Better EDA with 3 Easy Python Libraries for Any Beginner

Image Source: Author
Data Science enthusiasts know that raw data needs to be processed quite a bit before it can be fed to a machine learning model for solving a real-world problem. For this, a series of steps are to be followed to prepare and format the data, depending upon the type of problem at hand (regression or classification). A major chunk of this process involves assessing the dataset in all possible ways to find valuable correlations (feature dependencies on each other and target) and exclude noise (inconsistencies or outliers, i.e. non-conforming data points). To explore any dataset, Python is one of the most powerful data analysis tools available, and additionally, there are equally powerful Python libraries to visualize the data even better. These definitely help to make the lives of Data Science enthusiasts easier by simplifying the amount of Python code required to perform Exploratory Data Analysis aka EDA.
Thus, to make the Data more meaningful or to extract more value from the available data, it is essential to interpret and analyze it quickly. This is where the Data visualization libraries for Python save the day by generating graphical representations and making the data speak. This way, we can discover all possible trends and patterns underlying a large volume of data.
Today, Data Science and Machine Learning are not just accessible to people with a strong Computer Science background. Rather, there is an increasing trend of welcoming professionals from different industries that share the same passion for data albeit with some statistics knowledge into this domain. This is why people from diverse backgrounds and educational profiles are inclined to try out what Data Science and AI have to offer.
But for a beginner, who is just getting started with Machine Learning, having too many options for understanding data is challenging and sometimes, overwhelming. We all want our data to look pretty and be presentable for quicker decision-making. Overall, EDA could be a time-consuming process as we carefully look through the multiple plots to find which features are important and bear a strong impact on the outcome. Additionally, we look for ways to handle missing values and/or outliers, fix the imbalance in the datasets, and many such challenging tasks. Thus, it is a tough choice when it comes to choosing the best library for one’s EDA needs. Hence, starting with automated EDA libraries can be a good learning experience for anyone starting with their Machine Learning journey. These libraries present a good overall view of the data and also are easy to use. With just a few lines of simple python code, these libraries save time and allow a newbie to focus more on understanding how these different plots can be used to make a sense of the data. However, beginners surely need to have a basic understanding of the plots generated by these libraries.
In this article, we are discussing three interesting auto-EDA Python libraries for beginners. For this beginner-friendly tutorial, we will use the inbuilt ‘iris’ dataset from sklearn.
We would be importing the packages and libraries first
If we are not using AutoEDA, here’s a list of commands typically used in an EDA to print different information about the DataFrame/dataset (not necessarily in the same order).
-
df.head() – first five rows
-
df.tail() – last five rows
-
df.describe() – basic statistical information about percentile, mean, standard deviation etc. of a dataset
-
df.info() – summary of the dataset
-
df.shape() – number of observations and variables in the dataset i.e. dimension of the data
-
df.dtypes() – data types (int, float, object, datetime) of variables
-
df.unique()/df.target.unique() – unique values in the dataset/target column
-
df[‘target’].value_counts() – distribution of target variable for classification problems
-
df.isnull().sum()- count null values in the dataset
-
df.corr() – correlation information
-
And so on..
See how many commands we had to use to find insights in the data. AutoEDA libraries would quickly do all this and much more with a few lines of Python code. But before we start, let’s check the installed python version first as these libraries require Python >=3.6. To get the version info, use the following command in Colab.
print(python --version) # check installed Python version
Once we have the correct Python version, we can now start with the AutoEDA.
1. Pandas Profiling 3.0.0
First, the auto-EDA library is an open-source option that is written in python. It generates a comprehensive and interactive HTML report for the given dataset. It is able to describe different aspects of the dataset like the type of variables, handling missing values, presence of null values along statistical values – mean, median, mode of the dataset. It also prints the correlation matrix using different correlations for numerical and categorical variables.
To install the library, enter and run the following command in a cell on a jupyter notebook or Colab notebook.
!pip install pandas-profiling
EDA using Pandas Profiling
We will first import the main package – pandas to read and handle the dataset.
