This article was published as a part of the Data Science Blogathon
Introduction
In Natural Language Processing, Feature Extraction is one of the trivial steps to be followed for a better understanding of the context of what we are dealing with. After the initial text is cleaned and normalized, we need to transform it into their features to be used for modeling. We use some particular method to assign weights to particular words within our document before modeling them. We go for numerical representation for individual words as it’s easy for the computer to process numbers, in such cases, we go for word embeddings.

Source: https://www.analyticsvidhya.com/blog/2020/06/nlp-project-information-extraction/
In this article, we will discuss the various methods of feature extraction and word embeddings practiced in Natural Language processing.
Feature Extraction:
Bag of Words:
In this method, we take each document as a collection or bag having all the words in it. The idea is to analyze the documents. The document here refers to a unit. In case we want to find all the negative tweets during the pandemic, each tweet here is a document. To obtain the bag of words we always perform all those pre-requisite steps like cleaning, stemming, lemmatization, etc… Then we generate a set of all the words that are available before sending it for modeling.
“Tackling is the best part of football” -> { ‘tackle’, ‘best’, ‘part’, ‘football’ }
We can get repeated words within our document. A better representation is a vector form, that can tell us how many times each word can occur in a document. The following is called a document term matrix and is shown below:
Source: https://qphs.fs.quoracdn.net/main-qimg-27639a9e2f88baab88a2c575a1de2005
