Disclaimer: The goal of this post is only educational. Web Scraping is not encouraged, especially when there are terms and conditions against such actions.
The post is the third in a series of tutorials to build scrapers. Below, there is the full series:
- HTML basics for web scraping
- Web Scraping with Octoparse
- Web Scraping with Selenium (this post)
The purpose of this series is to learn to extract data from websites. Most of the data in websites are in HTML format, then the first tutorial explains the basics of this markup language. The second guide shows a way to scrape data easily using an intuitive web scraping tool, which doesn’t need any knowledge of HTML. Instead, the third and last tutorial is focused on gathering data with Python from the web. In this case, you need to grasp to interact directly with HTML pages and you need some previous knowledge of it.
In the last years, the exponential growth of data available on the web leads to needing for web scraping. What is web scraping? It provides a set of techniques to extract and process huge amounts of data from web pages. To gather information from the websites, there are many possible scraping tools that can be applied.
Table of Content
- Required installations
- Principal methods of Selenium
- Data extraction with Selenium
Required Installations
Before beginning the tutorial, you need Python 3 installed on your PC. I used the Jupiter notebook to write the code in Windows 10. To install Selenium, you only need to copy this line in your notebook:
!pip install selenium
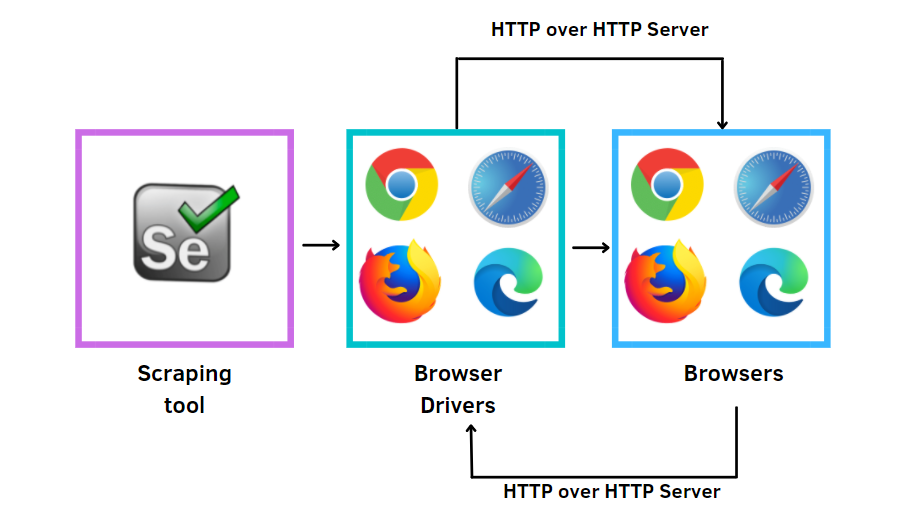
After you have to install a browser driver, which you choose depending on the browser you often use. In my case, I have Chrome, so I installed the Chrome driver. Below, there are the links to the more popular browser drivers:
Principal methods of Selenium
Here, I show the methods of Selenium to find multiple elements in web pages [1]. Then, these methods return lists.
- find_elements_by_name
- find_elements_by_xpath
- find_elements_by_link_text
- find_elements_by_partial_link_text
- find_elements_by_tag_name
- find_elements_by_class_name
- find_elements_by_css_selector
To locate only one element in the website, there are the corresponding methods:
- find_element_by_name
- find_element_by_xpath
- find_element_by_link_text
- find_element_by_partial_link_text
- find_element_by_tag_name
- find_element_by_class_name
- find_element_by_css_selector
You need only to remove the ‘s’ from elements in the string. In this guide, I use find_elements_by_class_name, where you need to know the class name of the selected tag in HTML code, and find_elements_by_xpath, which specify the path of the elements using XPath.
