Overview
Recently I worked on an SAS migration project where we converted all the SAS batch jobs to pySpark and deployed them on EMR. In the initial development phase, we used to get a few environmental errors which took lots of time to debug and get to the root cause. We realized that these could be avoided just by setting a few parameters and I decided to share those.
As we dealt with huge data and these batch jobs involved joins aggregation and transformations of data from various data sources, we encountered some performance issues and fixed those. So I will be sharing a few ways to improve the performance of the code or reduce execution time for batch processing.
Introduction
In the landscape of data migration and processing, the transition from SAS batch jobs to pySpark on EMR represents a pivotal evolution towards enhanced efficiency and scalability. This shift, however, brought to light a myriad of challenges, ranging from perplexing environmental errors to performance hurdles. Through meticulous exploration and experimentation, we uncovered a treasure trove of optimization techniques, poised to revolutionize our approach to data manipulation and computation. Harnessing the power of pySpark, datasets were meticulously curated and APIs were meticulously employed, optimizing performance at every turn.
From fine-tuning configuration parameters to leveraging powerful modules such as Databricks, each facet of our exploration contributed to a comprehensive arsenal of optimization strategies. This article serves as a beacon for practitioners seeking to navigate the complexities of big data processing, offering practical insights and best practices to propel their endeavors toward unprecedented levels of performance and productivity.
This article was published as a part of the Data Science Blogathon.
Table of contents
Initialize pyspark
import findspark
findspark.init()It should be the first line of your code when you run from the jupyter notebook. It attaches a spark to sys. path and initialize pyspark to Spark home parameter. You can also pass the spark path explicitly like below:
findspark.init('/usr/****/apache-spark/3.1.1/libexec')
This way the engine recognizes it as a spark job and sends it to the correct queue. Also when you proceed with importing other packages into your code it will import a compatible version according to pyspark, else you might get the incompatible JVM error in a later part of the code which is hard to debug.
Create Spark Session with Required Configuration
from pyspark.sql import SparkSession,SQLContext
sql_jar="/path/to/sql_jar_file/sqljdbc42.jar"
spark_snow_jar="/usr/.../snowflake/spark-snowflake_2.11-2.5.5-spark_2.3.jar"
snow_jdbc_jar="/usr/.../snowflake/snowflake-jdbc-3.10.3.jar"
oracle_jar="/usr/path/to/oracle_jar_file//v12/jdbc/lib/oracle6.jar"
spark=(SparkSession
.builder
.master('yarn')
.appName('Spark job new_job')
.config('spark.driver.memory','10g')
.config('spark.submit.deployMode','client')
.config('spark.executor.memory','15g')
.config('spark.executor.cores',4)
.config('spark.yarn.queue','short')
.config('spark.jars','{},{},{},{}'.frmat(sql_jar,spark_snow_jar,snow_jdbc_jar,oracle_jar))
.enableHiveSupport()
.getOrCreate())- You can give master as ‘local’ for development purposes but it should be ‘yarn’ in deployment.
- When you use master as ‘local’, it uses 2 cores and a single JVM for both driver and worker. Whereas in ‘yarn’, you have separate JVM for driver and workers and you can use more cores.
- You can add more driver memory and executor memory for some jobs if required to make the execution time faster.
- As a best practice, you should pass jar files for all the available database connections. This could be set either in the spark session or config file. This is because when you connect to an Oracle/SQL/snowflake database using the below code, you might get the “oracle.jdbc.driver.OracleDriver” class not found error if the engine picks an incorrect jar file.
data=spark.read.format("jdbc")
.option("url",tns_path)
.option("dbtable",query)
.option("user",userid)
.option("password",password)
.option("driver","oracle.jdbc.driver.OracleDriver")
.load()Driver name “oracle.jdbc.driver.OracleDriver” could be different for different jar files as it changes sometimes with an update from python/java. As almost all projects have many versions installed in their server with each update there will be multiple jar files available from different versions. So it is advisable to explicitly pass the required jar file path as per the code. This applies to MySQL, snowflake, or any other DB connections as well.