Next, we will import pandas profiling. That’s it!
import pandas_profiling #Generating PandasProfiling Report report = pandas_profiling.ProfileReport(df)
In case, you run into a ‘TypeError: concat() got an unexpected keyword argument ‘join_axes’ error on Colab notebook, simply reinstall the package using the following command
pip install https://github.com/pandas-profiling/pandas-profiling/archive/master.zip
From the report, a beginner can easily understand that there are 5 variables in the iris dataset – 4 numerical and the outcome variable is categorical. Also, there are 150 samples in the dataset and no missing values.
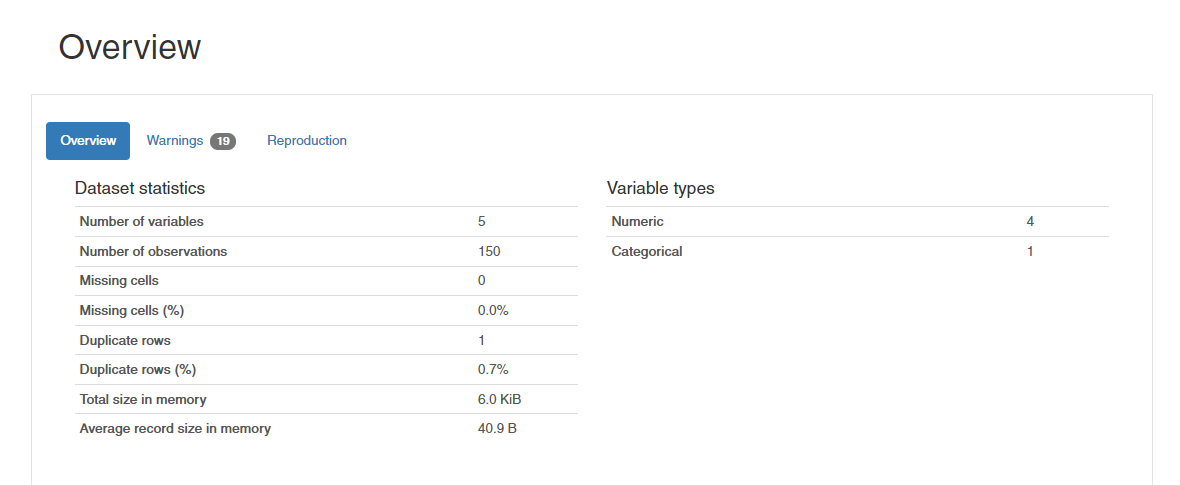
Some sample plots below generated by pandas profiling help in understanding the correlations, unique and missing values for which we have listed the commands earlier.
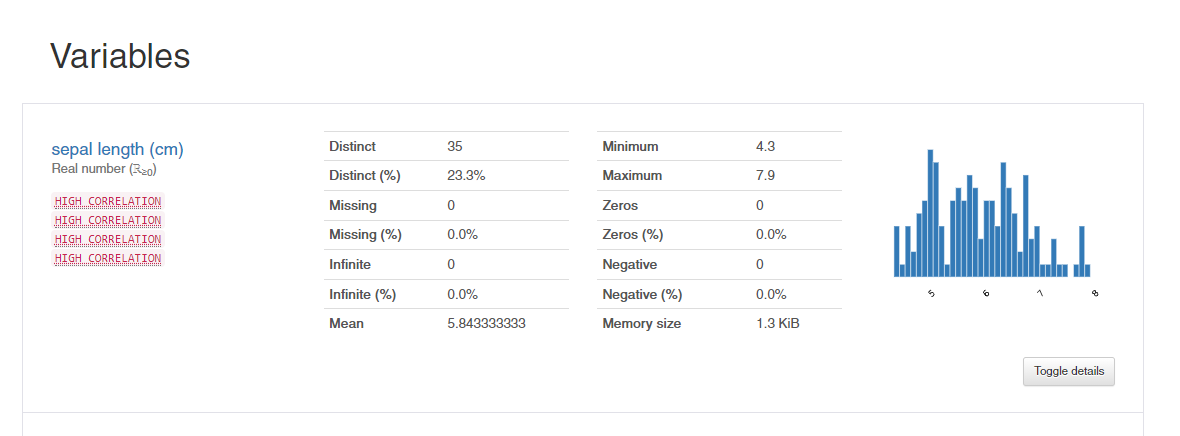
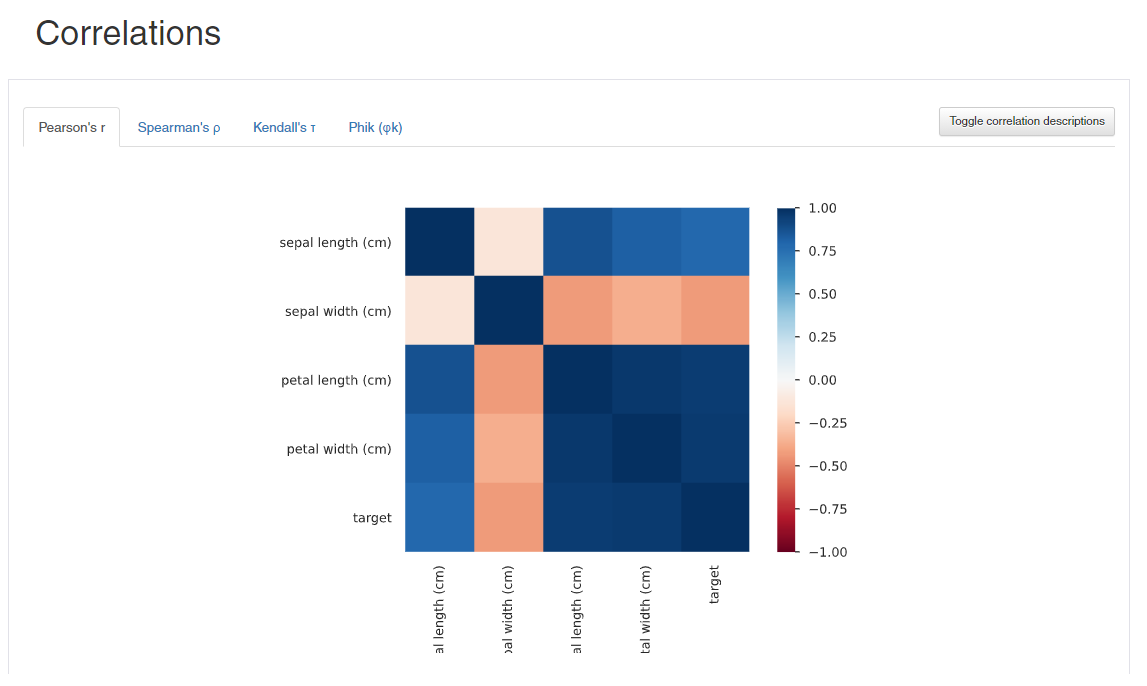
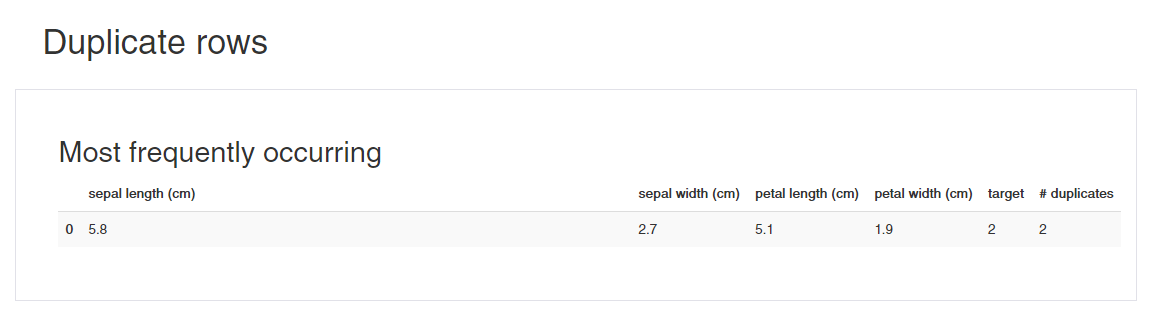
Overall, the Pandas Profiling library is quite impressive in generating quick insights from the dataset.
