This article was published as a part of the Data Science Blogathon
Introduction
NLP or Natural Language Processing is an exponentially growing field. In the “new normal” imposed by covid19, a significant proportion of educational material, news, discussions happen through digital media platforms. This provides more text data available to work upon!
Originally, simple RNNS (Recurrent Neural Networks) were used for training text data. But in recent years there have been many new research publications that provide state-of-the-art results. One of such is BERT! In this blog, I’ll put down my understanding of the BERT transformer and its application.
BERT stands for Bidirectional Encoder Representations from Transformers. I’ll give a brief idea about transformers first before proceeding further.

Source: Image
Intro to Transformers
BERT is a transformer-based architecture.
What is a transformer?
Google introduced the transformer architecture in the paper “Attention is All you need”. Transformer uses a self-attention mechanism, which is suitable for language understanding.
The need for attention can be understood with a simple example. Let’s say “I went to Horsley hills this summer and it was pretty well developed considering the last time I was there”. The last word “there” refers to the Horsley hills. But to understand this, remembering the first few parts is essential. To achieve this, the attention mechanism decides at each step of an input sequence which other parts of the sequence are important. In simple words, “You need context!”.
The transformer has an encoder-decoder architecture. They are composed of modules that contain feed-forward and attention layers. The below image is from the research paper.
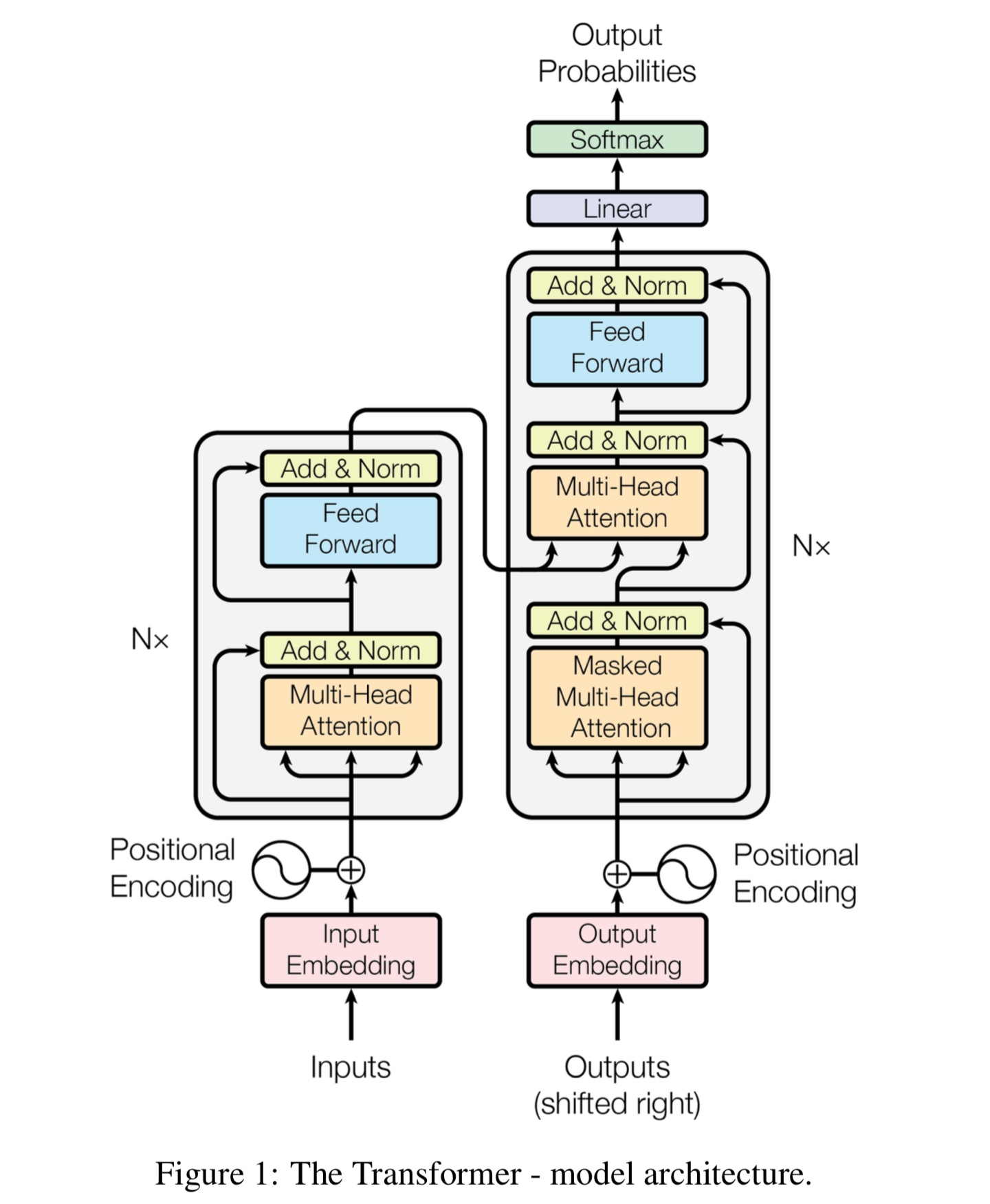
Source: https://arxiv.org/pdf/1706.03762.pdf
What is the need for BERT?
