This article was published as a part of the Data Science Blogathon
Introduction
Statistics is the science of analyzing huge amounts of data. In the real world, it is nearly impossible to deduce statistics about the entire population. And this huge amount of data needs interpretation to draw meaningful conclusions. Hence, we take some random samples from the population, derive some statistical measures (e.g. mean, standard deviation, variance), and draw conclusions about relationships from the data collected.
Data can be interpreted by assuming a specific outcome and use statistical methods to confirm or reject the assumption. This assumption is called a hypothesis and the statistical test used for this purpose is called hypothesis testing.
In statistics, a hypothesis is a statement about a population that we want to verify based on information contained in the sample data.
Hypothesis testing quantifies an observation or outcome of an experiment under a given assumption. The result of the test enables us to interpret whether the assumption holds true or false. In other words, it signifies if the hypothesis can be confirmed or rejected for the observation made.
An observation or outcome of an experiment is known as a test statistic, which is a statistic measure or a standardized value that is calculated from sample data of the underlying population.
The assumption of hypothesis testing is called the null hypothesis. A null hypothesis is a type of assumption used in statistics indicating that there is no significant difference between the samples from the underlying population. It is also known as the default hypothesis, represented by H0. In contrast, there is a term “Alternative Hypothesis”, represented by H1. For every null hypothesis, there is an alternative hypothesis that is opposite to what the null hypothesis states. In other words, if we reject the null hypothesis, we fail to reject the alternative hypothesis.
The decision of confirming or rejecting the null hypothesis is made by interpreting the result of the test. The result of the hypothesis testing can be interpreted using p-values or critical values. The p-value is the probability of deducing the observed value, given the assumption. On the other hand, critical values are cut-off values that define regions where the test statistic is unlikely to lie.
Perform Hypothesis Testing
Hypothesis testing can be performed using these 3 steps:
1. Design a test statistic
2. Design a null hypothesis
3. Compute the p-value or critical values
How about looking at this coin-toss example to see how is hypothetical testing performed?
Given a coin, determine if the coin is biased towards heads or not.
What do you mean by saying a coin is biased towards heads? This means that the probability of getting heads is greater than 0.5 i.e. P(H) > 0.5.
Design an experiment
Flip a coin 5 times, and count the number of heads.
Consider the count of the number of heads as a random variable ‘X’. In the theory of statistical hypothesis testing, it is known as a test statistic i.e. X = 5.
X = Test Statistic
Perform the experiment
We flip the coin 5 times.
H H H H H
H H H H T
. . .
There are 32 such observations. Out of these 32 possibilities, there is only one observation that has 5 heads. Hence, the test statistic is X = 5.
Now, compute the probability that X = 5, when the coin is not biased towards Heads.
P(X = 5 | coin is not biased towards Heads)
Here, the assumption is “coin is not biased towards heads”. In hypothetical testing, this assumption is known as the null hypothesis (H0).
Result of the experiment
When a coin is tossed once, the probability of getting Heads, i.e. P(H) = 1/2. Similarly, when a coin is tossed 5 times, the probability of getting heads assuming the coin is not biased is 1/25 or 1/32.
P(X = 5 | H0) ≈ 0.03 = 3%
This means that there is a probability of 3% of getting 5 heads in 5 flips if the coin is not biassed towards heads.
While performing this experiment, an observation is made which is X = 5.
In hypothesis testing, the probability of observing the value of the test statistic by experimentation i.e. X = 5 if the null hypothesis is true is 3%.
Here, the test statistic i.e. X = 5 is the observation which is the ground truth. Hence, this fact cannot be revoked.
So, given that this observation has already been made, the probability of this observation if the assumption is also true is only 3% which is very low.
This probability value is called the p-value; the result of the statistical hypothesis testing.
Typically, the p-value is said to be small if it is less than or equal to 5%. This is just a rule of thumb.
If the probability of making the observation that we already made, given the null hypothesis is less than or equal to 5%, then probably the assumption (the coin is not biased towards heads) is incorrect. Hence, it can be concluded that the null hypothesis is incorrect. In this scenario, the assumption that the coin is not biased towards heads is rejected, confirming the idea that the coin is biased. In other words, the alternative hypothesis (H1) is failing to reject.
Here the experiment was designed saying the coin was flipped 5 times. What if the coin was flipped 3 times or 10 times? The probability values will change. So, this experiment is dependent on the number of flips. This is often called a sample size.
Now, let the same experiment be modified as flip a coin 3 times and count the number of heads. Here, the new test statistic is 3 i.e. X = 3. Hence, when the coin is tossed 3 times, the probability of getting heads assuming the coin is not biased is 1/23 = 1/8.
P(X = 3 | H0) = 0.125 = 12.5%
This means that there is a probability of 12.5% of getting 3 heads in 3 flips if the coin is not biased towards heads.
