This article was published as a part of the Data Science Blogathon
Introduction
Scikit-Learn, also known as sklearn is a python library to implement machine learning models and statistical modelling. Through scikit-learn, we can implement various machine learning models for regression, classification, clustering, and statistical tools for analyzing these models. It also provides functionality for dimensionality reduction, feature selection, feature extraction, ensemble techniques, and inbuilt datasets. We will be looking into these features one by one.
This library is built upon NumPy, SciPy, and Matplotlib.
Features
Datasets
Scikit-learn comes with several inbuilt datasets such as the iris dataset, house prices dataset, diabetes dataset, etc. The main functions of these datasets are that they are easy to understand and you can directly implement ML models on them. These datasets are good for beginners.
You can import the iris dataset as follows:
Python Code:
import sklearn
from sklearn import datasets
import pandas as pd
dataset = datasets.load_iris()
df = pd.DataFrame(dataset.data, columns=dataset.feature_names)
print(df.head())Similarly, you can import other datasets available in sklearn.
Data Splitting
Sklearn provided the functionality to split the dataset for training and testing. Splitting the dataset is essential for an unbiased evaluation of prediction performance. We can define what proportion of our data to be included in train and test datasets.
We can split the dataset as follows:
from sklearn.model_selection import train_test_split x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=2, random_state=4)
With the help of train_test_split, we have split the dataset such that the train set has 80% and the test set has 20% data.
Linear Regression
This supervised ML model is used when the output variable is continuous and it follows linear relation with dependent variables. It can be used to forecast sales in the coming months by analyzing the sales data for previous months.
With the help of sklearn, we can easily implement the Linear Regression model as follows:
from sklearn.linear_model import LinearRegression from sklearn.metrics import mean_squared_error, r2_score regression_model = LinearRegression() regression_model.fit(x_train, y_train) y_predicted = regression_model.predict(x_test) rmse = mean_squared_error(y_test, y_predicted) r2 = r2_score(y_test, y_predicted)
LinerRegression() creates an object of linear regression. Then we fit the model on the training set. Finally, we predicted the model on the test dataset. “rmse” and “r_score” can be used to check the accuracy of the model.
You can read more about Linear Regression here.
Logistic Regression
Logistic Regression is also a supervised regression algorithm just like linear regression. The only difference is that the output variable is categorical. It can be used to predict whether a patient has heart disease or not.
With the help of sklearn, we can easily implement the Logistic Regression model as follows:
from sklearn.linear_model import LogisticRegression from sklearn.metrics import confusion_matrix from sklearn.metrics import classification_report logreg = LogisticRegression() logreg.fit(x_train, y_train) y_predicted = logreg.predict(x_test) confusion_matrix = confusion_matrix(y_test, y_pred) print(confusion_matrix) print(classification_report(y_test, y_pred))
confusion matrix and classification report are used to check the accuracy of classification models. Explanation of confusion matrix and classification report is provided later in the blog.
You can read more about Logistic Regression here.
Decision Trees
A Decision Tree is a powerful tool that can be used for both classification and regression problems. It uses a tree-like model to make decisions and predict the output. It consists of roots and nodes. Roots represent the decision to split and nodes represent an output variable value. A decision tree is an important concept.
Decision trees are useful when the dependent variables do not follow a linear relationship with the independent variable i.e linear regression does not accurate results.
Decision tree implementation for classification
from sklearn.tree import DecisionTreeClassifier from sklearn.metrics import confusion_matrix from sklearn.tree import export_graphviz from sklearn.externals.six import StringIO from IPython.display import Image from pydot import graph_from_dot_data dt = DecisionTreeClassifier() dt.fit(x_train, y_train) dot_data = StringIO() export_graphviz(dt, out_file=dot_data, feature_names=iris.feature_names) (graph, ) = graph_from_dot_data(dot_data.getvalue()) y_pred = dt.predict(x_test)
We fit the model with the DecisionTreeClassifier() object and further code is used to visualize the decision trees implementation in python.
A similar way decision tree can be used for regression by using the DecisionTreeRegression() object. You can read more about Decision Trees here.
Now, we will see Random Forest but before going into it, we first need to understand the meaning of ensemble methods and their types.
The ensemble method is a technique in which multiple models are used to predict the output variable instead of a single one. The dataset is randomly divided into subsets and then passed to different models to train them. The average of all the models is considered when we predict the output. The Ensemble technique is used to reduce the variance-biases trade-off.
There are generally two types of ensembling techniques:
Bagging
Bagging is a technique in which multiple models of the same type are trained with random samples from the training set. The inputs to different models are independent of each other.
For Ex- Multiple decision trees can be used for prediction instead of just one which is called random forest.
Boosting:
Boosting is a technique in which multiple models are trained in such a way that the input of a model is dependent on the output of the previous model. In Boosting, the data which is predicted incorrectly is given more preference.
