“Just as athletes can’t win without a sophisticated mixture of strategy, form, attitude, tactics, and speed, performance engineering requires a good collection of metrics and tools to deliver the desired business results.”— Todd DeCapua
Introduction:
Over the years, the adoption of machine learning for driving business decisions has been increasing exponentially. According to Forbes, ML is projected to grow to $30.6B by 2024 and it is not surprising to see the plethora of custom-made ML solutions invading the market addressing specific business needs. The ease of availability of Computing powers, Infrastructure, and Automation on the cloud has accelerated this further.
The current trend of leveraging the powers of ML in business has made data scientists and engineers design innovative solutions/services and one such service have been Model As A Service (MaaS). We have used many of these services without the knowledge of how it was built or served on web, some examples include data visualization, facial recognition, natural language processing, predictive analytics and more. In short, MaaS encapsulates all the complex data, model training & evaluation, deployment, etc, and lets customers consume it for their purpose.
As simple as it feels to use these services, there are many challenges in building such a service e.g.: how do we maintain the service? How do we ensure our model’s accuracy does not dip over time? etc. As with any service or application, one major factor to consider is the load or traffic that a service/API can handle to ensure its uptime. The best feature of API is to have great performance and the only way to test this is by putting API under stress to see how it responds. This is load testing.
In this blog, we will not only look into how such a service is built but also how to load test the service to plan for hardware/infrastructure requirements in the production environment. We will go about achieving this in the following order:
- Build a simple API with FastAPI
- Build a classification model in python
- Wrap the model with FastAPI
- Test the API with Postman client
- Load test with Locust
Let’s get started !!
Creating a simple web API using FastAPI:
The following code shows the basic implementation of FastAPI. The code is used to create a simple Web-API which upon receiving a particular input produces a specific output. Here is the break up of code:
- Load the libraries
- Create an app object
- Create a route with @app.get()
- Write a driver function that has a host and port number defined
from fastapi import FastAPI, Request
from typing import Dict
from pydantic import BaseModel
import uvicorn
import numpy as np
import pickle
import pandas as pd
import json
app = FastAPI()
@app.get("/")
async def root():
return {"message": "Built with FastAPI"}
if __name__ == '__main__':
uvicorn.run(app, host='127.0.0.1', port=8000)
Once executed, you can navigate to the browser with the URL: http://localhost:8000 and observe the result which in this case will be ‘ Built with FastAPI ‘
Creating an API from an ML model using FastAPI:
Now that you have a fair idea of FastAPI, let’s see how you can wrap a machine learning model (developed in Python) into an API in Python. I will use the Breast Cancer Wisconsin (Diagnostic) Data Set. The objective of this ML project is to predict whether a person has a benign or malignant tumor. I will be using VSCode as my editor and note that we will be testing our service with Postman Client. Here are the steps we will follow.
- We will first build our classification model – KNeighborsClassifier()
- Build our server file which will have logic for API in the FlastAPI framework.
- Finally, we will test our service with Postman
Step 1: Classification Model
A simple classification model with the standard process of load data, splitting data in train/test, followed by model building and saving the model in the pickle format on the drive. I am not getting into the details of the model building as the article is about load testing.