This probability value is much greater than 5%. Hence, the assumption is failing to reject i.e. the coin is not biased.
The results of the hypothesis testing must be wisely interpreted to make claims about the data. The results can be interpreted in different ways. They are the p-values and critical values.
How to interpret the p-value?
A statistical hypothesis test may return a p-value. A p-value is defined as the probability of making the observation made, given the null hypothesis is true. It is calculated using the sample distribution of the test statistic, under the assumption i.e. null hypothesis.
The p-value is used to quantify the result of the test given the null hypothesis. This is done by comparing the p-value to the threshold value also known as significance level referred to by the Greek letter alpha.
Typically, the alpha value is 0.05 or 5%.
The p-value is compared to the pre-defined alpha value. The result of the experiment is significant when the p-value is less than, equal to the alpha value signifying that a change was detected, rejecting the null hypothesis.
P(test statistic | H0) > alpha (5%): failed to reject H0
P(test statistic | H0) <= alpha (5%): reject H0
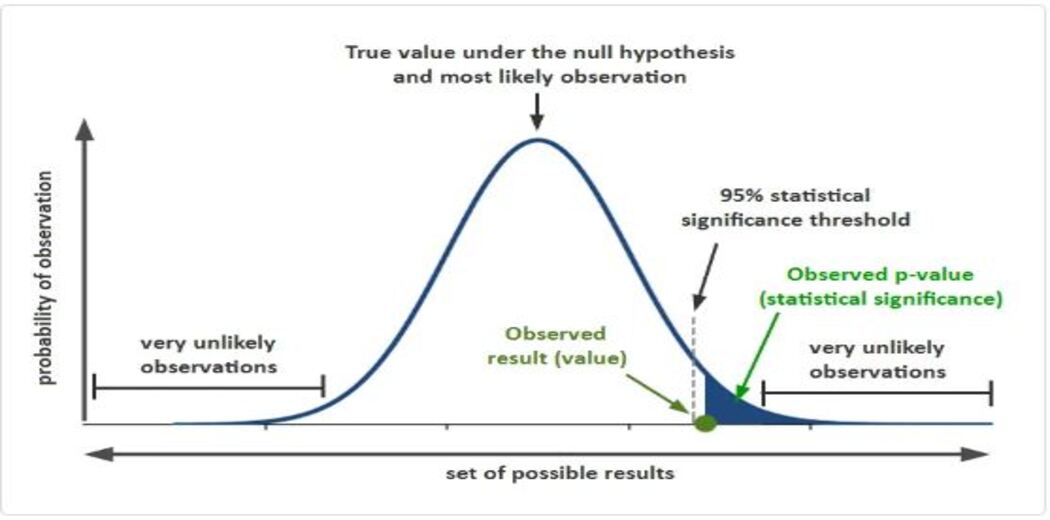
Let us assume, we performed a statistical hypothesis test of whether the data sample is normally distributed and calculated a p-value of 0.9, we can say that the hypothesis test found that the sample is normally distributed, failing to reject the null hypothesis at a 5% significance level.
There is one mistake that a lot of people often make. Some people think that it is the probability that the null hypothesis (H0) is true.
p-value = P(H0 | data)
This is incorrect! We cannot state anything about the null hypothesis (H0).
Instead, the p-value is the probability of the observation you have made given that the null hypothesis (H0) is true.
p-value = P(data | H0)
How to interpret critical values?
Not all statistical tests return a p-value. Instead, they might return a critical value and associated significance level along with the test statistic.
The interpretation of the results is similar to the p-value results. Instead of comparing the p-value to a pre-defined significance level, the test statistic is compared to the critical value at a chosen significance level.
test statistic < critical value: fail to reject H0
test statistic >= critical value: reject H0
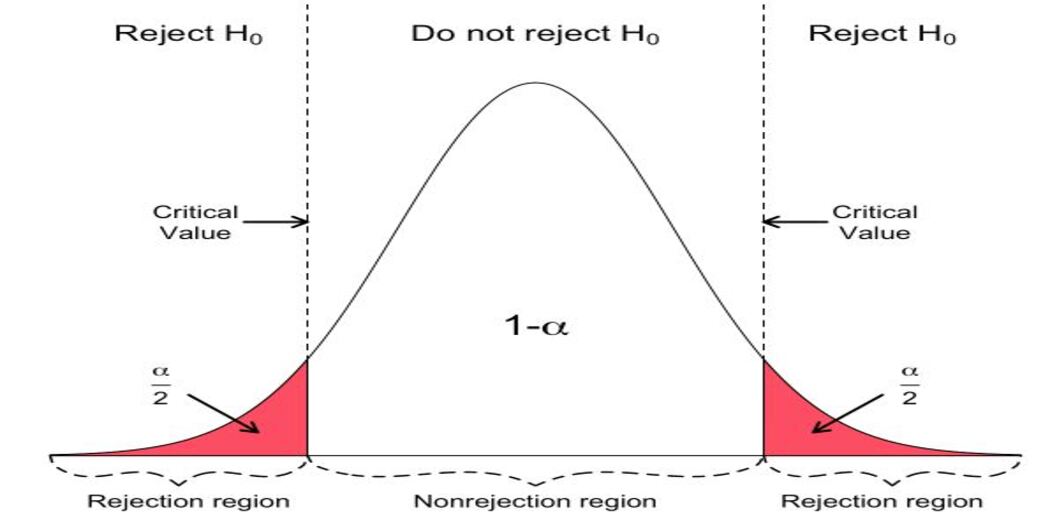
Representation of the results using the critical values are in the same way as they are interpreted using the p-value.
