This article was published as a part of the Data Science Blogathon
Introduction →
This article focuses on answer retrieval from a document by using similarity and difference metrics. This task falls under Natural Language Processing which is a subset of Deep Learning. In this article we will be understanding the concept of general similarity algorithms and how can they be applied to complete our task. The article will be based on python for the coding part.
How to Approach →
To begin with, we must be clear about our problem.
We are trying to retrieve an answer from the document to the given question. For this kind of problem the basic intuition that could strike in your mind would be “Let’s compare the question with each sentence from the given document or text.” This is exactly what we will be doing in this article.
For comparison, we will be needing some metrics to act as a medium. The metrics or similarity-difference techniques that we are going to use are
1. Euclidean Distance
2. Cosine Similarity
These are the most basic and naive approaches to text similarity.
To implement them for our test case, we should first understand what input they take and how they work. Generally, the input given to these metrics is vectors. For representing our sentence into a vector that could be used as input we are using a technique called word embedding which is discussed below.
Word Embedding →
According to Wikipedia, word embedding is
“ The collective name for a set of language modeling and feature learning techniques in natural language processing (NLP) where words or phrases from the vocabulary are mapped to vectors of real numbers. “
Damn!, that was a nice definition but it lacks much-needed insights for the beginners. So a rephrase would be –
Word Embedding is a vector representation of words that allows words with similar meanings to have similar vector representation. Word Embedding tries to capture the context of a word in a document, semantic and syntactic similarity, relation with other words.
Word embeddings are in fact a class of techniques where individual words are represented as real-valued vectors in a predefined vector space. Each word is mapped to one vector and the vector values are learned.
There are various ways of creating word embedding :
1. Bag Of Words
2. TD-IDF
3.GLove
We will be using and focussing on TF-IDF. I will also provide code for the Bag Of Words Technique.
TF-IDF (Term Frequency — Inverse Document Frequency)
Let’s understand TD-IDF lets break it into two parts: TERM FREQUENCY and INVERSE DOCUMENT FREQUENCY.
TERM FREQUENCY — This measures the frequency of a word within a document. This method highly depends on the length of the document. According to term frequency if a word appears more in the document it tends to be more important for the document than the one with lower frequency. To reduce this effect to give weight to each word and to avoid important words take all the light we multiply it with IDF.
INVERSE DOCUMENT FREQUENCY — IDF works by giving weight to the word. weight here means how widely the word is used in the document. The more the word is used the lower will be its IDF.
Multiplying both of them somehow gives a perfect result lowering the effect of both the above-mentioned terms.
TF-IDF = Term Frequency (TF) * Inverse Document Frequency (IDF).
BUT, can we directly jump to word embedding? The answer is No we should first clean the data. Below is the code for cleaning the data.
Let’s say we have a text (From Wikipedia)
txt = "Elon Reeve Musk FRS (/ˈiːlɒn/ EE-lon; born June 28, 1971) is an entrepreneur and business magnate. He is the founder, CEO, and Chief Engineer at SpaceX; early stage investor,[note 1] CEO, and Product Architect of Tesla, Inc.; founder of The Boring Company; and co-founder of Neuralink and OpenAI. A centibillionaire, Musk is one of the richest people in the world. ....... for his other views on such matters as artificial intelligence and public transport."
Library import →
# importing the libraries import numpy as np import nltk import re , math import gensim from gensim.parsing.preprocessing import remove_stopwords from gensim import corpora
Tokenization →
Here we are using sent_tokenize to create tokens i.e. complete paragraphs will be converted to separate sentences and will be stored in the tokens list.
nltk.download('punkt') #punkt is nltk tokenizer
tokens = nltk.sent_tokenize(txt) # txt contains the text/contents of your document.
for t in tokens:
print(t)
Output
['Elon Reeve Musk FRS (/ˈiːlɒn/ EE-lon; born June 28, 1971) is an entrepreneur and business magnate.', 'He is the founder, CEO, and Chief Engineer at SpaceX; early stage investor,[note 1] CEO, and Product Architect of Tesla, Inc.; founder of The Boring Company; and co-founder of Neuralink and OpenAI.', 'A centibillionaire, Musk is one of the richest people in the world.Musk was born to a Canadian mother and South African father and raised in Pretoria, South Africa.', "He briefly attended the University of Pretoria before moving to Canada aged 17 to attend Queen's University.
