This article was published as a part of the Data Science Blogathon
Introduction
This article shows the power of Memory Networks for Question and Answer (QA) applications in the context of simple natural language-based reasoning.
Table of Contents
- What is the motivation behind Memory Networks?
- Why do we need Memory Networks when traditional NLP models are already performing well?
- Facebook bAbI dataset
- About Supporting Fact
- Components of Memory Networks
- How can we find the best match?
- How does the dot product find the matching?
- Sample QA application
- Endnotes
What is the motivation behind Memory Networks?
The basic motivation for Memory Networks is an attempt to add Long-term memory to save the knowledge of the question and answer. So external memory is used as a knowledge base to make QA applications like artificial intelligence.
Why do we need Memory Networks when traditional NLP models are already performing well?
It is important to store a large amount of prior knowledge for reasoning. Traditional deep learning models such as RNN, LSTM, and GRU use hidden states or Attention mechanisms as their memory, these models are powerful sequence predictors that can be efficiently trained to learn to do inference, but the memory used by these models are limited. The state and weights are all embedded in a low-dimensional space, and the knowledge is compressed into a dense vector. These models can perform poorly on tasks that involve long-term dependencies. A large number of experiments and Researchers have proved that LSTM is not effective enough for a longer time, and cannot achieve the effect of recording more and longer memory.
Facebook bAbI dataset
Facebook has released a bAbI dataset which is organized towards the goal of automatic text understanding and reasoning. Their research is to build an artificial intelligence model which can use related sentences to answer questions about a given story. It has 20 such tasks and 10000 questions. Each task checks a unique skill that a reasoning system should have.

Source: The Facebook bAbI project , dataset
We are going to focus on only two tasks out of the 20 tasks mentioned above. These tasks can’t respond in sentences.
(T1) Single supporting fact
- The theme of the task is asking for the location of a person who is in action.
- This task indicates the answer from a previously given sentence.
(T2) Two supporting facts
- The theme of the task is asking for the location of a person or an object.
- This task indicates two supporting statements to be chained to answer the question.
Each task consists of
- A set of facts or a story: <list of sentences>
- Question based on given story: <single sentence>
- Answer: <single word>
About Supporting Fact
The supporting fact indicates the location of the answer. Every question is tagged with an Answer and supporting fact(s).
Strongly Supervised Memory Networks
A model trained directly with supporting facts is called the Strongly Supervised Memory Networks model.
Weakly Supervised Memory Networks
A model trained without the supporting facts is called the Weakly Supervised Memory Networks model.
Components of Memory Networks
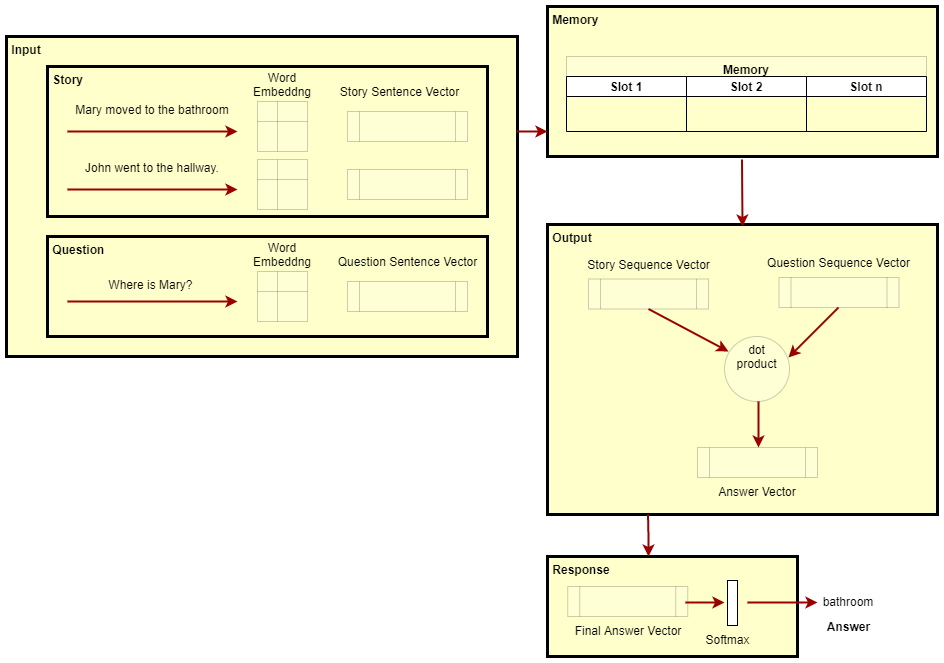
Input :
Action: Converts incoming data to the internal feature map.