XPath is a language, which uses path expressions to take nodes or a set of nodes in an XML document. There is a similarity to the paths you usually see in your computer file systems. The most useful path expressions are:
nodenametakes the nodes with that name/gets from the root node//gets nodes in the document from the current node.gets the current node..gets the “parent” of the current node@gets the attribute of that node, such as id and class
To grasp better XPath, check the w3schools website.
Data Extraction with Selenium
Let’s start by importing the libraries:
from selenium import webdriver from selenium.webdriver.common.keys import Keys import pandas as pd
First, we create an instance of Chrome WebDriver, specifying the path of Chromedriver installed:
driver = webdriver.Chrome(r "C:UsersEugeniaDownloadschromedriver_win32chromedriver.exe")
Given the url, driver.get is used to navigate the web page.
url = 'https://en.wikipedia.org/wiki/List_of_countries_by_greenhouse_gas_emissions'
driver.get(url)
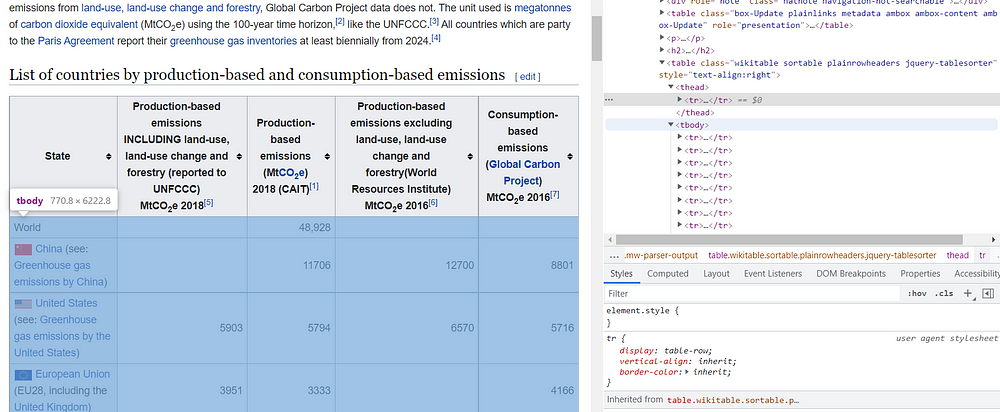
We are interested to extract the data from the table, save it in a Pandas Dataframe and export it into a CSV file.
The first step is to extract the header row of the table. As shown before, the find_elements_by_class_name needs only the class name as input.
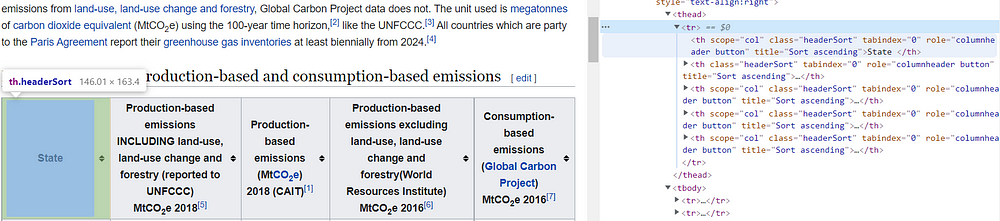
titles = driver.find_elements_by_class_name('headerSort')
for t in titles:
print(t.text)

In this way, we obtained a list containing all the titles of the table. We can already create an empty Dataframe, specifying the names of the columns.
df = pd.DataFrame(columns=[t.text for t in titles]) df.head()

Now, it’s time to gather the data contained in each column. As you can observe, the tag
contains the body content in an HTML table, so all cells we want to extract are within these tags.
