This article was published as a part of the Data Science Blogathon
Machine Learning Operations (MLOps) is the primary way to increase the efficiency of Machine Learning workflows. Machine Learning is a big buzzword these days. Everyone seems to be wanting to jump into ML these days. Many new companies and startups implement ML projects in many ways. But only a part of these products is able to run and sustain themselves in the long run.
What is DevOps?
Software needs to be built and run properly. So how does the entire lifecycle of a software product look like?
Well, DevOps makes the entire software operation process smooth. It consists of a set of practices and processes that work together to automate and integrate the whole process of software development.
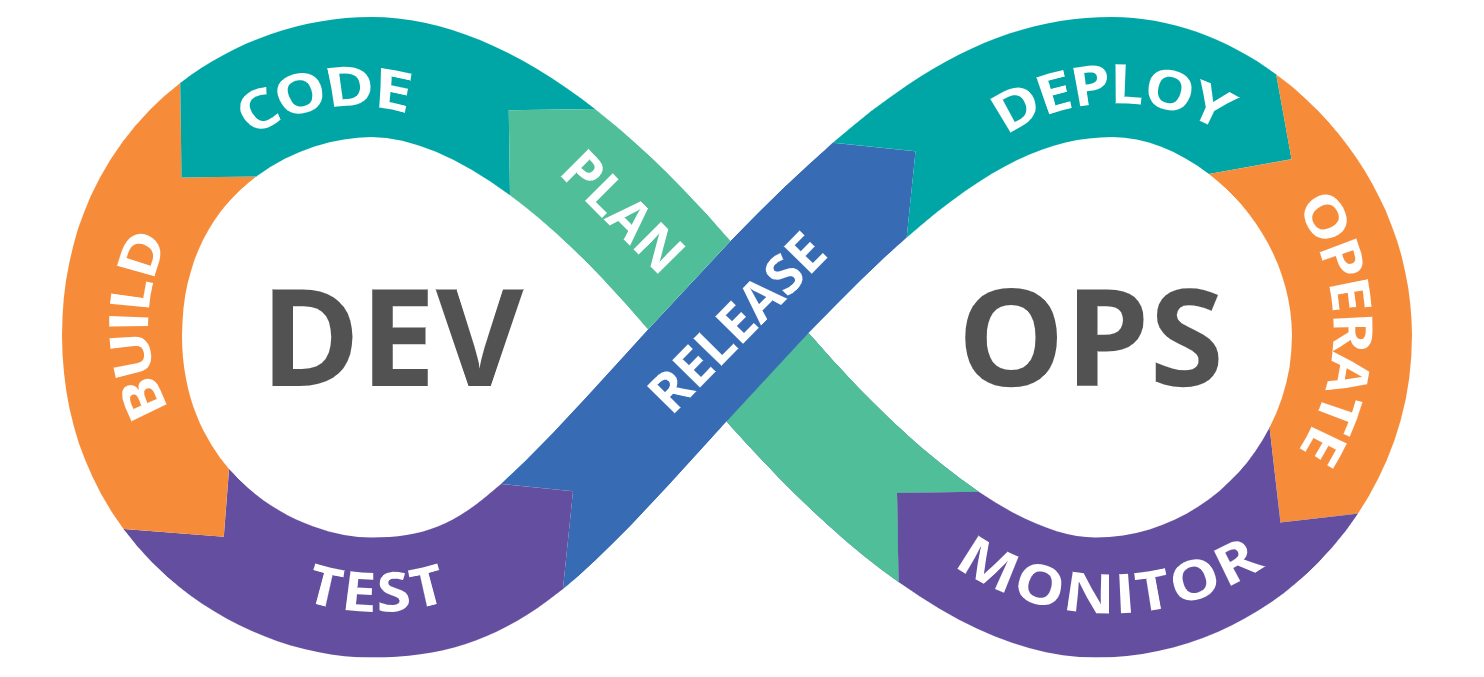
DevOps unifies the process of software development (Dev) and software operation (Ops). DevOps facilitates the automation, monitoring, and smooth operation of software creation, development, integration, testing, deployment, release, upkeep, scaling, maintenance and infrastructure management.
A few key goals of DevOps are short, smooth, and fast development cycles, fast deployment, stable releases and follow the business objectives properly. DevOps advocates and practitioners use the infinity loop art (above) to portray the DevOps cycle to show how each process relates to the other. This also shows how software development and operations are a continuous role. It needs constant collaboration and improvement throughout the whole cycle.
Proper implementation of DevOps allows organizations to get more done. Continuous Integration (CI) and Continuous Delivery ( CD) help organizations see more efficient development and increased deployment frequency. Repair times are reduced, cybersecurity flaws can be easily detected, and facilitate easy experimentation and testing.
