This article was published as a part of the Data Science Blogathon
Introduction
Time series forecasting is the branch of data science which deals with the prediction of a dependent variable with respect to that of the independent variables. We have a number of algorithms that are used for time series forecasting like moving average, ARIMA, regression, etc. Linear regression is one of the simplest predictive modelling algorithms which predicts the values of dependent variables by taking into account just one independent variable. For example, predicting the salary by looking at the qualification or predicting the height by looking at the age, etc.
There are a number of time series modelling algorithms like regression, XG Boost, long short term memory (LSTM), recurrent neural networks, etc. In this post, we will be looking at simple linear regression to forecast the sales of a product based on the discount.

Image source: Google Images https://www.numpyninja.com/post/linear-regression
What is linear regression?
Linear regression is a supervised machine learning model majorly used in forecasting. Supervised machine learning models are those where we use the training data to build the model and then test the accuracy of the model using the loss function.
Linear regression is one of the most widely known time series forecasting techniques which is used for predictive modelling. As the name suggests, it assumes a linear relationship between a set of independent variables to that of the dependent variable (the variable of interest).
Below is the equation to the linear regression model, we all are well aware of it
y=mx+c
Where y is the dependent variable
M refers to the slope of the line
X is the independent variable and
C is the constant
Different types of regression
There are different types of regression analysis, and the application of each regression depends upon the dataset and the problem statement.
Linear Regression:
Linear regression is one of the simplest regression algorithms in machine learning. It consists of a dependent variable and an independent variable which is linearly dependent on the dependent variable.
In case the number of independent variables is more than one then we go for multiple linear regression.
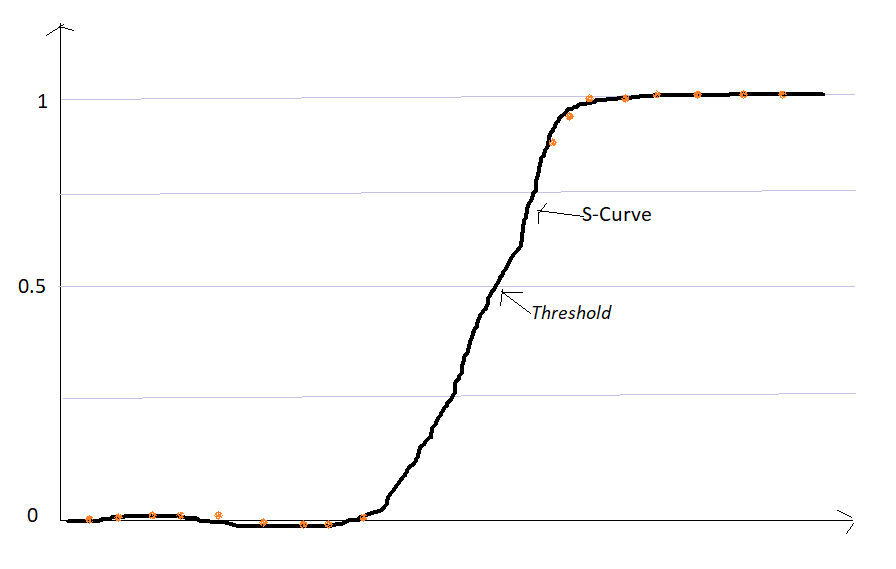
Logistic Regression:
Logistics regression is used when the dependent variables are discrete like yes or No or true or false. Generally, a sigmoid curve is used to denote the relationship between the dependent variable and the independent variable.
The prerequisite for using logistic regression is that there should not be any multicollinearity between the multiple independent variables and the dataset should be large with almost equal occurrences of values.
Below is the Logit function which is used to establish the relationship between the dependent variable and the independent variables.
logit(p) = ln(p/(1-p)) = b0+b1X1+b2X2+b3X3….+bkXk
here p is referred to the probability of occurrence of the feature.