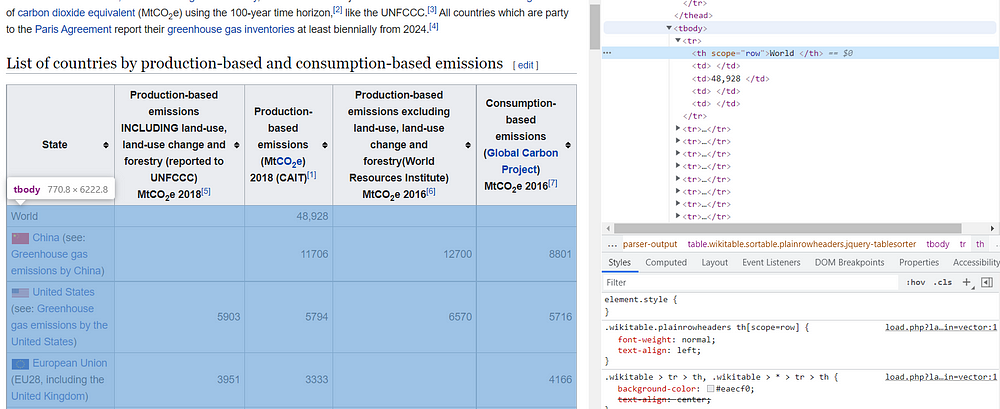
states = driver.find_elements_by_xpath('//table[@class="wikitable sortable plainrowheaders jquery-tablesorter"]/tbody/tr/th')
To check the states found, I print the list:
for idx,s in enumerate(states):
print('row {}:'.format(idx))
print('{}'.format(s.text))

In a similar way, I extracted the content of the other columns. After the column of states, all the remaining columns are contained in the
tags. The index needs to be specified since we look row by row with the
tags.
col2 = driver.find_elements_by_xpath('//table[@class="wikitable sortable plainrowheaders jquery-tablesorter"]/tbody/tr/td[1]')
col3 = driver.find_elements_by_xpath('//table[@class="wikitable sortable plainrowheaders jquery-tablesorter"]/tbody/tr/td[2]')
col4 = driver.find_elements_by_xpath('//table[@class="wikitable sortable plainrowheaders jquery-tablesorter"]/tbody/tr/td[3]')
col5 = driver.find_elements_by_xpath('//table[@class="wikitable sortable plainrowheaders jquery-tablesorter"]/tbody/tr/td[4]')
Finally, we can add the columns to the DataFrame previously created:
df[df.columns[0]] = [s.text for s in states]
df[df.columns[1]] = [s.text for s in col2] df[df.columns[2]] = [s.text for s in col3] df[df.columns[3]] = [s.text for s in col4] df[df.columns[4]] = [s.text for s in col5]
df.head()
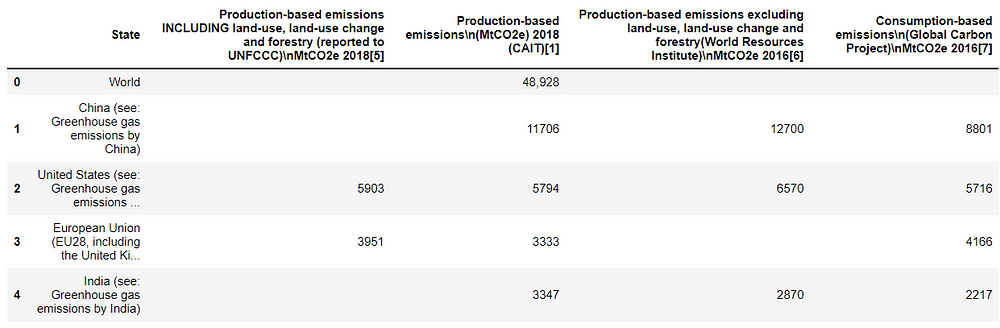
Let’s export the dataset into a CSV file:
df.to_csv('greenhouse_gas_emissions.csv')
Final thoughts
I hope that this tutorial allowed you to learn web scraping with Selenium. There are many other scraping tools available, like BeautifulSoup and Scrapy. You are spoiled for choice! Thanks for reading. Have a nice day!







Thank you for sharing. This was very interesting to re-discover after a few years in the market right after the college.