2. Sweetviz 2.1.3
This is also an open-source Python library to carry out an in-depth style EDA using only two lines of code. The report generated by this library for the dataset is available as a .html file that can be opened in any browser. With Sweetviz, we can check –
-
how dataset features are correlated to the target value
-
visualize the test and train data as well as compare them. We can use analyze(), compare() or compare_intra() to evaluate the data and generate the reports.
-
plot correlations for numerical and categorical variables
-
summarize information on missing values, duplicate data entries, and frequent entries along with numerical analysis i.e. interpreting statistical values
To install the library, enter and run the following command in a cell on a jupyter notebook or Colab notebook.
!pip install sweetviz
EDA using Sweetviz
Similar to the earlier section, we will first import pandas to read and handle the dataset.
Next, we simply import sweetviz to explore the data.
import sweetviz as sv
#Generating Sweetviz report
report = sv.analyze(df)
report.show_html("iris_EDA_report.html") # specify a name for the report
This is how a typical Sweetviz report would look
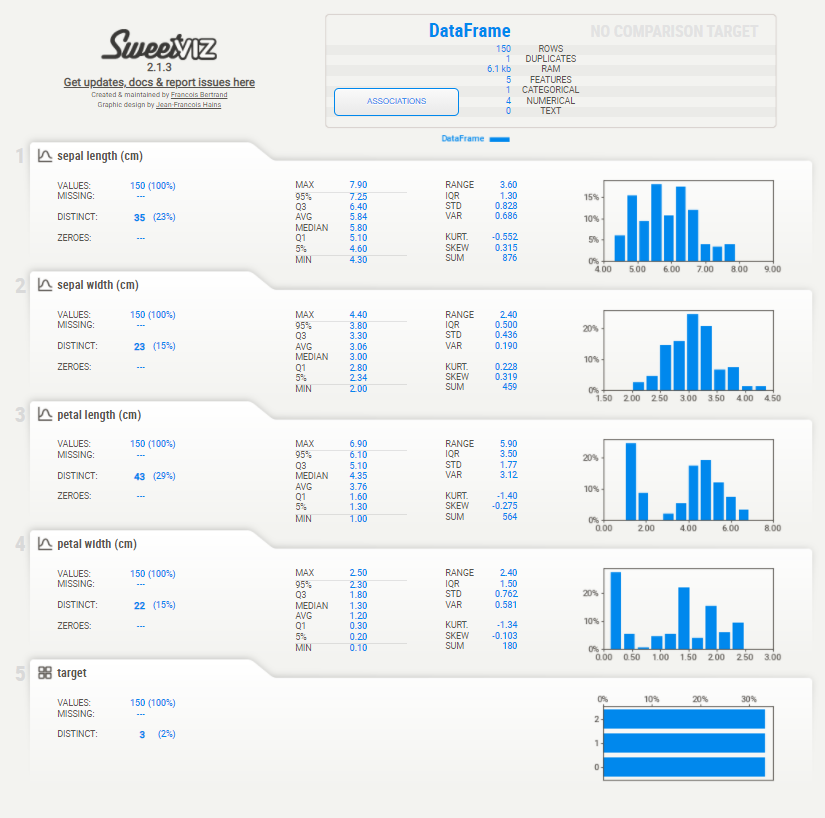
Indeed impressive and pretty. These .html reports generated are not directly compatible with Colab and hence, will not open automatically upon clicking. You can find the report in the files section of Colab for downloading and then they can be opened in the browser.