Use the Fetch Size Option to Make Reading from DB Faster
Using the above data load code spark reads 10 rows(or what is set at DB level) per iteration which makes it very slow when dealing with large data. When the query output data was in crores, using fetch size to 100000 per iteration reduced reading time 20-30 minutes. PFB the code:
data=spark.read.format("jdbc")
.option("url",tns_path)
.option("dbtable",query)
.option("user",userid)
.option("password",password)
.option("fetchsize","100000")
.option("driver","oracle.jdbc.driver.OracleDriver")
.load()Use Batch Size Option to Make writing to DB Faster
When the data was in crores, using a batch size of 100000 per iteration reduced writing time by 20-30 minutes. PFB the code:
data.write.format("jdbc")
.option("url",tns_path)
.option("dbtable",schemaname.tablename)
.option("user",userid)
.option("password",password)
.option("fetchsize","100000")
.option("driver","oracle.jdbc.driver.OracleDriver")
.option("batchsize","100000")
.mode('append').save()Handling Skew Effectively
Skew is the uneven distribution of data across partitions. Spark creates partitions in data and processes those partitions in parallel. With default partitioning of spark, the data might be skewed in some cases like join and group by if the key is not evenly distributed. In such cases, when one partition has 1000 records another partition might have millions of records and the former partition waits for the latter to complete, as a result, it can not utilize parallel processing and takes too long to complete or in some cases, it just stays in a hung state. To resolve this we can use repartition to increase the number of partitions before ingestion.
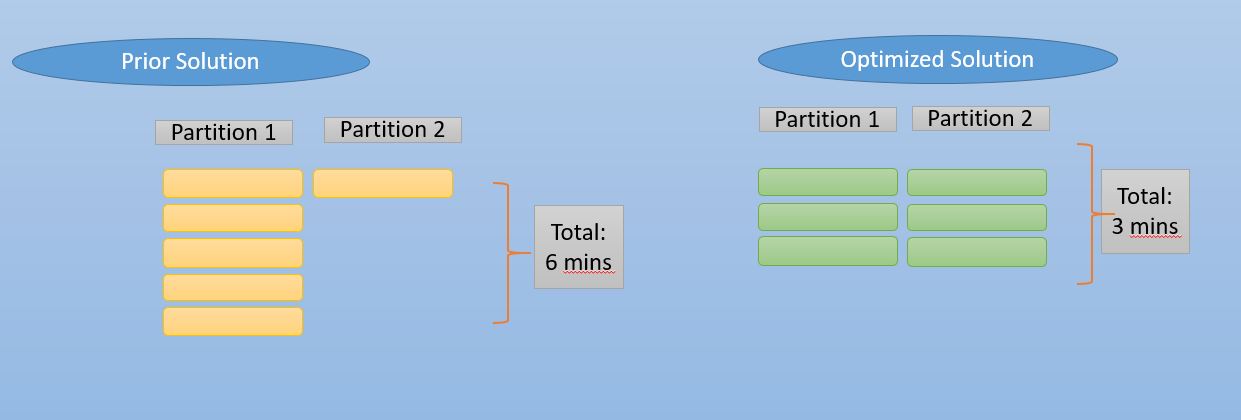
data = data.repartition(10, "term") or
data = data.repartition(10)You can use coalesce to reduce the number of partitions:
data = data.coalesce(3)Before you move on with pyspark best practices, read our article on PySpark for Beginners – Take your First Steps into Big Data Analytics.
Efficient Data Processing Techniques
Cache/Persist Efficiently
In the initial solution, it was fetching the data and doing serialization multiple times, and joining with the second table which results in a lot of iteration. This process was taking hours to complete initially.
Persist fetches the data, does serialization once, and keeps the data in Cache for further use. So next time an action is called the data is ready in cache already. By using persist on both the tables the process was completed in less than 5 minutes. Using broadcast join improves the execution time further. We will be discussing that in later sections.
But you need to be careful while using persist. Overuse of persisting will result in a memory error. So keep clearing your data from memory when they are no longer used in the program.