- Stories and Questions are the inputs.
- We need a single sentence vector to represent each sentence. So, input stories are converted into word embeddings and then converted into Story sentence vectors.
- Apply the same procedure for the Question and form a Question sentence vector.
Memory :
Action: Stores the input
- It takes the input sentence vectors and stores them into the next available memory slot.
Output :
Action: Calculate the score and generates the answer vector
- It takes the question and loops over all the memories.
- Calculate the score of a given question with each Story Sentence vector and find the best match with the higher score
- Generates the feature vector for the answer. The answer vector is representing the relevant sentence.
- When you have two supporting facts, the process is extended with two blocks. This is where the memory networks start to look sort of recurrent for the first block. We just pass the question vector to determine the answer vector, but for the second block, we pass the answer vector from the first block to determine the final answer vector. These blocks are called memory hops.
Response :
Action: Generates an answer from the final answer vector of the Output
- It takes the answer feature vector and generates the best single word using softmax
How can we find the best match?
We have converted the Input text sequence into word embeddings and formed sentence vectors for the Story and Question respectively.
Question is the triggering point to figure out which sentence I should pay attention to determine the answer. When we perform a dot operation for the question vector with the story sentence vector, we will get a score for each sentence. The result is called the answer vector. The higher score in the answer vector indicates the best match for the given question and its relevant sentence.
We will pass this answer vector through a single dense layer and apply a final softmax. The size of the output is just the vocabulary size, and the answer is a single word.
How does dot product find the matching?
In general, the dot product is known as a distance finder. It is closely related to cosine similarity.
It helps us to find how two things are similar from their score.
Word embedding maps different words in low dimensional vector space with the advantage to calculate the distance between word vectors. Word embeddings allow us to find similarity scores between different sentences to understand the maximum correlation between them. By using these facts, we can say which sentence is highly correlated with the question using the dot product.
Sample Q&A application
Table 1: Test Accuracies on Task 1 Single Supporting Fact
| Story: Task1 Single Supporting Fact |
Question | Memory Vector |
| Sandra traveled to the bathroom | Where is Sandra? | 0.00002 |
| Sandra journeyed to the office | Where is Sandra? | 0.00093 |
| Mary journeyed to the bedroom | Where is Sandra? | 0.00000 |
| John moved to the hallway | Where is Sandra? | 0.00000 |
| Sandra went back to the bathroom | Where is Sandra? | 0.99903 |
| John went to the bedroom | Where is Sandra? | 0.00002 |
Question: Where is Sandra?
Answer: bathroom
Table 2: Test Accuracies on Task 2 Two Supporting Facts
| Story2: Task2 Two Supporting Facts | Question | Memory Hop1 | Memory Hop2 |
| John moved to the hallway | Where is the apple? | 0.00000 | 0.00000 |
| Sandra moved to the kitchen | Where is the apple? | 0.00000 | 0.00000 |
| Daniel traveled to the garden | Where is the apple? | 0.00000 | 0.00000 |
| Mary went back to the office | Where is the apple? | 0.00000 | 1.00000 |
| Mary got the apple there | Where is the apple? | 0.01279 | 0.00000 |
| Mary dropped the apple | Where is the apple? | 0.98721 | 0.00000 |
| Daniel journeyed to the bedroom | Where is the apple? | 0.00000 | 0.00000 |
| Daniel went to the bathroom | Where is the apple? | 0.00000 | 0.00000 |
Question: Where is the apple?
Answer: office
As we can see the higher score helps us to find the answer from these samples.
Endnotes
Shallow networks which use a single hidden layer between the input and output can be implemented for these tasks (Task1 & Task2) and you can find extremely fast training. There are types of memory networks that are harder and complex that do incorporate deeper architectures.
References:
– Jason Weston, Antoine Bordes, Sumit Chopra, Tomas Mikolov, Alexander M. Rush,
The media shown in this article are not owned by Analytics Vidhya and are used at the Author’s discretion.