It tells us about the relationship between a document and the terms. Each of the values in the table tells about the term frequency. To find the similarity, we go for the cosine similarity measure.
TF-IDF:
One problem that we encounter in the bag-of-words approach is that it treats every word equally, but in a document, there is a high chance of particular words being repeated more often than others. In a news report about Messi winning the Copa-America tournament, the word Messi would be more frequently repeated. We cannot give Messi the same weight as any other word in that document. In the news report, if we take each sentence as a document, we can count the number of documents each time Messi occurs. This method is called document-frequency.
We then divide the term frequency by the document frequency of that word. This helps us with the frequency of occurrence of terms in that document and inverse to the number of documents it appears in. Thus we have the TF-IDF. The idea is to assign particular weights to words that tell us about how important they are in the document.
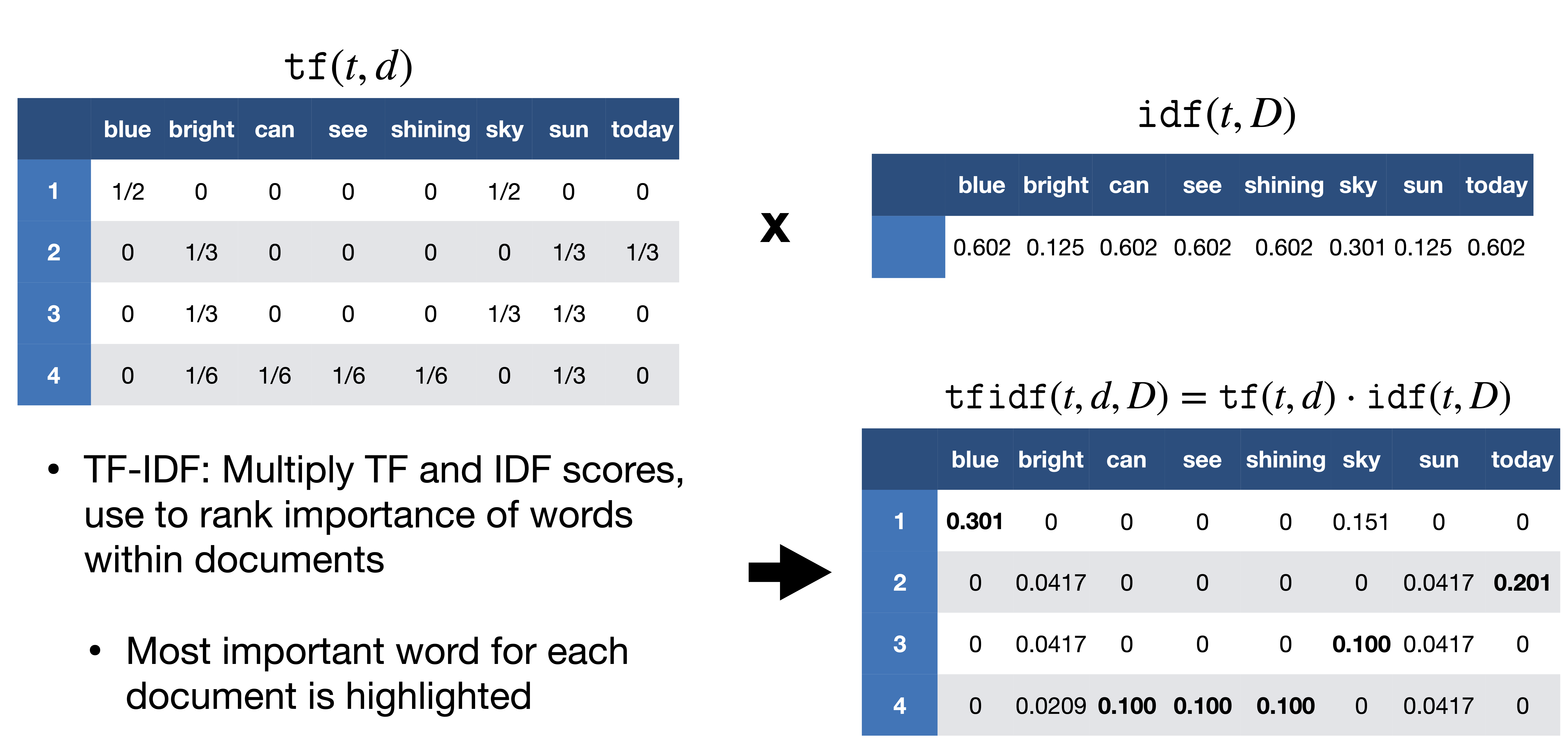
Source: https://sci2lab.github.io/ml_tutorial/tfidf/
One-hot Encoding:
For better analysis of the text we want to process, we must come up with a numerical representation of each word. This can be solved using the One-hot Encoding method. Here we treat each word as a class and in a document wherever the word is we assign 1 for it in the table and all other words in that document get 0. This is similar to the bag of words, but here we just keep each word in a bag.
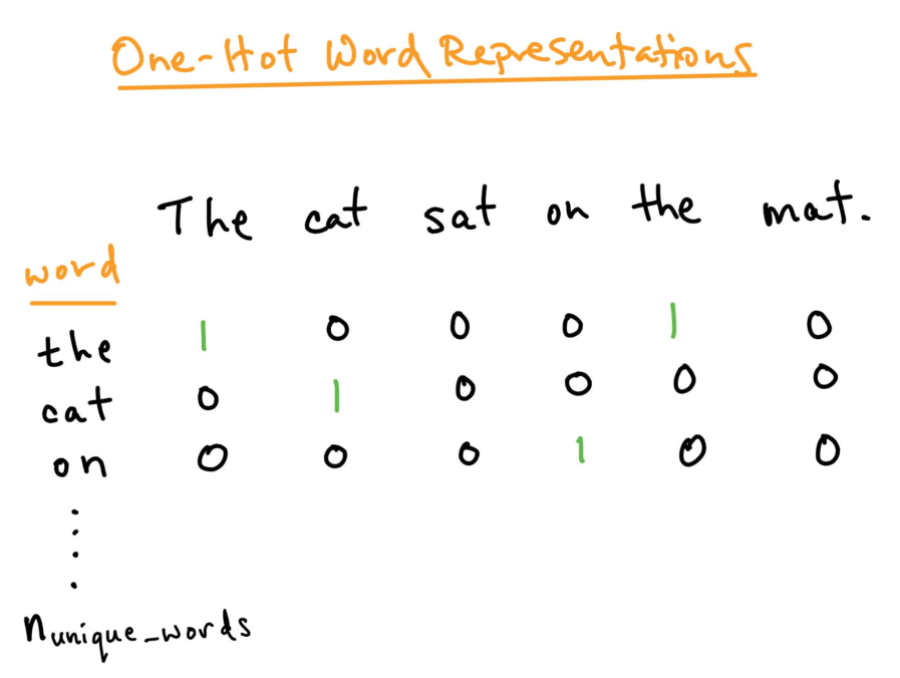
Source:https://towardsdatascience.com/word-embedding-in-nlp-one-hot-encoding-and-skip-gram-neural-network-81b424da58f2