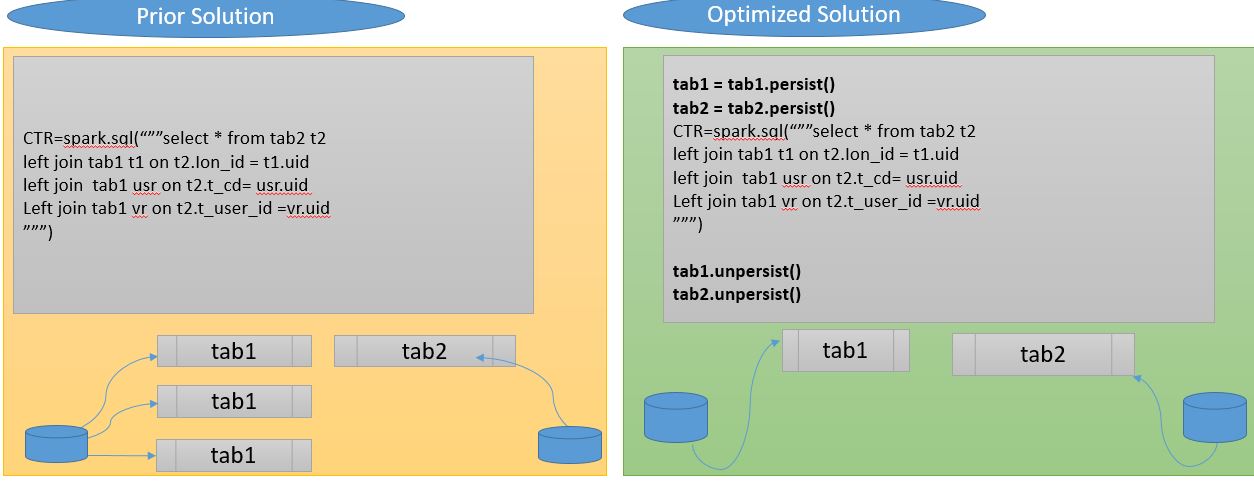
You can also clear all the cache at the end of the job by using the below code:
You can also clear all the cache at the end of the job by using the below code:
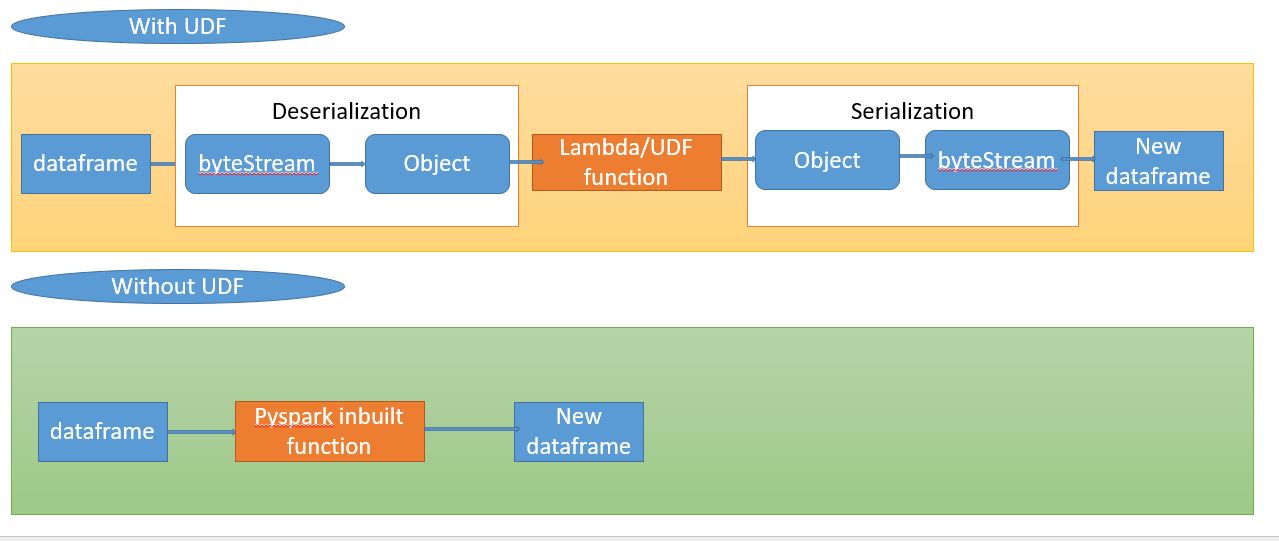
spark.catalog.clearCache()Avoid using UDF Functions unless that is the Only Option
User-defined functions de-serialize each row to object, apply the lambda function and re-serialize it resulting in slower execution and more garbage collection time.