So, we can say that DevOps makes the overall process of software engineering easier to implement and maintain.
MLOps: DevOps for Machine Learning
MLOps borrows many of the principles from DevOps in an effort to make the whole ML cycle more efficient and easy to operate. The primary goal of MLOps is to create automated ML pipelines and track the times and other metrics. The pipelines are to be used for multiple iterations in the whole lifecycle of the ML project.
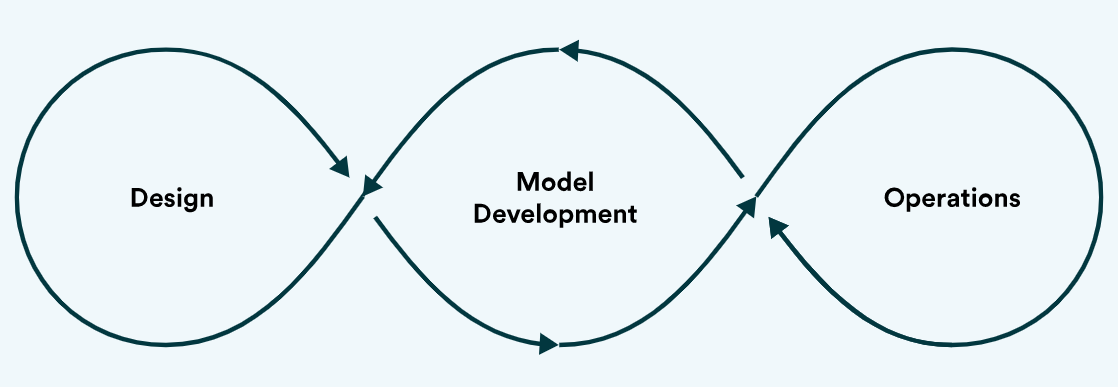
MLOps consists of :
- Design
- Model Development
- Operations
The design phase consists of Requirements Engineering, ML Use cases prioritization, Data Availability check, and other steps.
Model Development has ML Engineering, Model Creation, Data Engineering, and Model testing and validation.
Operations deals with Model Deployment, CI/CD pipelines, and Model monitoring and maintenance.
Let us now look at how the overall MLOps scenario for Azure MLOps looks like.
Microsoft Azure MLOps
Azure MLOps follows the goals of :
- Faster experimentation and development of models
- Faster deployment of models into production
- Quality assurance and end-to-end lineage tracking
MLOps tools help to track changes to the data source or data pipelines, code, SDKs models, etc. The lifecycle is made more easy and efficient with automation, repeatable workflows, and assets that can be reused over and over.
Azure Machine Learning services let us create reproducible Machine Learning pipelines. The software environments for training and deploying models are also reusable. These pipelines let us update models, test new models, and continuously deploy new ML Models.
The Typical ML process
The typical Machine Learning process consists of:
1. Collecting Data
2. Training model
3. Package the model
4. Validate the model
5. Deploy Model
6. Monitor Model
7. Retrain Model
But in many cases, the process needs more refinement. New data is available and the code gets changed. Various processes run, each of which involves a large amount of data.
Usually, a lot of the data is disorganized. The raw data also needs to be conditioned.
How MLOps can help?
MLOps consists of various elements. Some notable elements are Deployment Automation, Monitoring, Framework testing, Data Versioning, etc. MLOps tries to take concepts from DevOps, and make the whole Machine Learning process better.
The whole architecture of Azure Machine Learning looks something like this:
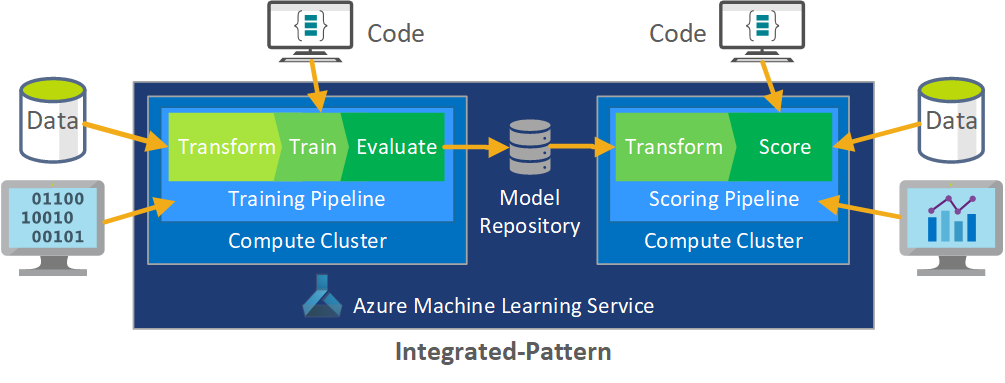
MLOps is supposed to make a coordinated process that can make the whole process flow easier and also support large-scale CI/CD environments.
