This article was published as a part of the Data Science Blogathon
Introduction
In today’s article, I will talk about developing a convolutional neural network employing TensorFlow Functional API. It will dispense the capability of functional API, which allows us to produce hybrid model architecture surpassing the ability of a primary sequential model.

About: TensorFlow
TensorFlow is a popular library, something you perpetually hear probably in Deep Learning and Artificial Intelligence society. There are numerous open-source packages and projects for deep learning.
- TensorFlow, an open-source artificial intelligence library managing data flow graphs, is the most prevalent deep-learning library. It is used to generate large-scale neural networks with countless layers.
- TensorFlow is practiced for deep learning or machine learning predicaments such as Classification, Perception, Perception, Discovery, forecast, and Production.
So, when we interpret a classification problem, we apply a convolutional neural network model. Still, most developers were intimate with modeling sequential models. The layers accompany each other one by one.
- The sequential API empowers you to design models layer-by-layer for most significant problems.
- The difficulty is restricted in that it does not allow you to produce models that share layers or have added inputs or outputs.
- Because of this, we can practice Tensorflows Functional API as Multi-Output Model.
Functional API (tf.Keras)
The functional API in tf.Keras is an alternative way of building more flexible models, including formulating a further complex model.
- For example, when implementing an insignificantly more complicated example with machine learning, you may rarely face the state when you demand added models for the same data.
- So we would need to produce two outputs. The most manageable option would be to build two separate models based on the corresponding data to make predictions.
- This would be gentle, but what if, in a present scenario, we need to have 50 outputs. It could be a discomfort to maintain all those separate models.
- Alternatively, it is more fruitful to construct a single model with increased outcomes.
In the open API method, models are determined by forming layers and correlating them straight to each other in sets, then establishing a Model that defines the layers to function as the input and output.
What is different in Sequential API?
Sequential API enables you to generate models layer-by-layer for most top queries. It is regulated because it does not allow you to design models that share layers or have added inputs or outputs.
Let us understand how to create an object of sequential API model below:
model = tf.keras.models.Sequential([ tf.keras.layers.Flatten(input_shape=(28, 28)), tf.keras.layers.Dense(128, activation=’relu’), tf.keras.layers.Dropout(0.2), tf.keras.layers.Dense(10, activation=’softmax’) ])
- In functional API, you can design models that produce a lot more versatility. You can undoubtedly fix models where layers relate to more than just the preceding and succeeding layers.
- You can combine layers with several other layers. As a consequence, producing heterogeneous networks such as siamese networks and residual networks becomes feasible.
Let’s begin to develop a CNN model practicing a Functional API
In this post, we utilize the MNIST dataset to build the convolutional neural network for image classification. The MNIST database comprises 60,000 training images and 10,000 testing images secured from American Census Bureau workers and American high school juniors.
# import libraries
import numpy as np
import tensorflow as tf
from tensorflow.keras.layers import Dense, Dropout, Input
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten
from tensorflow.keras.models import Model
from tensorflow.keras.datasets import mnist
# load data
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# convert sparse label to categorical values
num_labels = len(np.unique(y_train))
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
# preprocess the input images
image_size = x_train.shape[1]
x_train = np.reshape(x_train,[-1, image_size, image_size, 1])
x_test = np.reshape(x_test,[-1, image_size, image_size, 1])
x_train = x_train.astype('float32') / 255
x_test = x_test.astype('float32') / 255
In the code above,
- I distributed these two groups as train and test and distributed the labels and the inputs.
- Independent variables (x_train and x_test) hold greyscale RGB codes of 0 to 255, whereas dependent variables (y_train and y_test) carry labels of 0 to 9, describing which number they genuinely are.
- It is a good practice to normalize our data as it is constantly required in deep learning models. We can accomplish this by dividing the RGB codes by 255.
Next, we initialize parameters for the networks.
# parameters for the network input_shape = (image_size, image_size, 1) batch_size = 128 kernel_size = 3 filters = 64 dropout = 0.3
In the code above,
- input_shape: variable represents a need to plan and style a standalone Input layer that designates input data. The input layer accepts a shape argument that is a tuple that describes the dimensions of the input data.
- batch_size: is a hyperparameter that determines the number of samples to run through before refreshing the internal model parameters.
- kernel_size: relates to the dimensions (height x width) of the filter mask. Convolutional neural networks (CNN) are essentially a pile of layers marked by various filters’ operations on the input. Those filters are ordinarily called kernels.
- filter: is expressed by a vector of weights among which we convolve the input.
