This article publicize as a part of the Data Science Blogathon
Introduction
Most of you guys might be familiar with the word Web Scraping. I think most of you here are aspiring to become data scientists or at the starting stage of your data science career. So, most of you who are at the starting stage of your data career might be aware of the meaning of Web Scraping and its importance in a Data career. But, if you are a complete novice and do not have any prior knowledge regarding this skill. Then you must begin with this introductory course (i.e., Introduction to Web Scraping using Python) on Analytics Vidhya. It is cost-free and provides a foundational & quick-start introduction to Web Scraping. I prefer you to take it first because you will need those concepts and practices introduced in that course for doing this project. That course will work for you as a foundation in Web Scraping, and this project helps you apply that in the real world.
Before getting into the project & doing some cool stuff, it would be normal to ask (e.g., Why do you need to do such a type of project?, or Why this project, not another?). Because just following online web scraping tutorials step by step will not help you to master this skill. So it is equally important to set such challenges for yourself to test your grasp over the concepts you learned from the course and draw your findings on them.
I am not forcing you to do this project because there are many projects available on the internet. You can choose any one of them. But it would be much easier to get started if you just completed the introductory course of web scraping and thinking about where to apply those concepts. It would be like opening yourself to the world of web scraping if you never scrap anything.
You’re all set.
So, let’s get started.
Project Walk-through
You might know that at the start of any work or project, there is some initiative. So, it is logical to question (i.e., why do you build such a type of tool, or why might you need it ?).
Consider the case where you no longer want to keep visiting your niche subreddit, let say, r/MachineLearning, frequently for checking new posts. If they do not interest you, then it might make you frustrated. Rather, if you use a certain tool that can give you a new post’s heading and its description, then you can check whether it would be worth it to go and continue reading more or discuss with other members. So, it can act as our starting initiative for this project.
Since you took the introductory course (hopefully), now you might be knowing that before crawling any webpage, you are supposed to follow its robots.txt file. It tells web robots which pages not to crawl.

Now, as shown, it is allowed to crawl the things which we want.
There are three main components of Web Scraping, or you can also phrase Three-Step Framework for Web Scraping :
- Crawl: The first step invariably is to navigate to the target website by making HTTP requests & download the response you get.
- Parse & Transform: Once you have received the response. Now, time to parse this downloaded data into an HTML parser like BeautifulSoup & extract the required data.
- Store: Now that you have extracted the required data. You can easily store this as a JSON or CSV file or directly in the database like Mongo DB.
If you completed the Analytics Vidhya introductory course, then you might know them very well. Now we are going to apply each step one by one.
Crawl
First, we need to navigate to the target webpage by making HTTP requests and downloading the response.
So start with importing the required libraries (i.e., requests and BeautifulSoup). Now, setting up the URL and header variable. The first variable reserve the URLs to crawl, and the second variable reserve your request User-agent id, which is for authentication at the time of making HTTP requests.
# Importing required libraries
import requests
from bs4 import BeautifulSoup
# Url to Scrap
url = "https://www.reddit.com/r/MachineLearning/new/"
# Setting header for authentication
header= {
'User-agent': "Mozilla/5.0 (Windows NT 6.3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36 OPR/77.0.4054.203 (Edition Campaign 34)"
}
Now making HTTP requests using the request method of the requests module and downloading the response in the response variable.
import requests
from bs4 import BeautifulSoup
# Url to Scrap
url = "https://www.reddit.com/r/MachineLearning/new/"
# Setting header for authentication
header= {
'User-agent': "Mozilla/5.0 (Windows NT 6.3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36 OPR/77.0.4054.203 (Edition Campaign 34)"
}
# Making request and downloading results in response variable
response = requests.request("GET", url, headers = header)
# To check whether you make a successful request and downloaded the response
print(response)Output:-

Parse & Transform
Now, time to parse this downloaded data into an HTML parser (i.e., BeautifulSoup) & store it in a data variable.
# Parsing data into html parser and storing in data variable data = BeautifulSoup(response.text, "html.parser")
So let’s visit manually on the machine learning niche subreddit i.e., “ r/MachineLearning” and click Ctrl+Shift+C which lets you inspect each section of that page and see its corresponding HTML tags and its attributes with their values.