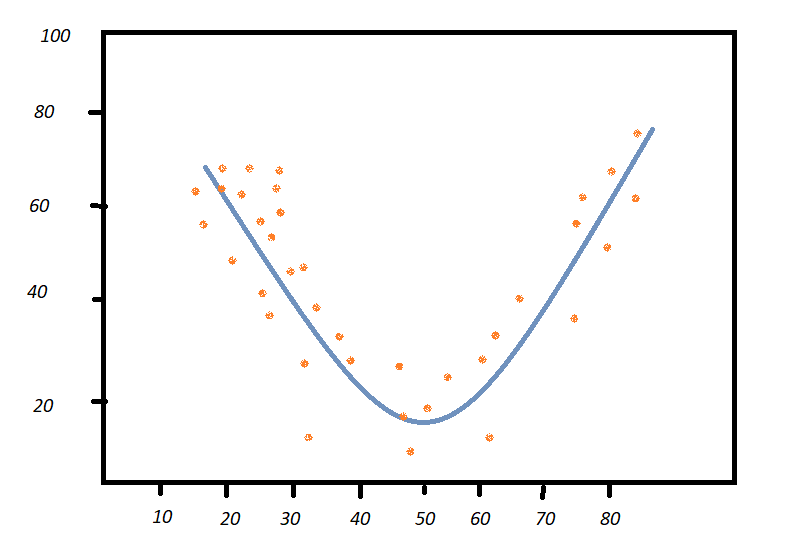
Polynomial Regression:
Polynomial regression is similar to multiple linear regression but the relationship between the dependent and the independent variables is not linear. This type of regression is used when data points are present in a non-linear fashion.
The polynomial regression algorithm transforms the data points into polynomial features of specified degrees and models them using the linear technique. The data points can be best fit them using a polynomial line, however, we should note that this model is prone to overfitting so it is recommended to carefully analyze the curve to avoid any issues in the model fitting.
Ridge Regression:
Ridge regression is the same as simple linear regression, it assumes a linear relationship between the target variables and the independent variables. Ridge regression is used where there is a high correlation between the independent variables in the data set. If the correlation is high, then there is the bias introduced in the model. Hence, we introduce a bias matrix in the equation of the Ridge Regression. It is a very powerful regression algorithm where the model is less prone to overfitting. It’s a type of regularised linear regression which uses L2 regularisation.
Below is the equation used for the Ridge Regression, Here λ (lambda) resolves the multicollinearity issue:
β = (X^{T}X + λ*I)^{-1}X^{T}y
Lasso Regression:
LASSO or Least Absolute Shrinkage and Selection Operator is perfect for models showing high levels of multicollinearity as it encourages simple models with few features. This model is also used to avoid the issue of overfitting as it regularises the model to make it generic to work for a wide variety of data points.
The lasso regression algorithm uses shrinkage. Shrinking occurs when data values are shrunk towards a central point as the mean. This type of regression is used when we have a large number of independent variables as it automatically performs feature selection.
Linear regression on Soap Sales dataset
Let us look at simple linear regression using the soap sales data set and their discount percentages of a store
Let us start with importing all the dependencies, import linear regression from sklearn module
import pandas as pd import numpy as np from sklearn.linear_model import LinearRegression from sklearn.model_selection import train_test_split import matplotlib.pyplot as plt from sklearn import metrics
Read the input file using pandas
soap_sale = pd.read_excel('soap_sales.xlsx',header=0, parse_dates=[0], index_col=0, squeeze=True)
print(soap_sale.head())
no_of_soap discount_percent 324 30 288 28 257 28 223 27 213 27
plt.title('no_of_soap vs discount_percent')
plt.ylabel('no_of_soap')
plt.xlabel('discount_percent')
plt.show()
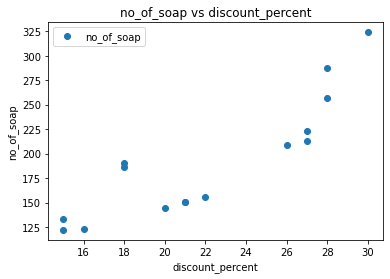
soap_sale.plot(x='discount_percent', y='no_of_soap', style='o')
X = soap_sale.iloc[:, :-1].values
y = soap_sale.iloc[:, 1].values
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
regressor = LinearRegression()
regressor.fit(X_train, y_train)
print(regressor.intercept_)
print(regressor.coef_)
y_pred = regressor.predict(X_test)
df = pd.DataFrame({'Actual': y_test, 'Predicted': y_pred})
print(df)
Actual Predicted
0 28 30.014178
1 18 22.282699
2 22 19.600349
print('Mean Absolute Error:', metrics.mean_absolute_error(y_test, y_pred))
print('Mean Squared Error:', metrics.mean_squared_error(y_test, y_pred))
print('Root Mean Squared Error:', np.sqrt(metrics.mean_squared_error(y_test, y_pred)))

Footnotes
In the above example, we looked at the relation between the number of soaps sold with respect to the discount percentage on the cost of the soap using simple linear regression. Also to check the accuracy percentage in our prediction, we looked at the Mean Absolute Error, Mean squared error and the Root Mean Squared Error. As the error percentage is minimal, we can conclude that the model is performing well and giving the desired result without bias.
The media shown in this article are not owned by Analytics Vidhya and are used at the Author’s discretion.






