Offline Data Augmentation for multiple images
This article was published as a part of the Data Science Blogathon
Introduction
Can you increase the number of images in any dataset? Of course, you can, using data augmentation.
Machine learning, Deep learning, Artificial intelligence all require large amounts of data. However, data is not always available in every case. The programmer needs to work with the small amount of data available. Hence the use of data augmentation came into the picture. This blog provides a clear analysis of data augmentation and also the code to implement it.
Data augmentation can be defined as the technique used to improve the diversity of the data by slightly modifying copies of already existing data or newly create synthetic data from the existing data. It is used to regularize the data and it also helps to reduce overfitting. Some of the techniques used for data augmentation are :
1. Rotation ( range 0-360 degrees)
2. flipping (true or false for horizontal flip and vertical flip )
3. Shear range (image is shifted along x-axis or y-axis)
4. Brightness or Contrast range ( image is made lighter or darker)
5. Cropping ( resize the image )
6. Scale ( image is scaled outward or inward )
8. Saturation ( depth or intensity of the image)
The application of Data augmentation plays a crucial role while training the machine learning model. There are mainly three ways in which data augmentation techniques can be applied. They are:
1. Offline data augmentation
2. Online data augmentation
3. Combination of both online and offline data augmentation
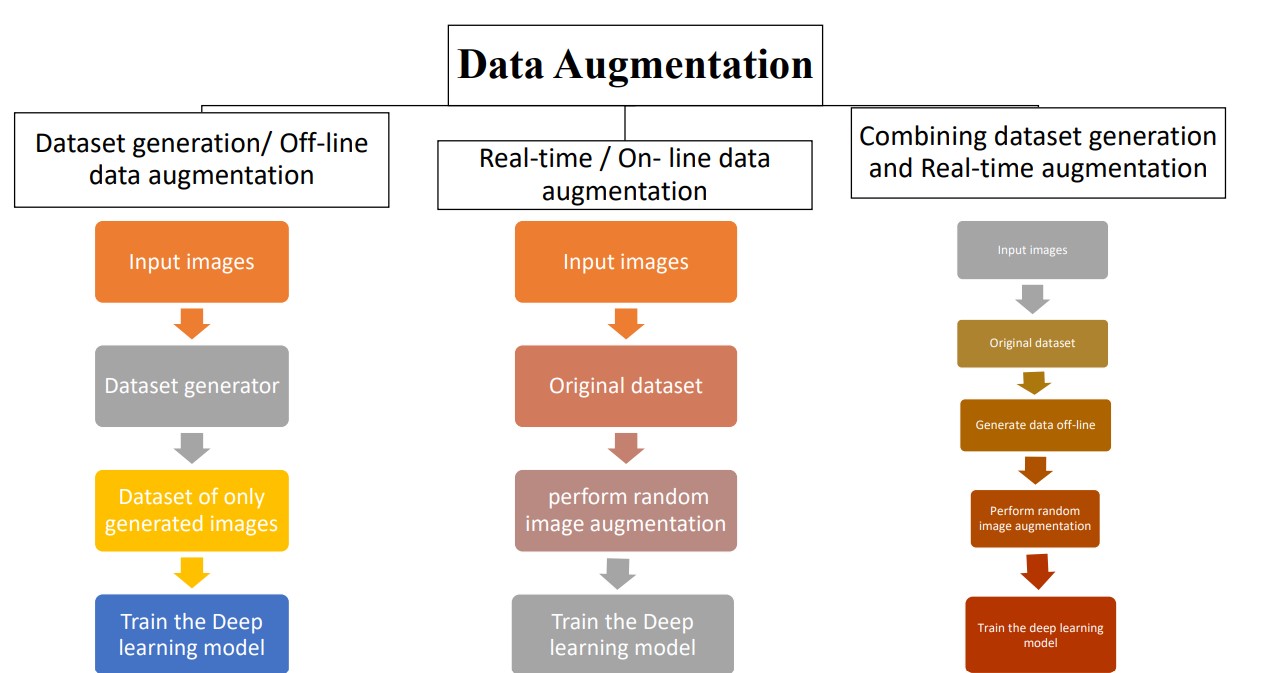
Online data augmentation:
The default data augmentation used in machine learning models is online data augmentation, where the images from training data are taken at random and the data augmentation techniques are applied. The model is then trained based on the original data where the images are randomly augmented. In this case, the augmented images are never saved anywhere and it is impossible to know which image is augmented.
Deep learning models already use online data augmentation like rotation, flipping, shear, brightness range, etc.., these are randomly applied to the training data before fitting the model. This technique doesn’t save any data on the disk and preprocess images in real-time.
Offline data augmentation:
Dataset generation or offline data augmentation allows the programmer to save the augmented images on the disk. The techniques that can be used to perform online data augmentation can be used to perform offline data augmentation, where the images are stored on the disk hence, it is called offline data augmentation. Augmented images are obtained after applying the data augmentation techniques on each and every training image. This makes the dataset more diverse and the model more robust. This process can be used to improve the number of images in the dataset.
Combination of both online and offline data augmentation:
As the name suggests, in this case, both ways are employed for analyzing the data. The augmented images obtained are mixed with the original dataset and then real-time data augmentation is done just before training the machine learning model. This method is generally used for gaming purposes or when the data available is unclear. In the case of the third type of data augmentation, the techniques are applied in both offline and online modes. The images are stored on the disk during offline data augmentation, then they are mixed with the original dataset and online data augmentation is applied.