Word Embedding:
One-hot encoding works well when we have a small set of data. When there is a huge vocabulary, we can encode it using this method as the complexity increases a lot. We require a method that can control the size of the words we represent. We do this by limiting it to a fixed-sized vector. We want to find an embedding for each word. We want them to show us some properties. Like, if two words are similar they must be closer to each other in representation, and two opposite words if their pairs exist, they both must be having the same difference of distances. These help us find synonyms, analogies, etc…
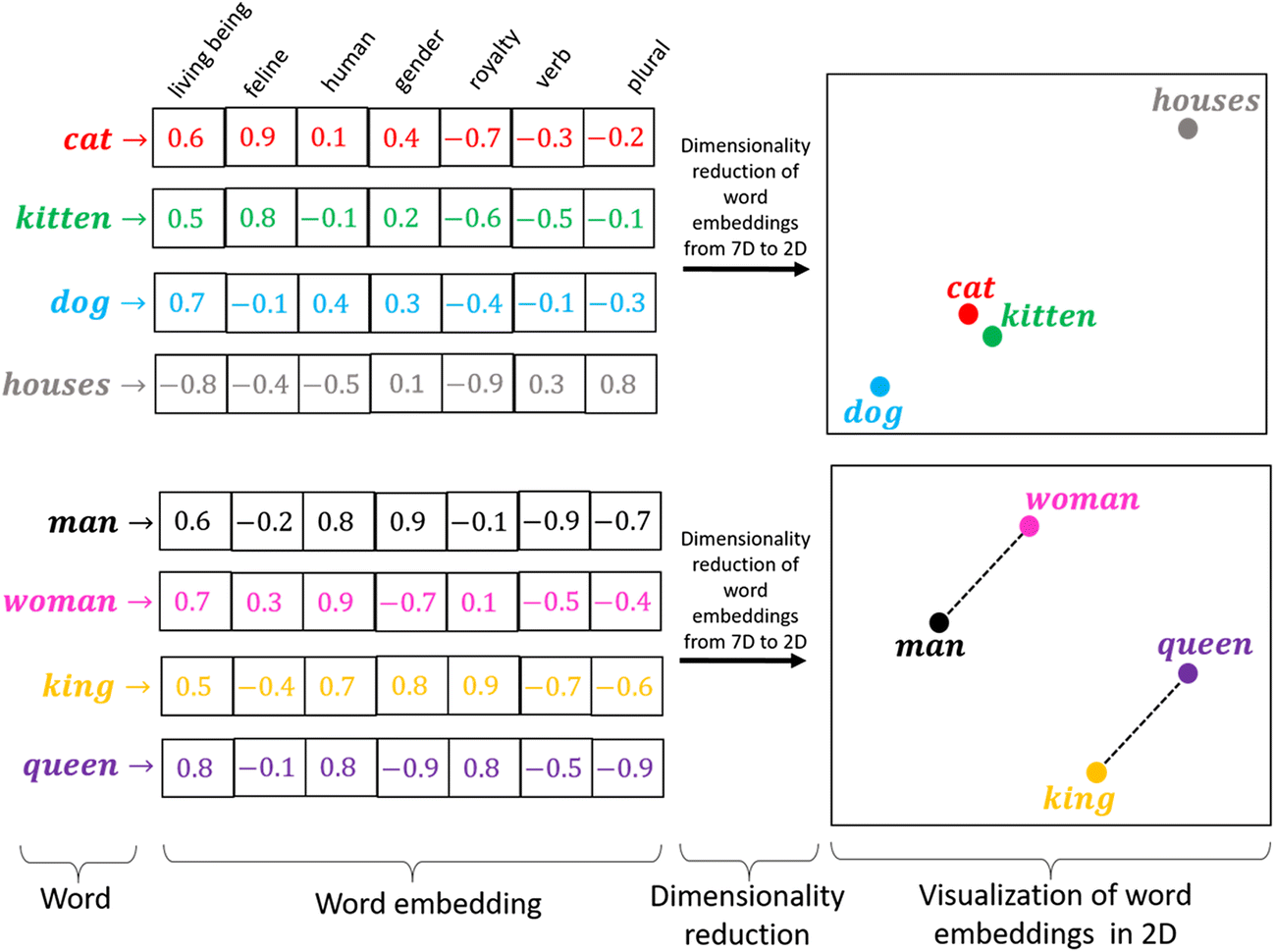
Source: https://miro.medium.com/max/1400/1*sAJdxEsDjsPMioHyzlN3_A.png
Word2Vec:
Word2Vec is widely used in most of the NLP models. It transforms the word into vectors. Word2vec is a two-layer net that processes text with words. The input is in the text corpus and the output is a set of vectors: feature vectors represent the words on that corpus. While Word2vec is not a deep neural network, it converts text into an unambiguous form of computation for deep neural networks. The purpose and benefit of Word2vec are to collect vectors of the same words together in vector space. That is, it finds mathematical similarities. Word2vec creates vectors that are distributed by numerical presentations of word elements, features such as individual word context. It does so without human intervention.
Given enough data, usage, and conditions, Word2vec can make the most accurate predictions about the meaning of a word based on previous appearances. That guess can be used to form word-and-word combinations (eg “big” i.e. “large” to say “small” is “tiny”), or group texts and separate