Cleaning →
clean_sentences performs →
1. remove extra spaces
2. convert sentences to lower case
3. remove stopword
def clean_sentence(sentence, stopwords=False): sentence = sentence.lower().strip() sentence = re.sub(r'[^a-z0-9s]', '', sentence) if stopwords: sentence = remove_stopwords(sentence) return sentence
This function stores cleaned sentences to list cleaned_sentences
def get_cleaned_sentences(tokens, stopwords=False): cleaned_sentences = [] for line in tokens: cleaned = clean_sentence(line, stopwords) cleaned_sentences.append(cleaned) return cleaned_sentences
Output
elon reeve musk frs iln eelon born june 28 1971 entrepreneur business magnate founder ceo chief engineer spacex early stage investornote 1 ceo product architect tesla founder boring company cofounder neuralink openai centibillionaire musk richest people worldmusk born canadian mother south african father raised pretoria south africa briefly attended university pretoria moving canada aged 17 attend queens university .....
Code for Creating Word Embedding
BAG OF WORDS
We are all the unique words in the dictionary were key: unique word and value: count/frequency. Then we are using function doc2bow which is used to create word embedding and storing all the word embedding to the corpus.
sentences = cleaned_sentences
sentence_words = [[word for word in document.split()]
for document in sentences]
dictionary = corpora.Dictionary(sentence_words)
# for key, value in dictionary.items():
# print(key, ' : ', value)
corpus = [dictionary.doc2bow(text) for text in sentence_words]
for sent, embedding in zip(sentences, corpus):
print(sent)
print(embedding)
Output
elon reeve musk frs iln eelon born june 28 1971 entrepreneur business magnate [(0, 1), (1, 1), (2, 1), (3, 1), (4, 1), (5, 1), (6, 1), (7, 1), (8, 1), (9, 1), (10, 1), (11, 1), (12, 1)] founder ceo chief engineer spacex early stage investornote 1 ceo product architect tesla founder boring company cofounder neuralink openai [(13, 1), (14, 1), (15, 1), (16, 2), (17, 1), (18, 1), (19, 1), (20, 1), (21, 1), (22, 2), (23, 1), (24, 1), (25, 1), (26, 1), (27, 1), (28, 1), (29, 1)] ....
The Output contains string and their corresponding embedding in the next line.
TF-IDF
We are using the TfidVectorizer function and then transforming our data.
from sklearn.feature_extraction.text import TfidfVectorizer tfidfvectoriser=TfidfVectorizer() tfidfvectoriser.fit(cleaned_sentences) tfidf_vectors=tfidfvectoriser.transform(cleaned_sentences)
Output
(0, 133) 0.2903579679948088
' '
(17, 55) 0.2867730963228463
(17, 23) 0.25100993149313394
Woah! The first part is completed we have created vectors for our comparison.
Let’s move on to the metrics we are going to use for finding answers in our document.
Euclidean Distance →
The Euclidean distance between two points in n-dimensional space or a plane is the measure of the length of a segment connecting the two points with a straight line.
The Line represented in red is the distance between A and B vectors.
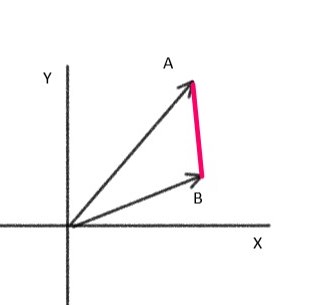
Euclidean distance between points (x,y) and (a,b) is given by
.jpg)
Euclidean distance between 2 n-dimensional vectors X and A would be
.jpg)
We are using this technique to find how much-separated word embedding vectors are from each other. Distance is used for calculating similarity here. This can be understood like, if two vectors are wide apart from each other they are more likely to be different as compared to two which are close to each other.
def Euclidean(self, question_vector: np.ndarray, sentence_vector: np.ndarray):
vec1 = question_vector.copy()
vec2 = sentence_vector.copy()
if len(vec1)<len(vec2): vec1,vec2 = vec2,vec1
vec2 = np.resize(vec2,(vec1.shape[0],vec1.shape[1]))
return np.linalg.norm(vec1-vec2)
In the above algorithm, we are padding a small vector with (0,0) to make their lengths equal. You can understand it like small vectors do not have components in some direction so the value for those components will be 0. Then we are using the norm function to find the distance between the two vectors.
This one was easier than word embedding. It’s time to move on to the most popular metrics for similarity — Cosine Similarity.
Cosine Similarity →
Cosine Similarity measures the cosine of the angle between two non-zero n-dimensional vectors in an n-dimensional space. The smaller the angle the higher the cosine similarity. Cosine similarity captures the orientation of the vectors and does not measure the difference in magnitude of vectors. This means that we are only trying to find how much close two vectors are to each other in terms of looks not in their magnitude.