Generally, language models read the input sequence in one direction: either left to right or right to left. This kind of one-directional training works well when the aim is to predict/generate the next word.
But in order to have a deeper sense of language context, BERT uses bidirectional training. Sometimes, it’s also referred to as “non-directional”. So, it takes both the previous and next tokens into account simultaneously. BERT applies the bidirectional training of Transformer to language modeling, learns the text representations.
Note that BERT is just an encoder. It does not have a decoder. The encoder is responsible for reading text input and processing. The decoder is responsible for producing a prediction for the task.
Architecture of BERT
BERT is a multi-layered encoder. In that paper, two models were introduced, BERT base and BERT large. The BERT large has double the layers compared to the base model. By layers, we indicate transformer blocks. BERT-base was trained on 4 cloud-based TPUs for 4 days and BERT-large was trained on 16 TPUs for 4 days.
- BERT base – 12 layers, 12 attention heads, and 110 million parameters.
- BERT Large – 24 layers, 16 attention heads and, 340 million parameters.
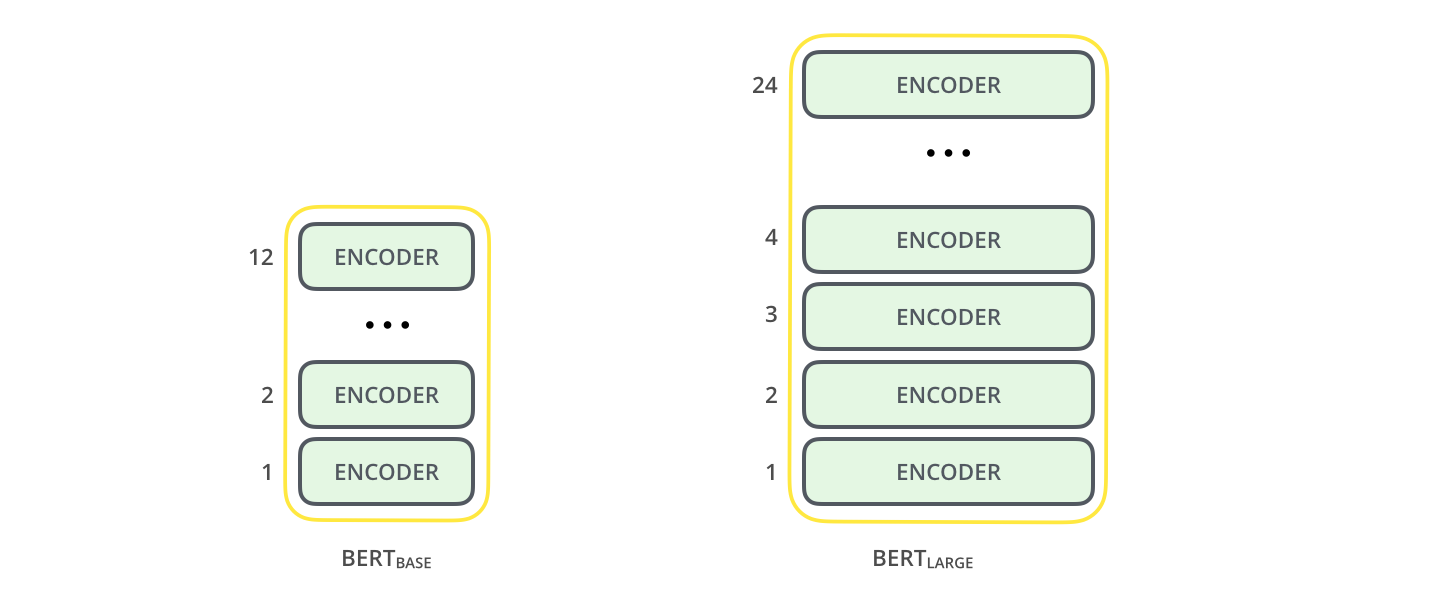
Source: Bert illustration
As you can see from the above image, the BERT base is a stack of 12 encoders. Each of them is a transformer block. The input has to be provided to the first encoder.
The BERT encoder expects a sequence of tokens. The below image shows how tokens are processed and converted. [CLS] is a special token inserted at the beginning of the first sentence. [SEP] is inserted at the end of each sentence. We created segment embeddings by adding a segment ‘A’ or ‘B’ to distinguish between the sentences. We also add the position of each token in the sequence to get position embeddings.