them by topic. Those collections can form the basis for the search, emotional analysis, and recommendations in various fields such as scientific research, legal discovery, e-commerce, and customer relationship management. The result of the Word2vec net is a glossary where each item has a vector attached to it, which can be embedded in an in-depth reading net or simply asked to find the relationship between the words.
Word2Vec can capture the contextual meaning of words very well. There are two flavors. In one of the methods, we are given the neighboring words called the continuous bag of words (CBoW), and in which we are given the middle word called skip-gram and we predict the neighboring words. Once we get a pre-trained set of weights we can save it and this can be used later for word vectorization without the need for transformation again. We store them on a lookup table.
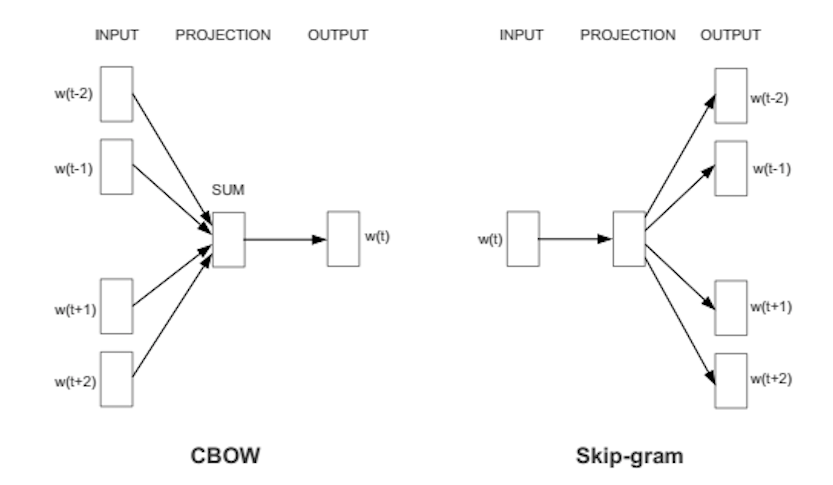
Source: https://wiki.pathmind.com/word2vec
GloVe:
GloVe – global vector for word representation. An unsupervised learning algorithm by Stanford is used to generate embedding words by combining a word matrix for the word co-occurrence of matrix from the corpus. Emerging embedded text shows an attractive line format for a word in a vector space. The GloVe model is trained in the zero-level global co-occurrence matrix, which shows how often words meet in a particular corpus. Completing this matrix requires one pass per entire corporation to collect statistics. For a large corpus, this transaction may cost a computer, but it is a one-time expense in the future. Subsequent follow-up training is much faster because the number of non-matrix entries is usually much smaller than the total number of entries in the corpus.