Ex- Ada Boost, Gradient Boost.
Random Forest
Random Forest is a bagging technique in which hundreds/thousands of decision trees are used to build the model. Random Forest can be used for both classification and regression problems. It can be used to classify loan applicants, identify fraudulent activity and predict diseases.
It can be implemented in python as follows:
from sklearn.ensemble import RandomForestClassifier
num_trees = 100
max_features = 3
clf = RandomForestClassifier(n_estimators=num_trees, max_features=max_features)
clf.fit(x_train,y_train)
y_pred=clf.predict(x_test)
print("Accuracy:",metrics.accuracy_score(y_test, y_pred))
You can read more about Random Forest here.
XG Boost
XGBoost stands for eXtreme Gradient Boosting. It is a boosting technique that provides a high-performance implementation of gradient boosted decision trees. The main features of XG-Boost are it can handle missing data on its own, it supports regularization and generally gives much more accurate results than other models.
It can be implemented in python as follows:
from xgboost import XGBClassifier
from sklearn.metrics import mean_squared_error
xgb = XGBClassifier(colsample_bytree = 0.3, learning_rate = 0.1,max_depth = 5, alpha = 10, n_estimators = 10)
xgb.fit(x_train,y_train)
y_pred=xgb.predict(x_test)
rmse = np.sqrt(mean_squared_error(y_test, preds))
print("RMSE: %f" % (rmse))
You can read more about XGBoost here.
Support Vector Machines(SVM)
Supervised Vector Machine is a supervised ML algorithm in which we plot each data item as a point in n-dimensional space where n is the number of features in the dataset. After, we perform classification by finding the hyperplane that differentiates the classes very well. The data points which are closest to the hyperplane are called support vectors. It can also be used for regression problems but generally used in classification only. It is used in many applications such as face detection, classification of mails, etc.
It can be implemented in python as
from sklearn import svm
from sklearn import metrics
clf = svm.SVC(kernel='linear')
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print("Accuracy:",metrics.accuracy_score(y_test, y_pred))
You can read more about SVM here.
Confusion Matrix
A confusion matrix is a table that is used to describe the performance of classification models. The confusion matrix is analyzed with the help of the following 4 terms:
True Positive(TF)
It means the model predicted positive and it is actually positive.
True Negative(TN)
It means the model predicted negative and it is actually negative.
False Positive(FP)
It means the model predicted positive but it is actually negative.
False Negative(FN)
It means the model predicted negative but it is actually positive.
Ex- In a model, 1 represents a patient with heart disease and 0 represents he does not have heart disease. In the dataset there are 600 patients with heart disease and 400 without heart disease, the model predicted 550 patients with 1 and 450 patients 0 out of which 500 patients are correctly classified as 1 and 350 patients are correctly classified as 0, then the true positive is 500, the true negative is 350, the false positive is 50, the false negative is 150.
It can be implemented as
from sklearn.metrics import confusion_matrix confusion_matrix = confusion_matrix(y_test, y_pred) print(confusion_matrix)

Source: Confusion Matrix
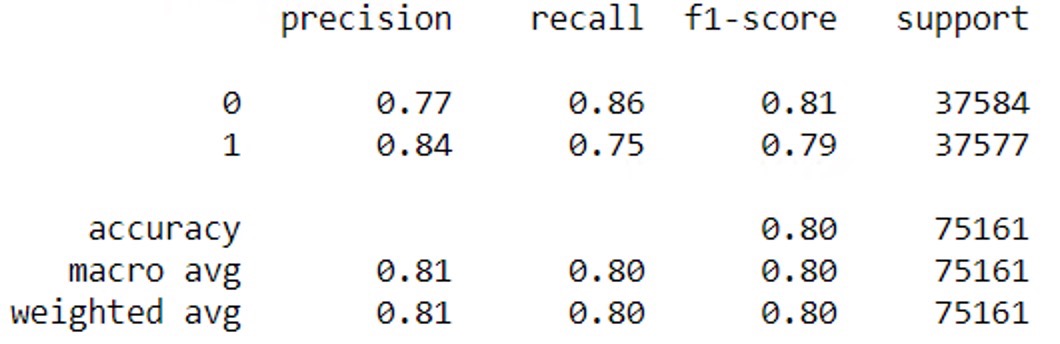
Classification Report
A classification report is used to analyze the predictions of the classification algorithm. It provides the various parameters i.e. accuracy, precision, recall, f1-score through which we can decide whether our model is performing well or not. A classification report is made based on a confusion matrix.
Accuracy
Total predictions (positive or negative) which are correct.
It can be calculated as (TF+TN)/(TF+TN+FP+FN)*100
Precision
Out of positive predictions, how many you got correct.