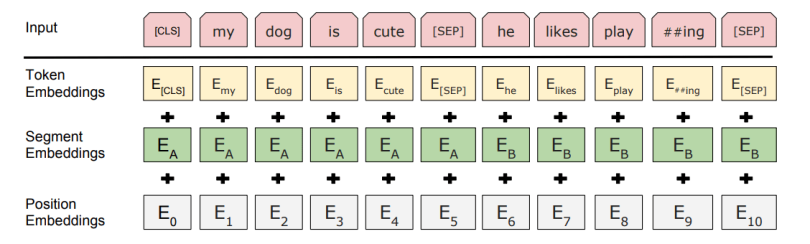 Source: Researchgate
Source: Researchgate
The sum of the above three embeddings is the final input to the BERT Encoder.
BERT takes an input sequence, and it keeps traveling up the stack. At each block, it is first passed through a Self Attention layer and then to a feed-forward neural network. It is passed on to the next encoder. In the end, Each position will output a vector of size hidden_size (768 in BERT Base). This is our word embedding.
How was BERT trained?
Now, let’s ponder on the main question: How does BERT achieve bidirectional training?
It uses two methods: MLM (Masked LM) and NSP (Next Sentence Prediction)
-
MLM (Masked Language Modelling)
In the sequence, we randomly mask some percentage of words, by replacing them with token [MASK]. In the paper, they had masked 15% of input words. It is trained to predict these masked words using the context from the remaining words
Example: ” I love cycling during the spring season” –> I love cycling during the [MASK] season.
A problem here is that the pretrained models will have 15% masked tokens, but when we fine-tune pretrained models and pass input, we don’t pass masked tokens. To tackle this issue, out of the 15% of the tokens selected for masking: 80% – are actually replaced with the token [MASK], 10% of the time tokens are replaced with a random token, and the rest are left unchanged
-
Next Sentence Prediction (NSP)
To understand the relationship between two sentences, BERT uses NSP training. The model receives pairs of sentences as input, and it is trained to predict if the second sentence is the next sentence to the first or not. During training, we provide 50-50 inputs of both cases. The assumption is that the random sentence will be disconnected from the first sentence in contextual meaning.