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
import joblib, pickle
import os
import yaml
# folder to load config file
CONFIG_PATH = "../Configs"
# Function to load yaml configuration file
def load_config(config_name):
"""[The function takes the yaml config file as input and loads the the config]
Args:
config_name ([yaml]): [The function takes yaml config as input]
Returns:
[string]: [Returns the config]
"""
with open(os.path.join(CONFIG_PATH, config_name)) as file:
config = yaml.safe_load(file)
return config
config = load_config("config.yaml")
#path to the dataset
filename = "../../Data/breast-cancer-wisconsin.csv"
#load data
data = pd.read_csv(filename)
#replace "?" with -99999
data = data.replace('?', -99999)
# drop id column
data = data.drop(config["drop_columns"], axis=1)
# Define X (independent variables) and y (target variable)
X = np.array(data.drop(config["target_name"], 1))
y = np.array(data[config["target_name"]])
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=config["test_size"], random_state= config["random_state"]
)
# call our classifier and fit to our data
classifier = KNeighborsClassifier(
n_neighbors=config["n_neighbors"],
weights=config["weights"],
algorithm=config["algorithm"],
leaf_size=config["leaf_size"],
p=config["p"],
metric=config["metric"],
n_jobs=config["n_jobs"],
)
# training the classifier
classifier.fit(X_train, y_train)
# test our classifier
result = classifier.score(X_test, y_test)
print("Accuracy score is. {:.1f}".format(result))
# Saving model to disk
pickle.dump(classifier, open('../../FastAPI//Models/KNN_model.pkl','wb'))
You can access the entire code from Github
Step 2: Build API using FastAPI:
We will build on top of the basic example that we did in an earlier section
Load the libraries:
from fastapi import FastAPI, Request from typing import Dict from pydantic import BaseModel import uvicorn import numpy as np import pickle import pandas as pd import json
Load the saved KNN model and write a routing function to return the Json:
app = FastAPI()
@app.get("/")
async def root():
return {"message": "Hello World"}
# Load the model
# model = pickle.load(open('../Models/KNN_model.pkl','rb'))
model = pickle.load(open('../Models/KNN_model.pkl','rb'))