MLOps can help with automation, making code deployments easy. Validation is also made easy with SWE Quality Control best practices. In the case of model training, if we feel our model needs re-training, we can always go back and do model re-training.
Azure Machine Learning has many domain-specific pre-trained models, like for:
Vision, Speech, Language, Search, etc.
If we talk about, what exactly is Azure ML Services, it is a set of Azure Cloud Services along with a Python/R software development kit, that enables us to prepare data, build models, manage models, train models, track experiments and deploy models.
There are a lot of elements involved, let us look at a few of them.
Datasets: register the data
Experiments: Training runs
Pipelines: Training Workflow
Models: Registered models
Endpoints: deployed model and training workflow endpoints
Compute: Managed compute
Environments: defined training and inference environments
Azure services are built in such a way as to support DevOps and make everything run properly.
Managing the Machine Learning Lifecycle with MLOps is very easy. Models need to be monitored and re-trained. MLOps processes facilitate real business results and thus enable a faster time to market and deployment for ML-based solutions. Collaboration and alignment across the teams are also increased.
Azure MLOps
Azure Machine Learning has the following MLOps features.
Create reproducible ML pipelines
We can define reusable and repeatable pipelines. Steps comprising Data Gathering to Model evaluation, all can be reused.
Reusable Software Environments
The software dependencies of our projects can be tracked and reproduced according to the need.
Register, package, and deploy models from anywhere