Data augmentation can be applied to a single image or multiple images at once. An infinite amount of images can be produced using data augmentation. The example below shows the result of data augmentation if it is applied to a single image.
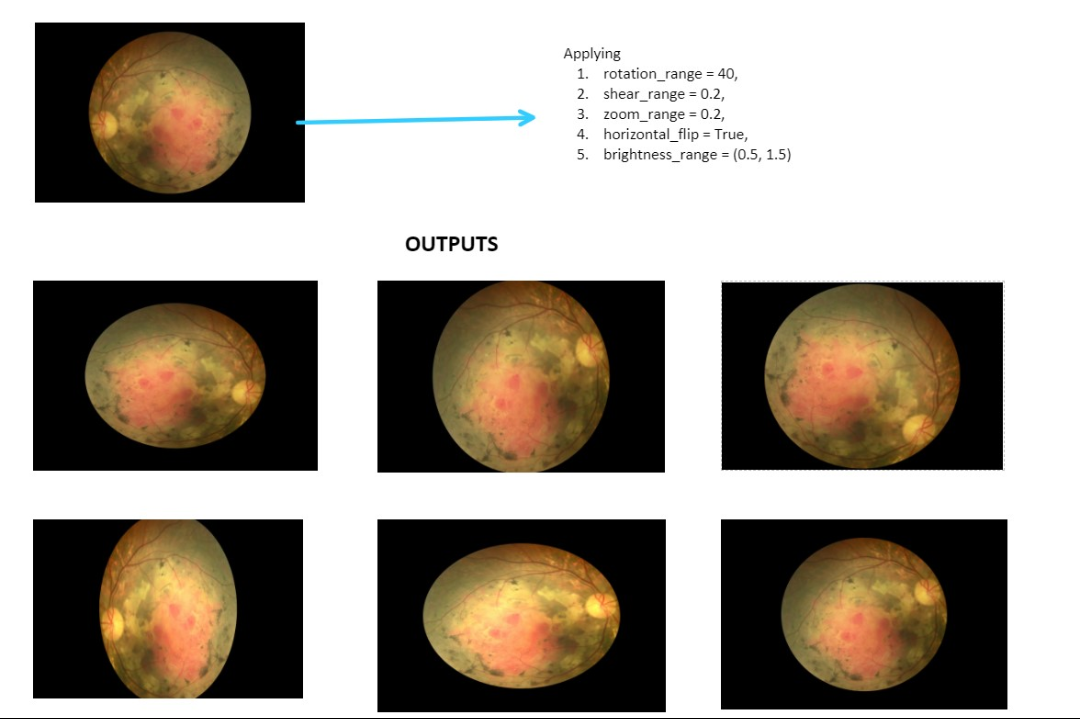
As shown above, One image can be used to produce five images. These images are obtained by slightly modifying the existing image. The detailed code for data augmentation of multiple images taken from a folder is as follows:
from keras.preprocessing.image import ImageDataGenerator
from skimage import io
datagen = ImageDataGenerator(
rotation_range = 40,
shear_range = 0.2,
zoom_range = 0.2,
horizontal_flip = True,
brightness_range = (0.5, 1.5))
import numpy as np
import os
from PIL import Image
image_directory = r'C:Users---train/'
SIZE = 224
dataset = []
my_images = os.listdir(image_directory)
for i, image_name in enumerate(my_images):
if (image_name.split('.')[1] == 'jpg'):
image = io.imread(image_directory + image_name)
image = Image.fromarray(image, 'RGB')
image = image.resize((SIZE,SIZE))
dataset.append(np.array(image))
x = np.array(dataset)
i = 0
for batch in datagen.flow(x, batch_size=16,
save_to_dir= r'C:Users---Augmented-images',
save_prefix='dr',
save_format='jpg'):
i += 1
if i > 50:
break
Image data generator is imported from Keras for implementing data augmentation on the training data. Other modules like ‘os’, ‘numpy’, ‘io’, Image are imported for implementing the code. The augmentation techniques are then applied to each and every image which are later saved into the directory specified by the programmer. The “image_directory” takes the path for the original dataset, and the “size” determines the size of the images in the dataset. The “save_prefix” is used to name the augmented images and “save_format” determines the format of the augmented images, they can be jpeg, png, tiff, etc.,
The code when executed saves the images into a new folder names ‘Augmented-images’ the images are named ‘dr’ and saved in ‘JPEG’ format. This code can be used in many areas where the data is unclear or insufficient. The ‘if’ loop is used to determine the number of times the ‘for’ loop needs to be iterated.
The augmented images can sometimes be unclear due to repeated processing. There are other techniques for denoising the images. But this is the easiest way of increasing the data without the probable case of overfitting the machine learning model.
The process of data augmentation provides diversity to the data and also makes the deep learning model robust. So that the model does not have to depend on only clear and correct data all the time.
End Notes
To summarize, This blog is used purely to show how data augmentation can be used to increase the amount of data while retaining its quality. Data augmentation is an excellent technique when the dataset is inadequate. Though the deep learning models use online data augmentation, the offline mode increases the data exponentially and makes the model robust. It regularizes the diversity of data and reduces the risk of overfitting the model. Different transfer learning models or deep learning models can be applied and comparisons can be done. I will suggest you use offline data augmentation for your next image processing projects and leave your comments.
The media shown in this article are not owned by Analytics Vidhya and are used at the Author’s discretion.