@app.post('/predict')
def pred(body: dict):
"""[summary]
Args:
body (dict): [The pred methos takes Response as input which is in the Json format and returns the predicted value from the saved model.]
Returns:
[Json]: [The pred function returns the predicted value]
"""
# Get the data from the POST request.
data = body
varList = []
for val in data.values():
varList.append(val)
# Make prediction from the saved model
prediction = model.predict([varList])
# Extract the value
output = prediction[0]
#return the output in the json format
return {'The prediction is ': output}
# 5. Run the API with uvicorn
# Will run on http://127.0.0.1:8000
if __name__ == '__main__':
"""[The API will run on the localhost on port 8000]
"""
uvicorn.run(app, host='127.0.0.1', port=8000)
You can access the entire code from Github.
Using Postman Client:
In our previous section, we built a simple API where on hitting the http://localhost:8000 on browser we got an output message “Built with FastAPI”. This is fine as long as the output is simpler and there is input from the user or system is expected. But, we are building a model as a service where we send data as input for the model to predict. In such a case, we will need a better to and easier way to test it. We will use postman to test our API.
- Run the server.py file
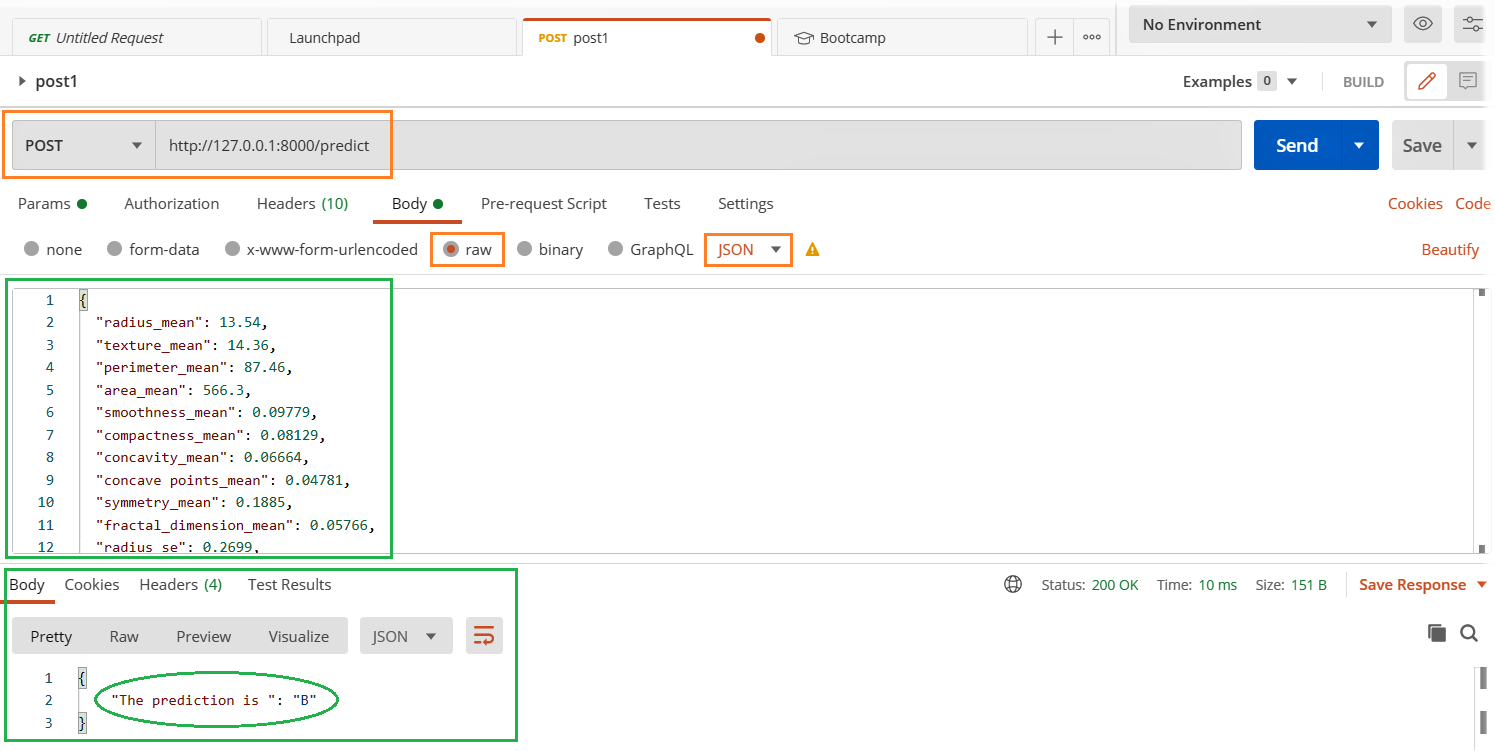
- Open the Postman client and fill in the relevant details which are highlighted below and hit the send button.
- Notice the result in the response section below.
Are your Apps and services stable under peak load?
Time for load test:
We will be exploring Locust library for load testing and the easiest way to install Locust is
pip install locust
Let us create a perf.py file with the below code. I have referred to the code quick start page of locust
import time
import json
from locust import HttpUser, task, between
class QuickstartUser(HttpUser):
wait_time = between(1, 3)
@task(1)
def testFlask(self):
load = {
"radius_mean": 13.54,
"texture_mean": 14.36,
......
......
"fractal_dimension_worst": 0.07259}
myheaders = {'Content-Type': 'application/json', 'Accept': 'application/json'}