The following is a visual representation of word embeddings:
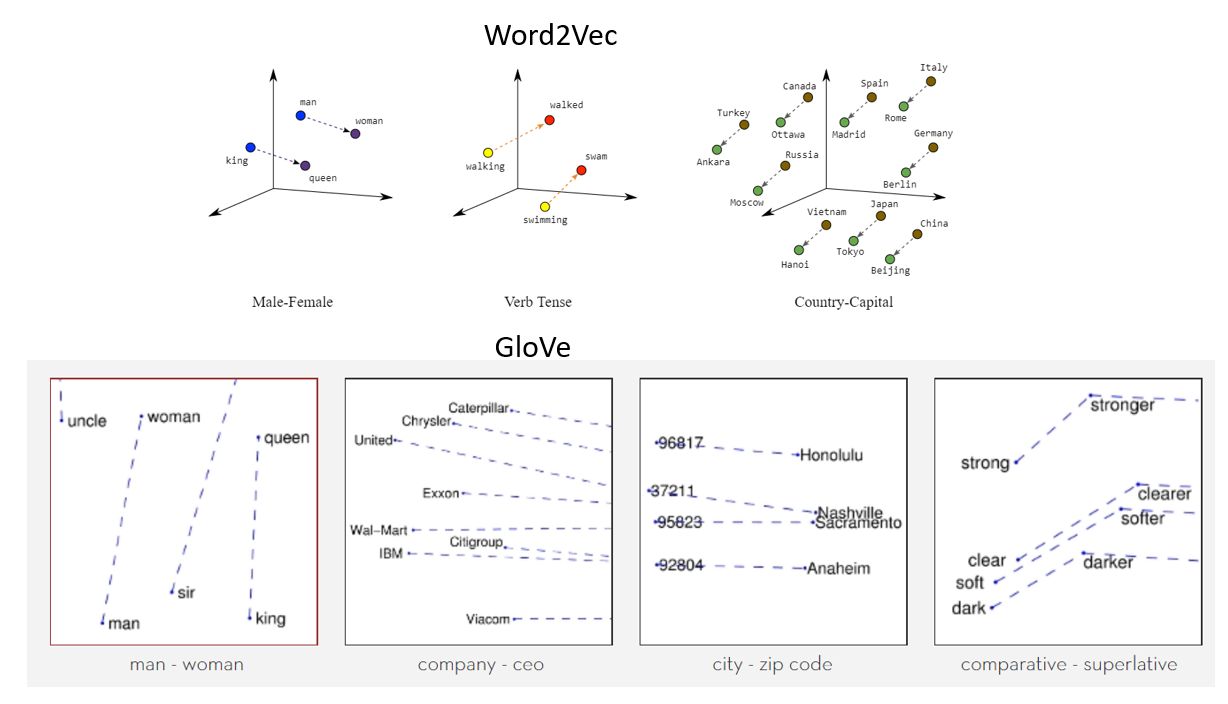
Source: https://miro.medium.com/max/1400/1*gcC7b_v7OKWutYN1NAHyMQ.png
References:
1. Image – https://www.develandoo.com/blog/do-robots-read/
2. https://nlp.stanford.edu/projects/glove/
3. https://wiki.pathmind.com/word2vec
4. https://www.udacity.com/course/natural-language-processing-nanodegree–nd892
Conclusion:

Source:https://medium.com/datatobiz/the-past-present-and-the-future-of-natural-language-processing-9f207821cbf6
About Me: I am a Research Student interested in the field of Deep Learning and Natural Language Processing and currently pursuing post-graduation in Artificial Intelligence.
Feel free to connect with me on:
1. Linkedin: https://www.linkedin.com/in/siddharth-m-426a9614a/
2. Github: https://github.com/Siddharth1698
Passionate about artificial intelligence, I am dedicated to advancing research in Generative AI and Large Language Models (LLMs). My work focuses on exploring innovative solutions and pushing the boundaries of what's possible in this dynamic and transformative field.