- Dropout: is a process where randomly picked neurons are neglected throughout training. This implies that their participation in the activation of downstream neurons is temporally dismissed on the front pass.
Let us define a simplistic Multilayer Perceptron, a convolutional neural network:
# utiliaing functional API to build cnn layers inputs = Input(shape=input_shape) y = Conv2D(filters=filters, kernel_size=kernel_size, activation='relu')(inputs) y = MaxPooling2D()(y) y = Conv2D(filters=filters, kernel_size=kernel_size, activation='relu')(y) y = MaxPooling2D()(y) y = Conv2D(filters=filters, kernel_size=kernel_size, activation='relu')(y) # convert image to vector y = Flatten()(y) # dropout regularization y = Dropout(dropout)(y) outputs = Dense(num_labels, activation='softmax')(y) # model building by supplying inputs/outputs model = Model(inputs=inputs, outputs=outputs)
In the code above,
- We specify a multilayer Perceptron model toward binary classification.
- The model holds an input layer, 3 hidden layers beside 64 neurons, and a product layer with 1 output.
- Rectified linear activation functions are applied in all hidden layers, and a softmax activation function is adopted in the product layer for binary classification.
- And you can observe the layers in the model are correlated pairwise. This is achieved by stipulating where the input comes from while determining each new layer.
- As with every Sequential API, the model is the information we can summarize, fit, evaluate, and apply to execute predictions.
TensorFlow presents a Model class that you can practice to generate a model from your developed layers. It demands that you only define the input and output layers—mapping the structure and model graph of the network architecture.
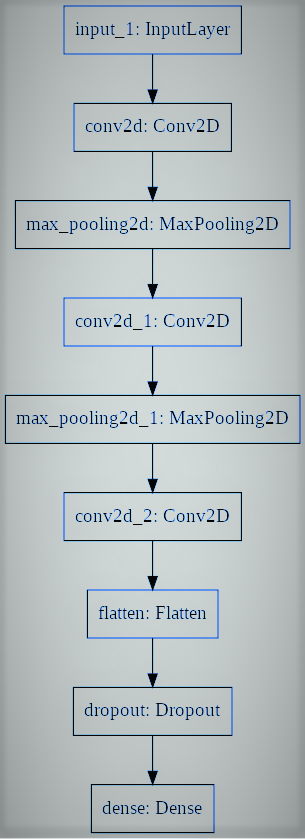
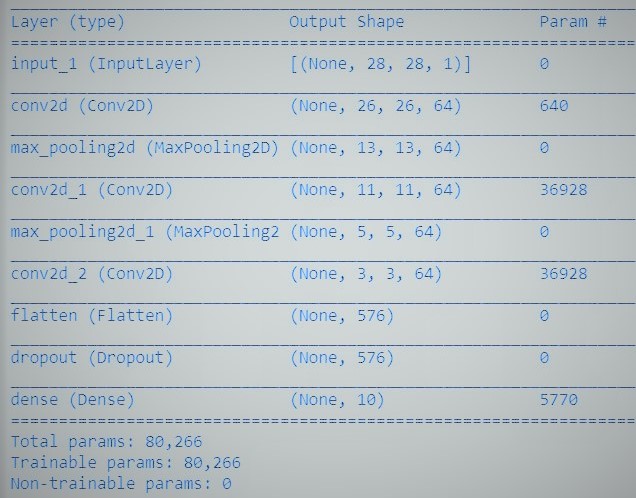
Lastly, we train the model.
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
model.fit(x_train,
y_train,
validation_data=(x_test, y_test),
epochs=20,
batch_size=batch_size)
# accuracy evaluation
score = model.evaluate(x_test,
y_test,
batch_size=batch_size,
verbose=0)
print("nTest accuracy: %.1f%%" % (100.0 * score[1]))
Now we have successfully developed a convolutional neural network to distinguish handwritten digits with Tensorflow’s Functional API. We have obtained an accuracy of above 99%, and we can save the model & design a digit-classifier web application.
References:
- https://www.tensorflow.org/guide/keras/functional
- https://machinelearningmastery.com/keras-functional-api-deep-learning/
The media shown in this article on Sign Language Recognition are not owned by Analytics Vidhya and are used at the Author’s discretion.
Data Scientist and a Technical Writer! I will give you the best of Open-Source and AI.
Talks about #chatgpt, #opensource, #contentcreation, #communitybuilding, and #artificialintelligence
Technical Writer | Data Science, ML, AI, Open-Source | Do More with Data - Litmus