While performing a statistical hypothesis test of whether the data sample is normally distributed is calculated and the test statistic was compared to the critical value at the 5% significance level, we can say that the hypothesis test found that the sample is normally distributed, failing to reject the null hypothesis at a 5% significance level.
Errors in Hypothesis Testing
In hypothesis testing, relatively small samples are used to answer questions about population parameters. There is always a chance that the selected sample is not representative of the population; therefore, there is always a chance that the conclusion deduced is wrong.
Hypothesis testing provides confidence in favor of a certain hypothesis. In other words, hypothesis testing refers to the use of statistical analysis to determine if observed differences between two or more data samples are due to random chance or to be true differences in the samples.
Since we are computing the probability of an experiment it can be deduced that interpretation of the hypothetical test is purely probabilistic. This means that the outcome of the experiment can be misunderstood.
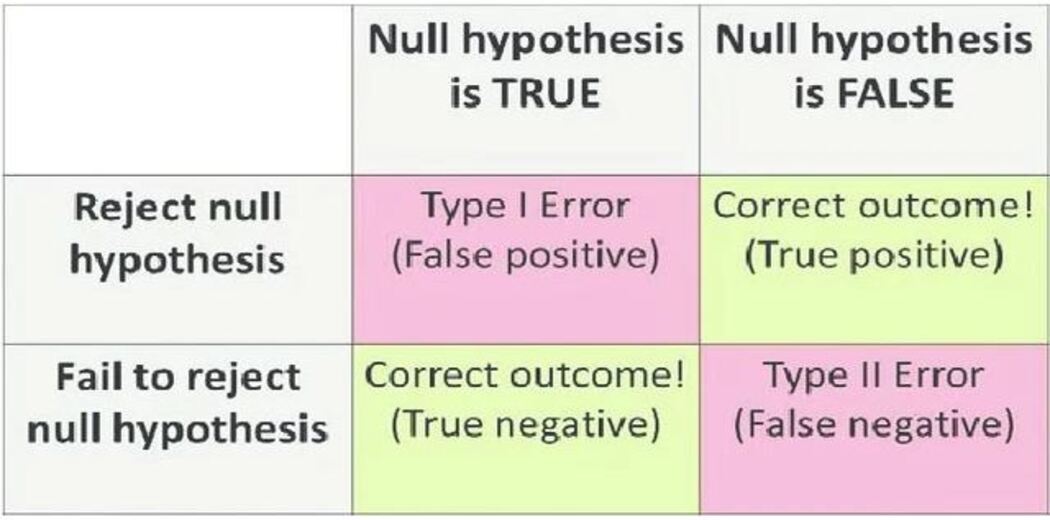
If the p-value is small; rejecting the null hypothesis indicates either of these 2 scenarios:
- The null hypothesis is false – we are right
- The null hypothesis is true and some rare and unlikely event occurred – we made a mistake.
This type of error is called False Positive – Type I Error.
On contrary, if the p-value is large; failing to reject the null hypothesis indicates either of these 2 scenarios:
- The null hypothesis is true – we are right
- The null hypothesis is false and some rare and unlikely event occurred – we made a mistake.
This type of error is called False Negative – Type II Error.
There is always a possibility of making these kinds of errors while interpreting the results of hypothesis testing. Hence, we must be cautious of encountering such errors and verify the findings before drawing conclusions.
SUMMARY
In machine learning, mostly hypothesis testing is used in a test that assumes that the data has a normal distribution and in a test that assumes that 2 or more sample data are drawn from the same population.
Remember these 2 most important things while performing hypothesis testing:
1. Design the Test statistic
Design the experiment ingeniously.
Here in the above experiment, a coin is flipped 5 and 3 times. The sample sizes have to be carefully chosen while designing the experiment.
2. Design the null hypothesis (H0) carefully
It should be designed in such a manner that it makes the probability computation easy and feasible.






