve according to customer’s feedback to make their product a best seller. ABSA identifies the aspects in the given review about a product and also finds if the aspect mentioned in the review belongs to which class of sentiment.
In this article, we will perform ABSA using SemEval 2014 restaurant and laptop dataset as well as in multilingual datasets like Hindi dataset about products like laptops, phones, restaurants, and hotels.
Data Pre-processing
Tokenization: Tokenization is the breaking of the paragraph of text into smaller chunks like sentence(sentence tokenization) or words(word tokenization). The main drawback of word tokenization is Out of Vocabulary words(OOV), to avoid OOV and also to draw insights from the text sentence tokenization is used in this analysis.
Removing stop words: After tokenization, stop words are identified and removed from the tweets. Stop words are the most common words in a language that might not add much information to the sentence or document. These words are filtered to minimize noise and to improve the quality of the text data for better classification. The NLP library contains a collection of stop words for each language of the text in NLTK. The words in the text are compared with this list of stop words, the matching words are eliminated to improve the data quality and also to easily extract the sentiment words from the tweets.
Removing punctuation and character: After expanding the contractions, the special characters and punctuations are removed using the regex function. The main reason for doing so is because often punctuation or special characters do not have much significance when analyzing the text and utilize it for extracting features or information based on NLP and ML.
Replacing negation with antonyms: Replacing the negative words with antonyms decreases the word count dimensionality of the document matrix hence it is beneficial to compress the vocabulary without losing its meaning to save memory.
Python Code:
from nltk.corpus import wordnet
class AntonymReplacer(object):
def replace(self, word, pos=None):
antonyms = set()
for syn in wordnet.synsets(word, pos=pos):
for lemma in syn.lemmas():
for antonym in lemma.antonyms():
antonyms.add(antonym.name())
if len(antonyms) == 1:
return antonyms.pop()
else:
return None
def replace_negations(self, sent):
i, l = 0, len(sent)
words = []
while i < l:
word = sent[i]
if word == 'not' and i+1 < l:
ant = self.replace(sent[i+1])
if ant:
words.append(ant)
i += 2
continue
words.append(word)
i += 1
return wordsSpelling correction: Words that have several repeated characters & incorrect spellings that occur due to human typing error needs to be removed as it holds no significance in general. For example words like finallyyy , exactlyyy, etc are incorrect entries however it needs to be fixed for further usage.
Lemmatization: Lemmatization is the most common text pre-processing technique used for word normalization. Lemmatizing a word converts the word to its meaningful base form by looking into the morphological analysis of each word. Stemming is also similar to lemmatization but the former does not take into account the context of the word in the sentence and removes only the suffix in the words.
nltk.download('wordnet')
from nltk.stem import WordNetLemmatizer
lemmatizer=WordNetLemmatizer()
antreplacer = AntonymReplacer()
def clean_text(text):
#Lemmatizing the texts
# removing aphostrophe words
text = text.lower() if pd.notnull(text) else text
text = re.sub(r"what's", "what is ",str(text))
text = re.sub(r"'s", " ", str(text))
text = re.sub(r"'ve", " have ", str(text))
text = re.sub(r"can't", "cannot ", str(text))
text = re.sub(r'ain't', 'is not', str(text))
text = re.sub(r'won't', 'will not', str(text))
text = re.sub(r"n't", " not ", str(text))
text = re.sub(r"i'm", "i am ", str(text))
text = re.sub(r"'re", " are ", str(text))
text = re.sub(r"'d", " would ", str(text))
text = re.sub(r"'ll", " will ", str(text))
text = re.sub(r"'scuse", " excuse ", str(text))
text = re.sub('W', ' ', str(text))
text = re.sub('s+', ' ', str(text))
# Remove punctuations and numbers
text = re.sub('[^a-zA-Z]', ' ', str(text))
# Single character removal
text = re.sub(r"s+[a-zA-Z]s+", ' ', str(text))
text=lemmatizer.lemmatize(text)
# replacing negation words with antonyms
text=antreplacer.replace(text)
# Removing multiple spaces
text = re.sub(r's+', ' ', str(text))
text = text.strip(' ')
return text
Classifier models

Embedding is the method of representing the words in the sentence as vectors. The embedding technique we will use will be GloVe embedding, constructing word co-occurrence matrices. The English sentences are trained with pre-trained GloVe embeddings and the embedding for the Hindi sentences are custom trained with 13M Hindi corpus data.
def get_word2vec_embedding_matrix(model):
embedding_matrix = np.zeros((vocab_size,300))
for word, i in tokenizer.word_index.items():
try:
embedding_vector = model[word]
except KeyError:
embedding_vector = None
if embedding_vector is not None:
embedding_matrix[i]=embedding_vector
return embedding_matrix
After the words in the sentences are converted into vectors with GloVe embedding, the Bidirectional LSTM and CNN models are applied on the embedding layer to train and predict the aspect terms and the sentiment terms respectively. The most commonly used 1000 aspect terms are identified in the dataset and the Bi-LSTM model is trained and classified among these aspect classes. The predicted aspect terms are tagged as BIO. The sentiment of the found aspect term is predicted using the CNN model to classify the review as positive, negative, and neutral.
embed_dim = 128 lstm_out = 196 model = Sequential() model.add(Embedding(10000, embed_dim,input_length = 28)) model.add(Bidirectional(LSTM(lstm_out,return_sequences=True))) model.add(LSTM(lstm_out, dropout=0.2, recurrent_dropout=0.2)) model.add(attention()) model.add(Flatten()) model.add(Dropout(0.3)) model.add(Dense(1000, activation='softmax')) model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy']) model.summary()

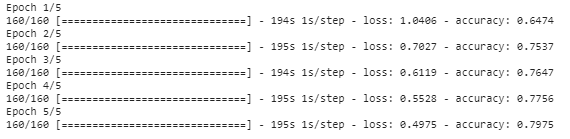
history_object = model.fit(trainX, trainY, epochs=5,batch_size=8)
Summary
In this article, we have applied various pre-processing techniques to the text reviews and the words are converted into vector representations using GloVe embedding. The embedded layer is added with the Bidirectional LSTM layer to find the aspect terms in the sentence and the Bahdanau attention is applied to find the association between the target and the context words. Find the sentiment polarity for each aspect term that is found in the previous model is predicted using the CNN model to classify the aspect term as positive, negative, or neutral. The aspect terms that are predicted from the sentence are tagged with BIO tagging namely, Beginning, intermediate, or outside the aspect term.
The entire code for this mini-project is available here.
End Notes
Hope you enjoyed reading this article.
Happy Learning!!
The media shown in this article are not owned by Analytics Vidhya and are used at the Author’s discretion.





please share a sample working cleaned code for ABSA.
please full code with data on aspect based sentimental analysis.
what does the "α" means on the picture of classifier models? after CNN and BiLSTM, before softmax. please and thank you