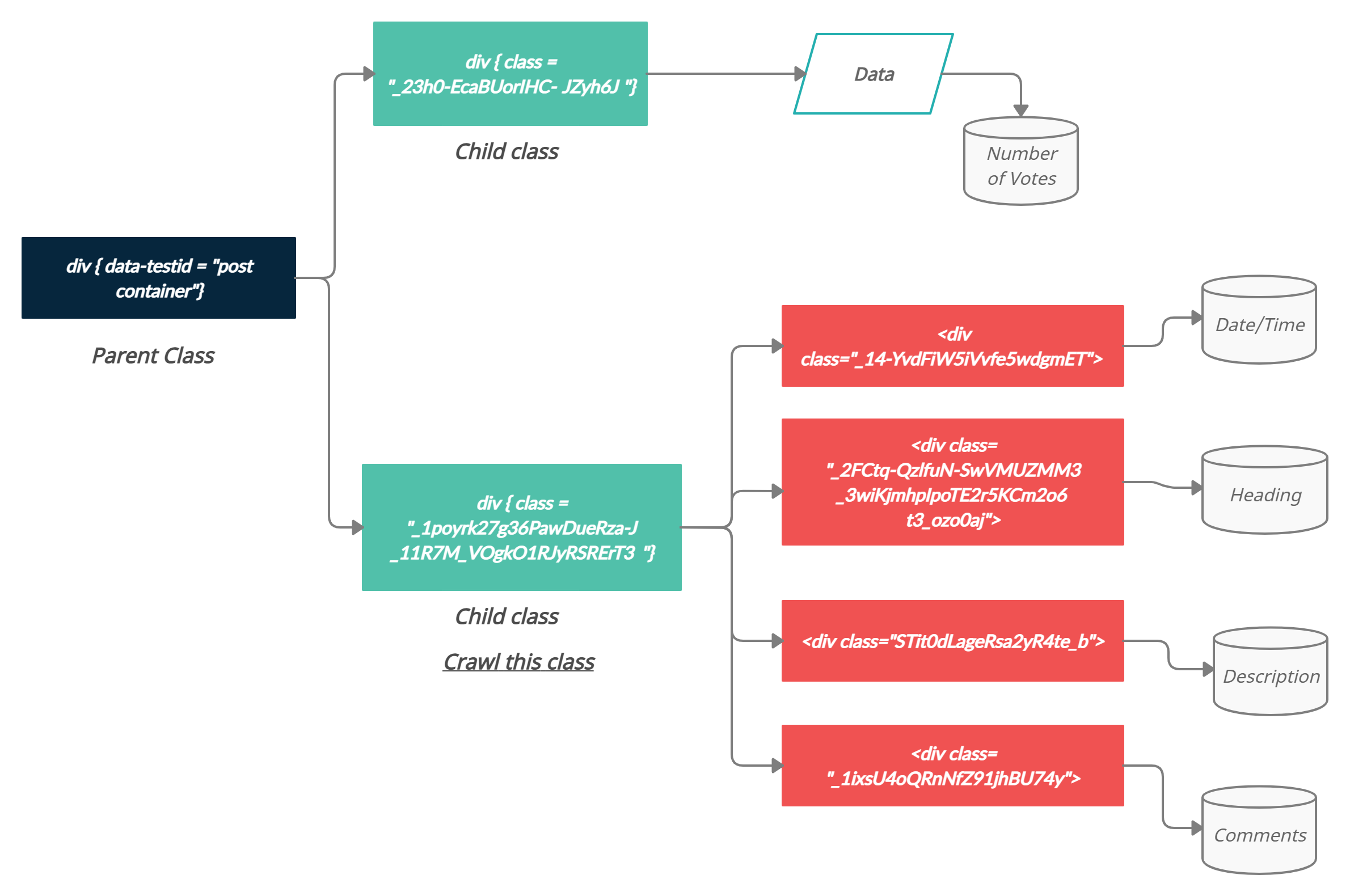
Already shown in the figure, div with attribute value post-container has two more divs inside it. When you dig in the first div, it has the data (i.e., vote section). And the second div has data (i.e., the post date/time section, heading section, description section, and comments section). Here, we need to scrape only the heading and its description section. So, we need to crawl the second div inside the div that has its attribute value post container.
When you dig in the second div, as already mention, it contains four other sub-divs (i.e., post date/time, heading, description, and comments sections). Now we need to find which div stores the corresponding section. So while using the command (i.e., Ctrl+Shift+C) and hovering your mouse over the heading, you get its consisting div section in the inspect window that stores the heading text of that post.
.png)
If you dig inside it, you notice that the heading text is store in the
tag.
.png)
A similar approach we use to find div which contains post description. As you dig inside the div which we crawled, you get the div with class (i.e., STit0dLageRsa2yR4te_b), and when you go inside it, you find all the description of your post is store in
tag.
.png)
Now you know which tag in which div stores the required data (i.e., Post heading and its description) that you want to scrape.
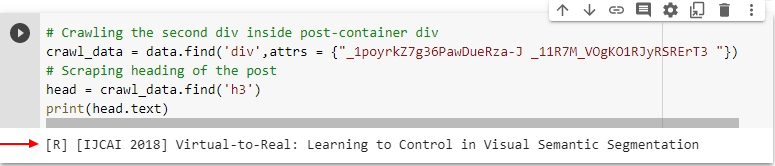
First, we crawl the second div inside the div with an attribute value post container.
# Crawling the second div inside post-container div
crawl_data = data.find('div', attrs = {'class', '_1poyrkZ7g36PawDueRza-J _11R7M_VOgKO1RJyRSRErT3'})
Now we access the heading and its description inside this crawl_data variable one by one. First, access the post heading by scraping the
tag using the method (i.e., find()) and store it in the head variable.
# Scraping heading of the post
head = crawl_data.find('h3')
print(head.text)
Output :
Now access the description by crawling the tags using the method (i.e.,findAll()) and store them in variables (i.e., description). Since the variable (i.e., description) is a set of paragraphs. Then you have to reach each paragraph in variable individually using a for loop and then print it below the heading.