Text Classification using BERT
Now, let’s see a simple example of how to take a pretrained BERT model and use it for our purpose.
First, install the transformers library.
pip3 install transformers
The Scikit-learn library provides some sample datasets to learn and use. I’ll be using the Newsgroups dataset.
from sklearn.datasets import fetch_20newsgroupsfrom sklearn.model_selection import train_test_split
Basically, all the news article text would be categorized into 20 groups. It’s a multi-class Text Classification problem. The next step is to choose from the many pretrained models available at https://huggingface.co/models?filter=text-classification
The details about the popular models:
BERT-Base, Uncased: 12-layers, 768-hidden, 12-attention-heads, 110M parametersBERT-Large, Uncased: 24-layers, 1024-hidden, 16-attention-heads, 340M parametersBERT-Base, Cased: 12-layers, 768-hidden, 12-attention-heads , 110M parametersBERT-Large, Cased: 24-layers, 1024-hidden, 16-attention-heads, 340M parameters
Choose the model and also fix the maximum length for the input sequence/sentence. If you set the max_length very high, you might face memory shortage problems during execution.
model_name = "bert-base-uncased" max_length = 512
BERT also provides tokenizers that will take the raw input sequence, convert it into tokens and pass it on to the encoder.
from transformers import BertTokenizerFast
tokenizer = BertTokenizerFast.from_pretrained(model_name, do_lower_case=True)
Let us prepare the data.
dataset = fetch_20newsgroups(subset="all", shuffle=True, remove=("headers","footers", "quotes")) target_names=dataset.target_names news_text = dataset.data labels = dataset.target (train_texts,valid_texts,train_labels,valid_labels)=train_test_split(news_text, labels, test_size=0.3) from transformers import BertTokenizerFast, BertForSequenceClassification
The labels range from 0 to 19, each for a particular group whose names are stored in target names. Next, encode the inputs using a tokenizer
train_encodings = tokenizer(train_texts, truncation=True, padding=True, max_length=max_length)
Next, wrap these encoding in a dataset and use the Trainer for training
model=BertForSequenceClassification.from_pretrained(model_name, num_labels=len(target_names))
from transformers import Trainer, TrainingArguments
training_args = TrainingArguments(
num_train_epochs=10,
per_device_train_batch_size=16, # batch size per device during training
weight_decay=0.01, # strength of weight decay
load_best_model_at_end=True,
logging_steps=200,
evaluation_strategy="steps",
)
You can provide the arguments as per your choice.
trainer = Trainer( model=model,args=training_args,train_dataset=train_datasetataset) trainer.train()
Now you can pass any new text to the model in the form of tokens and get the prediction.
Comparison with similar Transformers
Similar to BERT, there are other transformer models which have also proven to achieve state-of-the-art results. Some transformers like Roberta try to improve upon BERT. The below table summarizes the most popular transformer models currently.