Use of Thread wherever Necessary
If there are multiple independent actions in one job, you can use a thread to call those actions simultaneously. For example, in one job we were reading many huge tables from one schema and writing to another schema. Due to sequential action, the job was taking more than 2 hours. After we used the thread for concurrent writing, the load time was reduced to 30 minutes. Please note you might need to increase the spark session configuration. For optimum use of the current spark session configuration, you might pair a small slower task with a bigger faster task.
Use mapPartitions() instead of map()
Both are rdd-based operations, yet map partition is preferred over the map as using mapPartitions() you can initialize once on a complete partition whereas in the map() it does the same on one row each time.
Miscellaneous
- Avoid using count() on the data frame if it is not necessary. Remove all those actions you used for debugging before deploying your code.
- Write intermediate or final files to parquet to reduce the read and write time.
- If you want to read any file from your local during development, use the master as “local” because in “yarn” mode you can’t read from local. In yarn mode, it references HDFS. So you have to get those files to the HDFS location for deployment.
Please let me know if you have any queries. You can also suggest added best practices to improve performance. You can connect with me using this link.
Conclusion
In conclusion, the journey from SAS batch jobs to pySpark on EMR has been transformative, uncovering a wealth of insights and best practices for efficient data processing. Through meticulous exploration and experimentation, we have addressed environmental errors, optimized performance, and streamlined execution times for batch processing. Leveraging the power of pySpark, along with efficient data engineering techniques, we have navigated challenges with precision, enhancing productivity and scalability.
As we reflect on this journey, it’s evident that good practices such as cache/persist efficiency, avoidance of unnecessary UDF functions, threading where necessary, and utilization of mapPartitions() over the map() have significantly contributed to our success. These techniques, coupled with insights into runtime execution plans and syntax optimizations, have propelled our endeavors toward unprecedented levels of performance and productivity.
Furthermore, adopting a modular and scalable approach to code organization, along with careful consideration of resource management and cluster configuration, has been instrumental in achieving consistent and reliable results. By adhering to coding standards, documentation practices, and version control, we ensure maintainability and collaboration across our team.
Looking ahead, the use cases for machine learning, pandas integration, and further performance tuning beckon us to continue our exploration and refinement of data processing methodologies. By embracing these principles and remaining vigilant in our pursuit of excellence, we stand poised to conquer the ever-evolving landscape of big data processing with confidence and ingenuity.
Frequently Asked Questions
Q1. What are the top tips for improving PySpark’s job performance?
A. Top tips for improving PySpark’s job performance include optimizing Spark configurations for large datasets, handling nulls efficiently in Spark DataFrame operations, utilizing withColumn for efficient data transformations in PySpark code, considering Scala for performance-critical tasks, and exploring SparkContext optimizations. These strategies can enhance job execution speed and resource utilization, leading to better overall performance in PySpark data processing tasks.
Q2. What are some effective strategies for managing memory usage in PySpark?
A. Some effective strategies for managing memory usage in PySpark include optimizing Spark SQL queries to minimize memory overhead, carefully selecting column names to reduce memory footprint, defining and using temporary DataFrames for intermediate results to avoid excessive memory consumption, leveraging aggregate functions like avg to compute statistics efficiently, considering AWS infrastructure options for scaling memory resources as needed, and implementing unit tests to validate memory management strategies and ensure optimal performance.
Q3. What are some common performance pitfalls in PySpark and how can they be avoided?
A. Some common performance pitfalls in PySpark include:
1. Data shuffling: Avoid unnecessary data shuffling by carefully designing transformations and joins to minimize data movement across partitions.
2. Overuse of collect(): Minimize the use of collect() to bring data to the driver node as it can lead to out-of-memory errors with large datasets.
3. Too many small files: Consolidate small files into larger ones to reduce overhead and improve read/write performance.
4. Inefficient UDFs: Refactor user-defined functions (UDFs) to leverage built-in PySpark functions for better performance.
5. Lack of partitioning: Partition data appropriately to distribute workload evenly and optimize parallelism.
The media shown in this article are not owned by Analytics Vidhya and are used at the Author’s discretion.







very nice informatic article