The model registry makes the above steps very easy to implement. The models have a name and version.
Capturing the governance data for an end-to-end Machine Learning lifecycle
Azure ML can integrate with Git to track our code. We can check which branch/ repository our code came from. We can also track, profile and version our data.
Alerts and Notifications for events in the ML lifecycle
Azure ML lists key events to Azure EventGrid, which can be used for various purposes.
Monitor the operational issues
We can understand the data that is being sent to our model, and the predictions that are returned. So we can understand how the model is performing.
Automate the ML lifecycle
Azure Pipelines and Github can be used to create an autonomous and continuous integration that trains a model. Most of the steps in the ML Lifecycle can be automated.
So, as an overall thought, we can understand that MLOps is a concept where we use various resources to make the whole ML journey smooth and efficient.
So, thinking of a hypothetical MLOps workflow, first, the Data Science team and the App development team would collaborate to build the app and also train the model. Then, the app is to be tested. Parallelly, the model will be validated. Then, the model will be deployed and the app will be released.
The app and model will be monitored. From the overall process of Model and App management, we can do performance analysis. Based on the needs, we can also retrain the model.
Let us see a sample ML project on Azure DevOps.
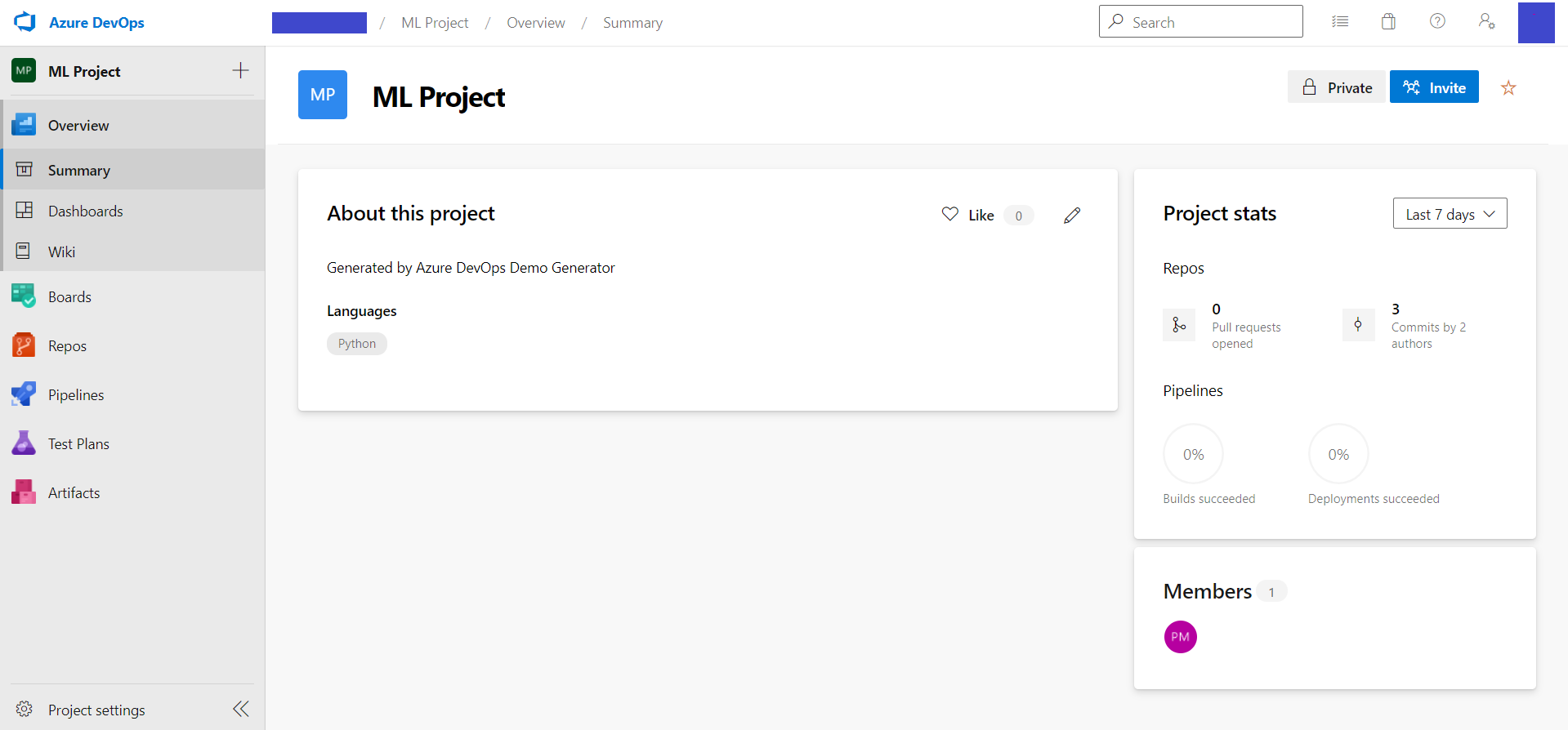
The various elements we had discussed are visible here.
Going into Repos, we can check the code and other files.
Regarding pipelines, let us look at a successfully run pipeline.
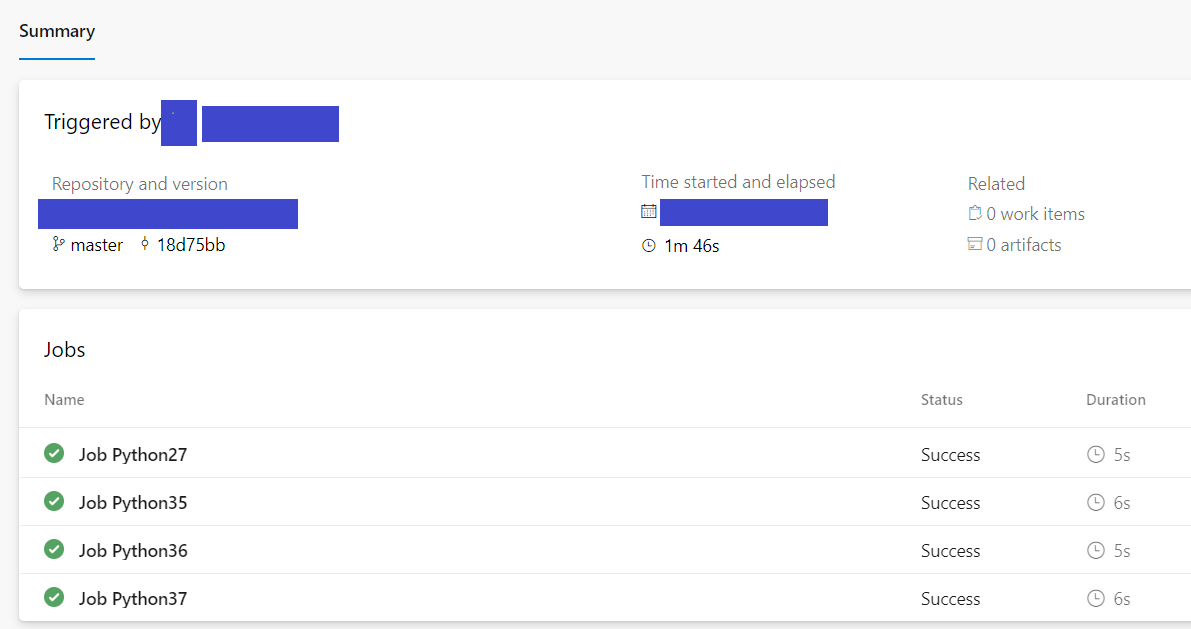
We can see that all the jobs ran successfully.
