Objective
The main objective of this article is to understand what is Parkinson’s disease and to detect the early onset of the disease. We will use here XGBoost, KNN Algorithm, Support Vector Machines (SVMs), Random Forest Algorithm and utilize the data-set available on UCL Parkinson Data-set under URL (Index of /ml/machine-learning-databases/Parkinsons (uci.edu)).
Parkinson Disease
Parkinson Disease is a brain neurological disorder. It leads to shaking of the body, hands and provides stiffness to the body. No proper cure or treatment is available yet at the advanced stage. Treatment is possible only when done at the early or onset of the disease. These will not only reduce the cost of the disease but will also possibly save a life. Most methods available can detect Parkinson in an advanced stage; which means loss of approx.. 60% dopamine in basal ganglia and is responsible for controlling the movement of the body with a small amount of dopamine. More than 145,000 people have been found alone suffering in the U.K and in India, almost one million population suffers from this disease and it’s spreading fast in the entire world.
A person diagnosed with Parkinson’s disease can have other symptoms that include-
1. Depression
2. Anxiety
3. Sleeping, and memory-related issues
4. Loss of sense of smell along with balance problems.
What causes Parkinson’s disease is still unclear, but researchers have research that several factors are responsible for triggering the disease. It includes –
1. Genes- Certain mutation genes have been found by research that are very rare. The gene variants often increase the risk of Parkinson’s disease but have a lesser effect on each genetic marker.
2. Environment- Due to certain harmful toxins or chemical substances found in the environment can trigger the disease but have a lesser effect
Although it develops at age of 65 15% can be found at young age people less than 50. We will make use of XGBoost, KNN, SVMs, and Random Forest Algorithm to check which is the best algorithm for detection of the onset of disease.
What is XGBoost?
XGBoost is an algorithm. That has recently been dominating applied gadget learning. XGBoost set of rules is an implementation of gradient boosted choice timber. That changed into the design for pace and overall performance.
Code-
#Importing the libraries NumPy, Pandas, Sklearn and XGBoost.
import numpy as np import pandas as pd import os, sys from sklearn.preprocessing import MinMaxScaler from xgboost import XGBClassifier from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score
#Reading the file data of Parkinson disease
Python Code:
import pandas as pd
df=pd.read_csv('parkinsons.data')
print(df.head())#Features are columns that are without column status and the label includes status column.
features=df.loc[:,df.columns!='status'].values[:,1:] labels=df.loc[:,'status'].values print(labels[labels==1].shape[0], labels[labels==0].shape[0]) scaler=MinMaxScaler((-1,1)) x=scaler.fit_transform(features) y=labels x_train,x_test,y_train,y_test=train_test_split(x, y, test_size=0.2, random_state=7) model=XGBClassifier(eval_metric='mlogloss') model.fit(x_train,y_train) Output - XGBClassifier(base_score=0.5, booster='gbtree', colsample_bylevel=1,
colsample_bynode=1, colsample_bytree=1, eval_metric='mlogloss',
gamma=0, gpu_id=-1, importance_type='gain',
interaction_constraints='', learning_rate=0.300000012,
max_delta_step=0, max_depth=6, min_child_weight=1, missing=nan,
monotone_constraints='()', n_estimators=100, n_jobs=4,
num_parallel_tree=1, random_state=0, reg_alpha=0, reg_lambda=1,
scale_pos_weight=1, subsample=1, tree_method='exact',
use_label_encoder=False, validate_parameters=1, verbosity=None)
y_pred=model.predict(x_test) print(accuracy_score(y_test, y_pred)*100)
Output - 94.87179487179486
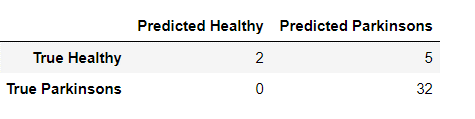
from sklearn.metrics import confusion_matrix
pd.DataFrame(
confusion_matrix(y_test, y_pred),
columns=['Predicted Healthy', 'Predicted Parkinsons'],
index=['True Healthy', 'True Parkinsons']
)