# Accessing the description portion of the post
description = crawl_data.findAll('p')
for para in description:
print(para.text)
Output :
.png)
You can match with the subreddit screenshot below
.png)
Congratulations!!! You have scraped the new post of the subreddit successfully.
What if Multiple Posts?
What if you want to scrape multiple posts instead of a single new post. Yeah, you can do it too. You have to make a few changes to your previous code.
# Previously you crawled data using .find() method which is only for single post
# for multiple replace .find() with .findAll() method with same parameters
crawl_multiple_data = data.findAll('div', attrs = {"_1poyrkZ7g36PawDueRza-J _11R7M_VOgKO1RJyRSRErT3"})
Now, crawl_multiple_data is a set of divs. So, you have to access them individually using for loop.
num=0 # for indicating number of heading
# Accessing each div or we can say each post individually
for crawl_post in crawl_multiple_data:
# Scraping heading of the post
head = crawl_post.find('h3')
num+=1
print(f"Heading{num}:t", head.text, "nn")
# Accessing the description portion of the post
description = crawl_post.findAll('p')
for para in description:
print(para.text,"n")
Output :
.png)
Do all posts are described in Text only?
No. When you scroll down, you get that some posts description is media like Video or image.
.png)
So, when you try to scrape these posts using the previous code, you get a heading with no description as an output. Check the earlier output image. There is no such description between the second heading and the third heading.
When you inspect those posts, you will find they did not have any paragraph (
) tag inside of class (i.e., STit0dLageRsa2yR4te_b ). So, how can you assure that if there is no
tag in crawled data, instead of an empty place, simply show a message (e.g., “Content-type: Media”), in the output screen instead of leaving us with an empty section.
This problem would be solved using python conditionals (i.e., if/else).
# for media content
# After crawling description
# put conditions over it
if description:
print("Content-type:t Text")
for para in description:
print("n", para.text)
else:
print("Content-type:t Media")
Output :
.png)
Are all posts of the same class?
Almost all are of the same class except for article posts.
.png)
Then how to scrape them?.
You can scrape them easily, placing their class in the attrs section of our crawl_multiple_data and leaving the whole code unchanged.
# Adding article posts class in attrs section of crawl_multiple_data
crawl_multiple_data = data.findAll('div', attrs={"_1poyrkZ7g36PawDueRza-J _11R7M_VOgKO1RJyRSRErT3 ", "_1poyrkZ7g36PawDueRza-J _2uazWzYzM0Qndpz5tFu3EX"})
Output :
.png)
.png)
Great, you made your first subreddit crawler.
Next Steps
Since you have completed your first subreddit crawler, then what next?
What should you do after it?
You have two choices from here:
- either you can choose to make further advancements in code or
- either you can take on more beginners projects like this
Few Suggestions for Advancing the crawler:
- Try to scrape the time of posts when they get posted and show it in the output screen between heading and content.
- Try to scrap the number of upvotes and downvotes the post got and show it in the output screen between heading and content.
- You can also scrape the hottest posts of this week or month in that subreddit. And exhibit them in the Output screen according to ranking.
- You can even attempt to scrap the discussion related to a specific topic (e.g., Career, Jobs).
Frequently Asked Questions
Q1. How do I start a web scraping project?
A. To start a web scraping project, follow these steps:
1. Define the project scope: Determine the data you want to extract and the websites you’ll be scraping.
2. Choose a programming language: Python is popular for web scraping due to its rich ecosystem of libraries like Beautiful Soup and Scrapy.
3. Understand the website’s terms of service: Ensure you comply with legal and ethical guidelines.
4. Identify the data source: Analyze the website’s structure and determine the HTML elements containing the desired data.
5. Write the scraping code: Use libraries like Beautiful Soup or Scrapy to navigate and extract data from web pages.
6. Handle data storage: Decide how to store the scraped data, such as in CSV, JSON, or a database.
7. Test and iterate: Validate your code and make necessary adjustments to handle edge cases or dynamic websites.
8. Scale responsibly: Implement rate limits and respect the website’s server resources.
9. Monitor and maintain: Regularly check for changes in website structure or data format and update your code accordingly.
Remember to be mindful of legal and ethical considerations and always respect the website’s terms of service and privacy policies.
Q2. Is web scraping legal 2023?
A. In general, web scraping may be legal if it is done for personal use, with public data, or with permission from the website owner. However, scraping protected or copyrighted information, sensitive personal data, or violating the terms of service of a website may be illegal. It’s crucial to review the website’s terms of service, robots.txt file, and any applicable laws before engaging in web scraping activities.
Conclusion
This project helps you apply learned concepts in the Introduction to web scraping using the python course by Analytics Vidhya in the real world.
Remember, the dirtier your hands get with this type of project, the more you will become comfortable with this skill. While if you have any queries related to this project or a new approach to scrap Reddit posts. Then feel free to discuss with me on my LinkedIn or in the comments below.
Stay tuned to Analytics Vidhya for my upcoming exciting articles.
The media shown in this article are not owned by Analytics Vidhya and are used at the Author’s discretion.