For the particular sample ML project, we can see the requirements.
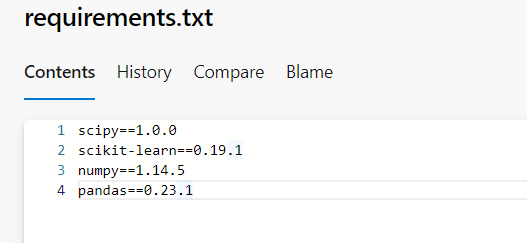
We can implement the requirements.
pip install azure-cli==2.0.69 pip install --upgrade azureml-sdk[cli] pip install -r requirements.txt
Code for training the model:
Start by importing necessary stuff.
import pickle
from azureml.core import Workspace
from azureml.core.run import Run
import os
from sklearn.datasets import load_diabetes
from sklearn.linear_model import Ridge
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
from sklearn.externals import joblib
import numpy as np
import json
import subprocess
from typing import Tuple, List
# run_history_name = 'devops-ai'
# os.makedirs('./outputs', exist_ok=True)
# #ws.get_details()
# Start recording results to AML
# run = Run.start_logging(workspace = ws, history_name = run_history_name)
run = Run.get_submitted_run()
Getting the data.
X, y = load_diabetes(return_X_y=True)
columns = ["age", "gender", "bmi", "bp", "s1", "s2", "s3", "s4", "s5", "s6"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
data = {"train": {"X": X_train, "y": y_train}, "test": {"X": X_test, "y": y_test}}
Next, training.
# Randomly pic alpha
alphas = np.arange(0.0, 1.0, 0.05)
alpha = alphas[np.random.choice(alphas.shape[0], 1, replace=False)][0]
print(alpha)
run.log("alpha", alpha)
reg = Ridge(alpha=alpha)
reg.fit(data["train"]["X"], data["train"]["y"])
preds = reg.predict(data["test"]["X"])
run.log("mse", mean_squared_error(preds, data["test"]["y"]))
# Save model as part of the run history
model_name = "sklearn_regression_model.pkl"
# model_name = "."
with open(model_name, "wb") as file:
joblib.dump(value=reg, filename=model_name)
# upload the model file explicitly into artifacts
run.upload_file(name="./outputs/" + model_name, path_or_stream=model_name)
print("Uploaded the model {} to experiment {}".format(model_name, run.experiment.name))
dirpath = os.getcwd()
print(dirpath)
# register the model
# run.log_model(file_name = model_name)
# print('Registered the model {} to run history {}'.format(model_name, run.history.name))
print("Following files are uploaded ")
print(run.get_file_names())
run.complete()
There are many significant differences in the way we operate here.
I, being a student didn’t exactly have a business case or the monetary resources to work on a full-fledged ML project on Azure DevOps. The above work is done by taking reference.
Please visit this Repo for reference: DevOpsForAI
Conclusion
MLOps can solve a lot of problems related to the Machine Learning life cycle. Hence, many of the overall challenges are also solved.
MLOps is a very compelling proposition for businesses to run their ML models. MLOps makes working across teams very easy and simple.
These are some references I used to gather knowledge for this article. Do have a read.
References:
2. https://docs.microsoft.com/en-us/learn/modules/start-ml-lifecycle-mlops/1-introduction
3. https://docs.microsoft.com/en-us/azure/architecture/example-scenario/mlops/mlops-technical-paper
4. https://docs.microsoft.com/en-us/azure/architecture/reference-architectures/ai/mlops-python
About me:
Prateek Majumder
Data Science and Analytics | Digital Marketing Specialist | SEO | Content Creation
Connect with me on Linkedin.
My other articles on Analytics Vidhya: Link.
Thank You.
Prateek is a dynamic professional with a strong foundation in Artificial Intelligence and Data Science, currently pursuing his PGP at Jio Institute. He holds a Bachelor's degree in Electrical Engineering and has hands-on experience as a System Engineer at TCS Digital, where he excelled in API management and data integration. Prateek also has a background in product marketing and analytics from his time with start-ups like AppleX and Milkie Way, Inc., where he was involved in growth campaigns and technical blog management. Recognized for his structured thinking and problem-solving abilities, he has received accolades like the Dr. Sudarshan Chakraborty Award for Best Student Performance. Fluent in multiple languages and passionate about technology, Prateek continues to expand his expertise in the rapidly evolving AI and tech landscape.




This article is very interesting which is worth reading it . Thanks for information