It shows 94 % accuracy by XGBoost Algorithm. Now we will be using Random Forest.
Decision trees are an exceptional device, but they can frequently over-fit the training set of facts until pruned effectively, hindering their predictive capabilities.
What is a Support Vector Machine?
Another algorithm for the analysis of classification and regression is the support vector machine.
It is a supervised machine algorithm used. Image classification and hand-written recognition
are where the support vector machine comes to hand used. It sorts the data in one out of two
categories and displays the output with the margin between the two as far as possible.
Code-
#fitting the model in SVM classifi2.fit(x_train,y_train) print(accuracy_score(y_test, y2_pred)*100) from sklearn.svm import SVC classifi2 = SVC() #predicting reults Output- 87.17948717948718
y2_pred = classifi2.predict(x_test)
The output model of SVMs shows 87% accuracy for the given data set.
What is KNN?
K-Nearest Neighbors (KNN ) algorithm, is one of the most powerful utilized algorithms of machine learning that is widely used both for regression as well as classification tasks. In order to predict and examine the class in which data points fall, it examines the label of chosen data points surrounded by the target point.
Code-
from sklearn.neighbors import KNeighborsClassifier from sklearn.decomposition import PCA pca = PCA(n_components = 2) x_train = pca.fit_transform(x_train) x_test = pca.transform(x_test) variance = pca.explained_variance_ratio_ classifi = KNeighborsClassifier(n_neighbors = 8,p=2,metric ='minkowski') classifi.fit(x_train,y_train) y_pred = classifi.predict(x_test) from sklearn.metrics import confusion_matrix,accuracy_score #KNN model cm=confusion_matrix(y_test,y_pred) accuracy_score(y_test,y_pred)
#predicting reults
#Analyzing
Output – 0.8974358974358975
The output model of the KNN Algorithm shows 89% accuracy.

What is Random Forest?
Random forests are an ensemble version of many choice bushes, wherein each tree will specialize its focus on a specific feature while maintaining a top-level view of all capabilities.
Each tree within the random wooded area will do its own random train/check break up of the information, referred to as bootstrap aggregation and the samples no longer covered are called the ‘out-of-bag samples. Moreover, every tree will do characteristic bagging at every node-branch split to lessen the results of a characteristic mostly correlated with the response.
While an individual tree is probably touchy to outliers, the ensemble version will no longer be the same.
X = df.drop('status', axis=1)
X = X.drop('name', axis=1)
y = df['status']
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=1)
from sklearn.ensemble import RandomForestClassifier random_forest = RandomForestClassifier(n_estimators=30, max_depth=10, random_state=1)
random_forest.fit(x_train, y_train) from sklearn.metrics import accuracy_score y_predict = random_forest.predict(x_test) accuracy_score(y_test, y_predict) Output - 0.9387755102040817 Random Forest shows accuracy 93% almost less then XGBoost Algorithm. from sklearn.metrics import confusion_matrix pd.DataFrame( confusion_matrix(y_test, y_predict), columns=['Predicted Healthy', 'Predicted Parkinsons'], index=['True Healthy', 'True Parkinsons'] )
Heat Map
Now, let’s take a heatmap of Predicted data by the XGBoost Algorithm.
import seaborn as sns sns.heatmap(a, cmap ='RdYlGn', linewidths = 0.30, annot = True)
.png)
Predicted Parkinson’s are 31 on a heat map.
Conclusion
Parkinson’s disease affects the CNS of the brain and has yet no treatment unless it’s detected early. Late detection leads to no treatment and loss of life. Thus its early detection is significant. For early detection of the disease, we utilized machine learning algorithms such as XGBoost and Random Forest. We checked our Parkinson disease data and find out XGBoost is the best Algorithm to predict the onset of the disease which will enable early treatment and save a life.
Small Introduction about myself-
I, Sonia Singla have done MSc in Biotechnology from Bangalore University, India and an MSc in Bioinformatics from the University of Leicester, U.K. I have also done a few projects on data science from CSIR-CDRI. Currently is an advisory editorial board member at IJPBS. Have reviewed and published few research papers in Springer, IJITEE and various other Publications. You can contact me or reach me on Linkedin. Thanks
Linkedin – https://www.linkedin.com/in/soniasinglabio/
The media shown in this article are not owned by Analytics Vidhya and are used at the Author’s discretion.
I have done my Master Of Science in Biotechnology and Master of Science in Bioinformatics from reputed Universities. I have written a few research papers, reviewed them, and am currently an Advisory Editorial Board Member at IJPBS.
I Look forward to the opportunities in IT to utilize my skills gained during work and Internship.
https://aster28.github.io/SoniaSinglaBio/site/







I was diagnosed with Parkinson's disease a year ago at the age of 67. For several months I had noticed tremors in my right hand and the shaking of my right foot when I was sitting. My normally beautiful cursive writing was now small cramped printing. And I tended to lose my balance. Neurologist had me walk down the hall and said I didn't swing my right arm. I had never noticed! I was in denial for a while as there is no history in my family of parents and five older siblings, but I had to accept I had classic symptoms. I was taking amantadine and carbidopa/levodopa and was about to start physical therapy to strengthen muscles. Finally, I was introduced to Kycuyu Health Clinic and their effective Parkinson’s herbal protocol. This protocol relieved symptoms significantly, even better than the medications I was given. After First month on treatment, my tremors mysterious stopped, had improvement walking. After I completed the treatment, all symptoms were gone. I live a more productive life. I was fortunate to have the loving support of my husband and family. I make it a point to appreciate every day!