It can be calculated as TP/(TP+FP)
Recall
Out of total positives, how much you correctly identified.
It can be calculated as TP/(TP+FN)
F1 Score
It is used to check the balance between precision and recall.
It can be calculated as 2/(Precision + Recall)
It can be implemented in python as:
from sklearn.metrics import classification_report print(classification_report(y_test, y_pred))
Now, we have seen important supervised algorithms and statistical tools provided by scikit-learn, it’s time to see some unsupervised algorithms.
K-Means Clustering
K-Means clustering is an unsupervised ML algorithm used for solving classification problems. An unsupervised algorithm is one in which there is no label or output variable in the dataset. In clustering, the dataset is segregated into various groups, called clusters, based on common characteristics and features. In the k-means algorithm, the dataset is divided into subgroups/clusters based on similarity and their mean distance from the centroid of that particular group. It is the most successful and widely used unsupervised algorithm. There are many applications of k-means clustering such as market segmentation, document clustering, image segmentation.
It can be implemented in python as:
from sklearn.cluster import KMeans import statsmodels.api as sm kmeans = KMeans(3) means.fit(x) identified_clusters = kmeans.fit_predict(x)
You can read more about k-means here.
DBSCAN Clustering
DBSCAN is also an unsupervised clustering algorithm that makes clusters based on similarities among data points. In DBSCAN, a cluster is formed only when there is a minimum number of points in the cluster of a specified radius. The minimum number of points and radius of the cluster are the two parameters of DBSCAN which are given by the user. The advantage of DBSCAN is that it is robust to outliers i.e. it can handle outliers on its own, unlike k-means clustering. DBSCAN algorithm is used in creating heatmaps, geospatial analysis, anomaly detection in temperature data.
It can be implemented as
from sklearn.cluster import DBSCAN
from sklearn import metrics
from sklearn.preprocessing import StandardScaler
db = DBSCAN(eps=0.3, min_samples=10).fit(X)
core_samples_mask = np.zeros_like(db.labels_, dtype=bool)
core_samples_mask[db.core_sample_indices_] = True
labels = db.labels_
n_clusters_ = len(set(labels)) - (1 if -1 in labels else 0)
print(labels)You can read more about DBSCAN here.
Principal Component Analysis(PCA)
Principal Component Analysis is a dimensionality-reduction method that is used to reduce to dimensions of large datasets such that the reduced dataset contains most of the information of a large dataset. PCA makes ML algorithms work faster due to smaller datasets. It makes it easier to analyze and visualize the dataset. There are a lot of statistics and maths involved in the implementation of PCA. If you want to understand it deeply you can check here. Scikit-learn provides functions to implement PCA in python.
Scaling – Standardization, and Normalisation
Scaling means to change to a range of values. The columns in the dataset may have wide differences in values. For ex- a column may have values ranging from 1 to 100 while others may have values from 0 to 1. Therefore, it becomes necessary to scale the dataset. Several algorithms such as logistic regression, XGBoost, Neural Networks, and PCA require data to be scaled.
Standardization
Standardization is a scaling technique where we make the mean of the attribute 0 and standard deviation as 1 such that values are centred around the mean with unit standard deviation. It can be done as X’= (X-μ)/σ
Normalization
Normalization is a technique such that the values got ranged from 0 to 1. It is also known as Min-Max scaling. Normalization can be done by the given formula X’ = (X -Xmin)/(Xmax-Xmin).
from sklearn.preprocessing import StandardScaler from sklearn.preprocessing import MinMaxScaler
Python provides the function StandardScaler for implementing Standardization and MinMaxScaler for normalization.
Python provides a function StandardScaler and MinMaxScaler for implementing Standardization and Normalization.
Feature Extraction
Feature Extraction is the way of extracting features from the data. We can only pass the data to an ML model if it is converted into a numerical format. Scikit-Learn provides the functionality to convert text and images into numbers. Bag of Words and TF-IDF are the most commonly used methods to convert words to numbers in Natural Language Processing which are provided by scikit-learn.
There are many more features of Scikit-Learn which you will explore in your journey of data science. Here, I have discussed some important features that must be known.
Summary
This blog explains the 15 most important features of scikit-learn along with the python code.
About Me
Hi! I am Ashish Choudhary. I am pursuing B.Tech from the JC Bose University of Science & Technology. Data Science is my passion and feels proud to write interesting blogs related to it. Feel free to contact me on LinkedIn.







Aashish, i felt there might be calculation mistake in the number of false negative(should be 100 instead of 150 right?). Can you please confirm?
Hi Ashish - You do not have Y variable in your dataset. How do you manage to run so many model with model performance matrix. It would be great If you can help me with this in case if you not copy pasted it from elsewhere.
this blog has proven very beneficial for me as a beginner . thank you for your initiative