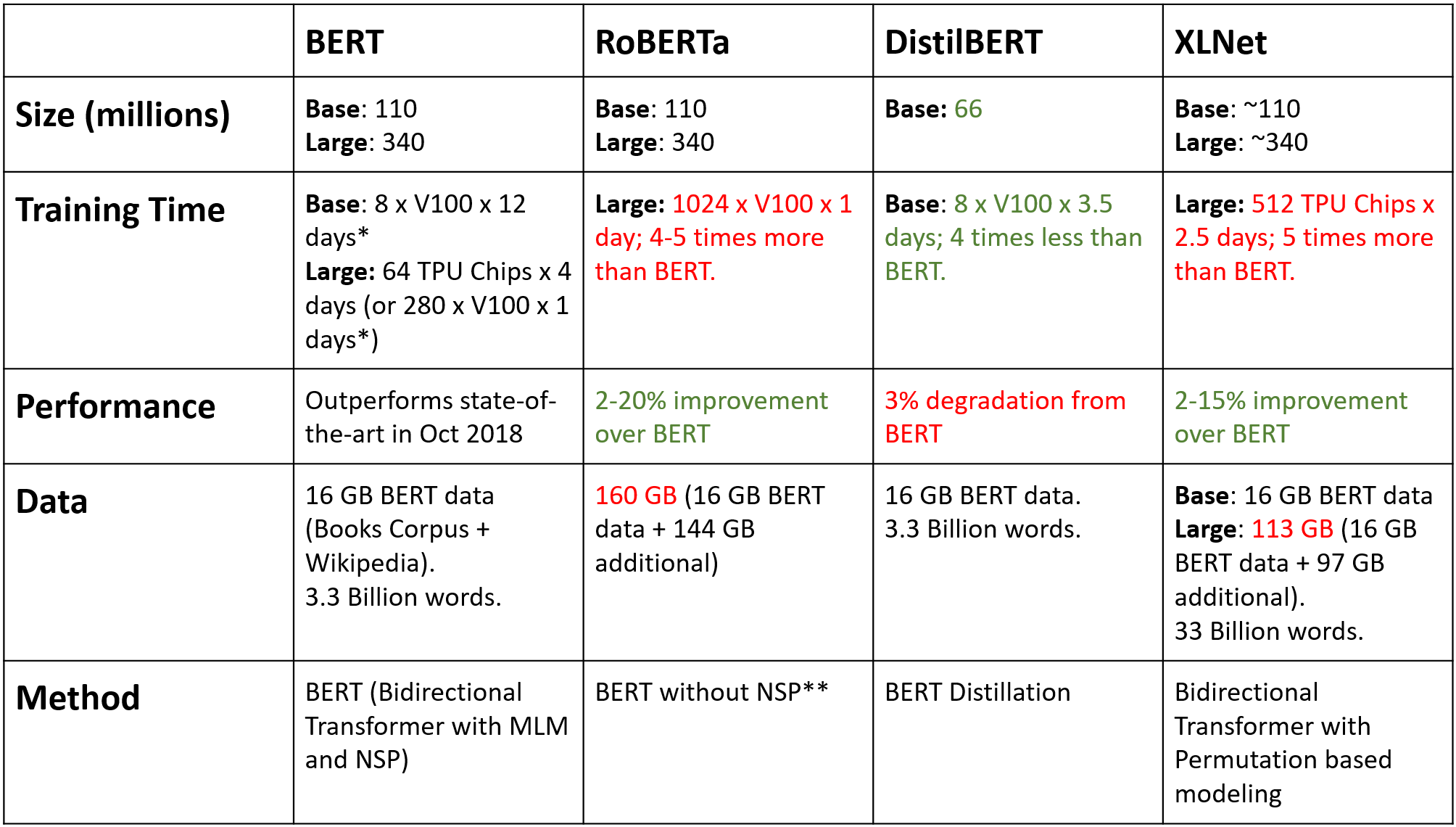
Source: article
Along with these, GPT models have proven highly efficient in conversational tasks. Fun fact, GPT-3’s highest edition has a whopping 175B parameters! The architecture is based on the Transformer’s decoder block. It has a masked self-attention mechanism.
The XLNet model introduces permutation language modeling. Here, all tokens are predicted but in random order. This is different than just trying to predict 15% of masked tokens.
The DistilBERT model is a lighter, cheaper, and faster version of BERT. Here, the model is trained with 97% of the BERT’s ability but 40% smaller in size (66M parameters compared to BERT-based’s 110M) and 60% faster.
In RoBERTa, they got rid of Next Sentence Prediction during the training process. They changed the masked tokens in between training epochs and used different hyperparameters to achieve better results in terms of accuracy.
Depending upon the need for your task, you can choose one of these!
Thanks for reading!
Boost your NLP text classification with the power of BERT – enroll in our ‘BERT for Text Classification‘ course and unlock a new era of accuracy and performance!
You can connect with me through email: [email protected]
The media shown in this article are not owned by Analytics Vidhya and are used at the Author’s discretion.





How do you create the train_dataset for the Trainer?
How did you create the train_dataset for the Trainer?