The formula for cosine similarity →
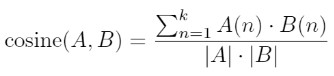
Image from paper
Values of similarity (A, B) ranges from -1 to 1, where -1 represents perfectly dissimilar and 1 represents perfectly similar.
How does cosine similarity work?
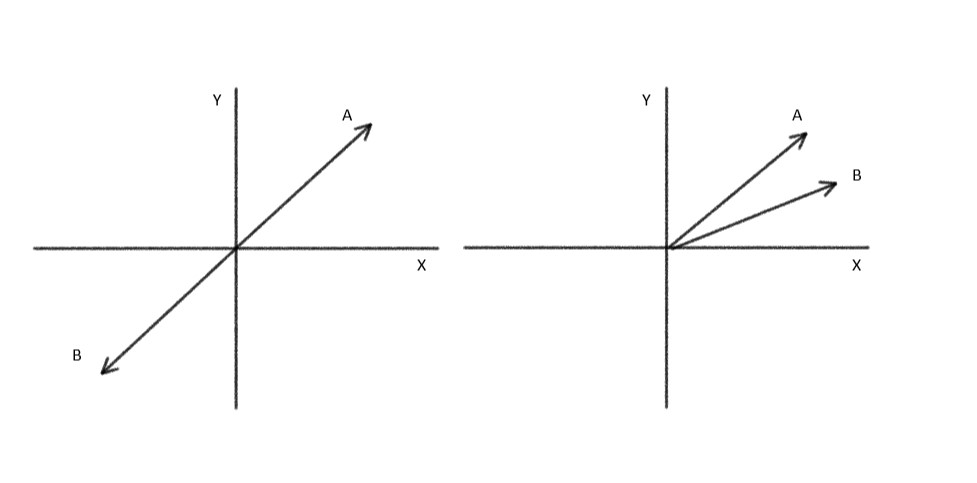
In image 1 we can clearly see two vectors are opposite in direction and the same is true for their cosine angle cos(180⁰) = -1. Now let’s see case 2 we can see the angle between vectors is small let’s assume it 30⁰ our cosine angle value will be somewhere around 0.866 which is higher than case 1. This is the same conclusion that we draw from the above images we can see that the two vectors are which are opposite in direction obviously mean that they are less similar than the two vectors in case 2.
Show me the CODE
def Cosine(self, question_vector: np.ndarray, sentence_vector: np.ndarray):
dot_product = np.dot(question_vector, sentence_vector.T)
denominator = (np.linalg.norm(question_vector) * np.linalg.norm(sentence_vector))
return dot_product/denominator
In the above code, we first found the dot product and saved it to variable dot_product. We have used .T to create the transpose of the vector. Because dot product can only be done when two vectors are of form n*m and m*x where n*m and m*x are dimensions of the vectors. For the denominator part, we have used the norm function to calculate the magnitude and put that into the cosine formula.
This code will work with both the techniques i.e. TF-IDF and BOW.
Algorithmic Pipeline→
1. Convert paragraph into sentences metrics.
2. Cleaning the data.
3. Conversion of sentences to corresponding word embedding
4. Conversion of question into the word embedding
5. Apply Euclidean distance / Cosine Similarity
6. Put the results in heap with index.
7. Pop and Print the result.
We will create and store word embedding for the document in the matrix so that it can be utilized for answering the different questions from the same document. Every time we change a question its corresponding word embedding will change but the word embedding of our complete document will remain the same.
That was enough with the explanation. Let’s have a look at the proper code.
Kaggle –> Click Here (Like and Comment)
Github –> Click Here (Give it a Star)
More similar the words in question to document better will be the accuracy.
EndNote →
These techniques are basic techniques and can only be used for learning purposes. They can also be used for solving problems like fill-in-the-blanks or to solve comprehensions with High Accuracy.
For advanced techniques, you might have to go for BERT or similar models which requires a lot of computational costs but gives quite a high accuracy. I will be sharing the Advanced similarity technique in the upcoming blog so STAY TUNED. There are certain tricks to increase accuracy such as you can try to use as similar words in question as possible. You can use this model to create other projects like Plagiarism Checker.
Hope You Liked This Article.
Thank You for Your precious time.
About Author →
The media shown in this article are not owned by Analytics Vidhya and are used at the Author’s discretion.






Thanks for intuitive explanation , i would like to ask question suppose i have 5 documents and query of one sentence and i want to find which documents this query is most similar then how i could do this