self.client.post("/predict", data= json.dumps(load), headers=myheaders)
Access the complete code file from Github
Start Locust: Navigate to the directory of perf.py and run the below code.
locust -f perf.py
Locust Web Interface:
Once you’ve started Locust using the above command, navigate to a browser and point it to http://localhost:8089. You should see the below page:
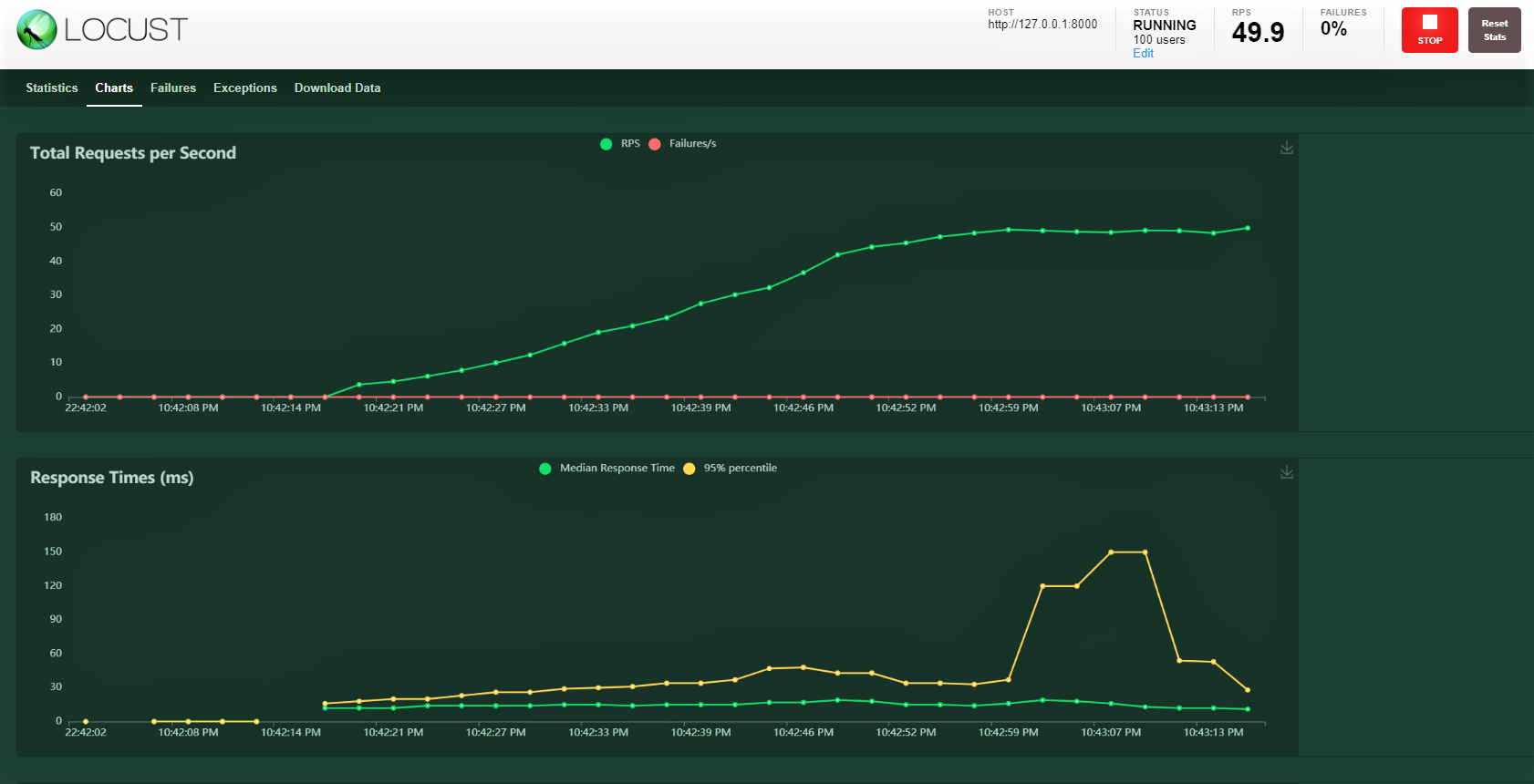
Let’s try 100 users, Spawn ratio of 3, and host: http:127.0.0.1:8000 where our API is running. You can see the below screen. You can see the increasing load over time and the response time, a graphical representation shows the median time and other metrics.
Note: Ensure that server.py is running.

Conclusion:
We covered quite a bit in this blog from building a model, wrapping it up with a FastAPI, testing the service with the postman, and finally carrying out a load test with 100 simulated users hitting our service with gradually increasing load. We were able to monitor how the service is responding.
Most of the time there are business level SLAs to be met i.e., maintain a certain threshold for a response time like 30ms or 20ms. If SLA’s are not met then there are potential financial implications depending on the contract or losing customers as they didn’t get the service fast enough.
A load test helps us understand the peak and potential failure points. We can then plan for proactive action by increasing our hardware capacity and if the service is deployed on Kubernetes kind of set up then configure it to increase the number of pods on increase in load.
Happy learnings !!!!
You can connect with me – Linkedin
You can find the code for reference – Github
References
https://docs.locust.io/en/stable/quickstart.html
https://fastapi.tiangolo.com/
https://unsplash.com/
The media shown in this article are not owned by Analytics Vidhya and are used at the Author’s discretion.
I am a Data Science enthusiast with experience in building predictive models, data processing, and data mining algorithms to solve challenging business problems. Involved in open source community and passionate about building data apps.