3. AutoViz 0.0.83
To install the library, enter and run the following command in a cell on a jupyter notebook or Colab notebook. (Requires: Python >=3.7)
from autoviz.AutoViz_Cla ss import AutoViz_Class AV = AutoViz_Class()
#Generating AutoViz Report #this is the default command when using a file for the dataset
filename = ""
sep = ","
dft = AV.AutoViz(
filename,
sep=",",
depVar="",
dfte=None,
header=0,
verbose=0,
lowess=False,
chart_format="svg",
max_rows_analyzed=150000,
max_cols_analyzed=30,
)
Since we are using a dataset from the library we use the ‘dfte’ option and not the filename for EDA.
#Generating AutoViz Report
filename = "" # empty string ("") as filename since no file is being used for the data
sep = ","
dft = AV.AutoViz(
'',
sep=",",
depVar="",
dfte=df,
header=0,
verbose=0,
lowess=False,
chart_format="svg",
max_rows_analyzed=150000,
max_cols_analyzed=30,
)
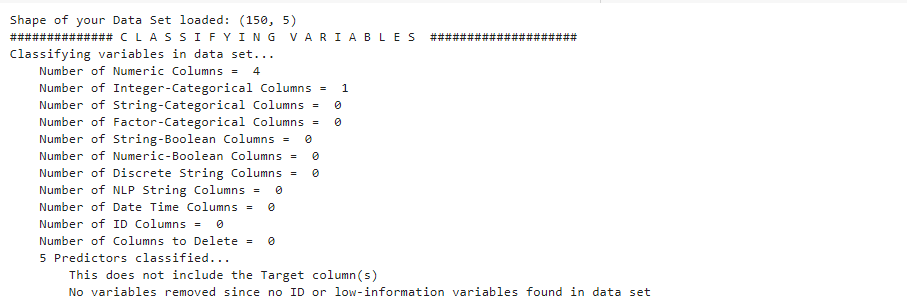
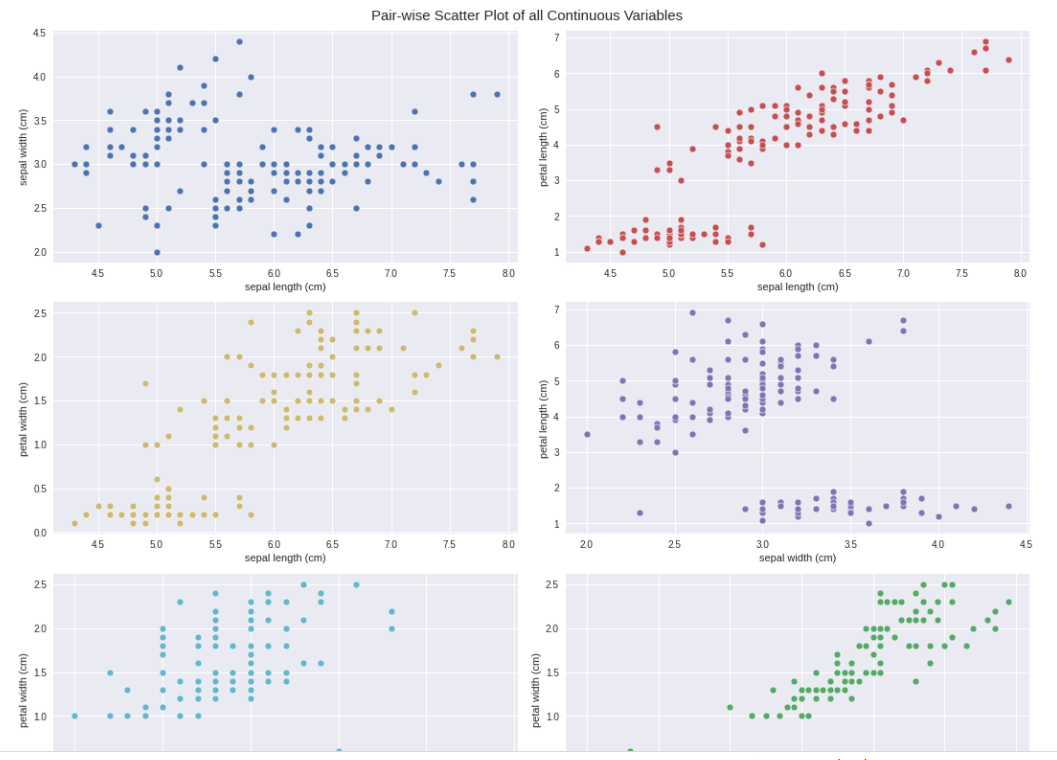
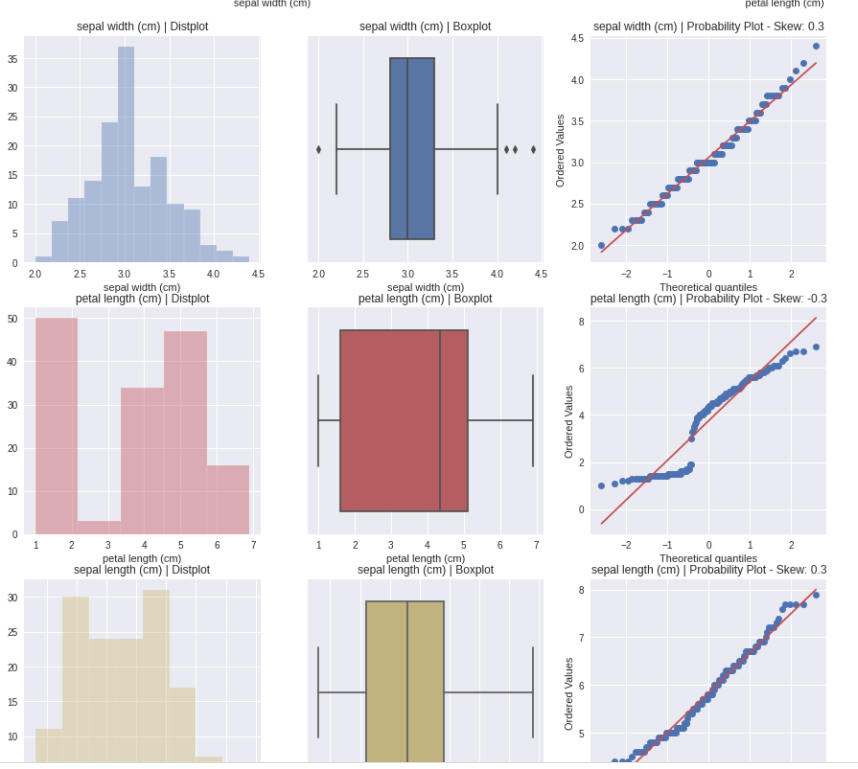
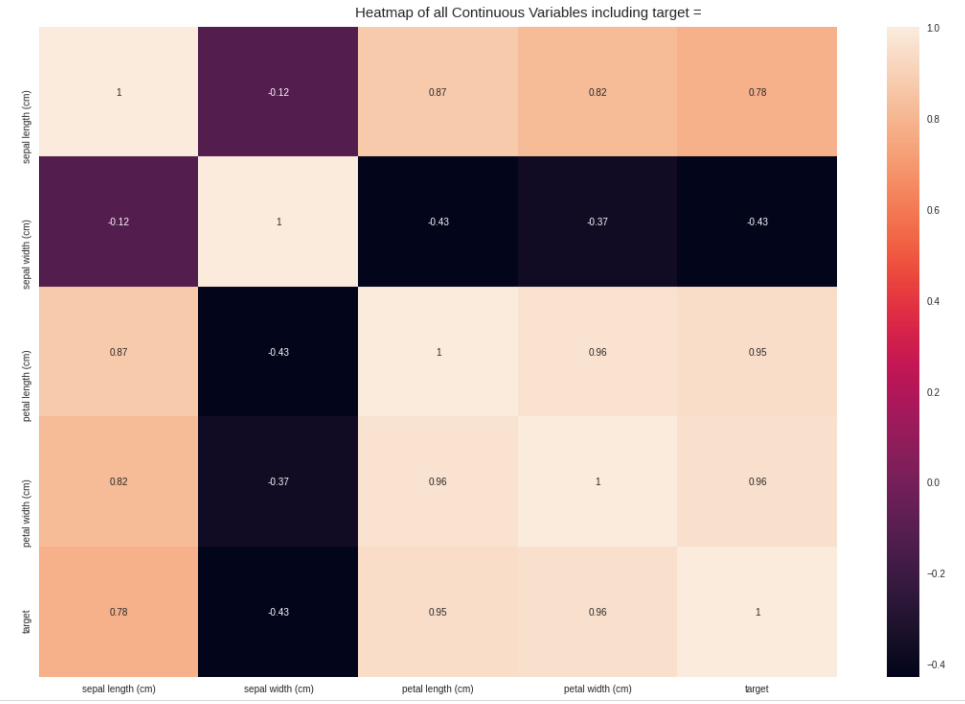
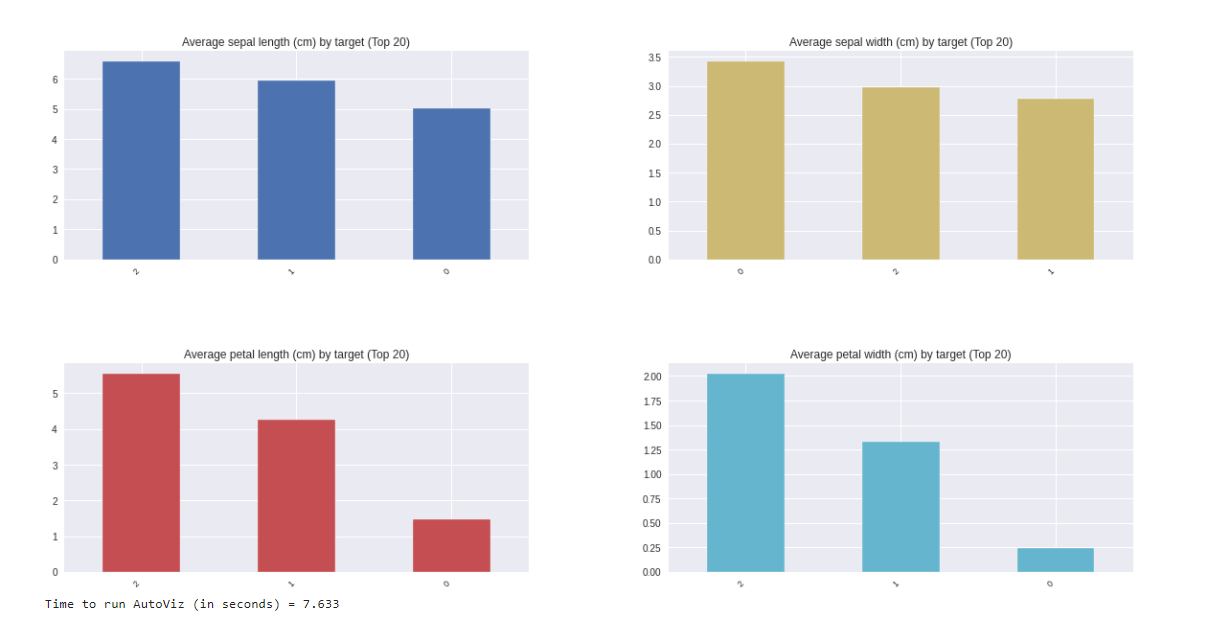
AutoViz report included information on the shape of the dataset along with all possible plots ranging from bar charts, violin plots, correlation matrix (heat map), pair plots etc. All this information with one line of code is surely useful for any beginner.
Thus, we have automated the data analysis for a small dataset using three AutoEDA libraries with minimum code. All the above code is available in my GitHub repository as well as kaggle.
Conclusion
There are other interesting AutoEDA libraries like Dora, D-Tale, and DataPrep which are similar to these three libraries discussed in this article. However, from a beginner’s point of view, Pandas Profiling, Sweetviz, and AutoViz seem to be the simplest in generating the report as well as presenting the insights from the dataset.
Besides, for anyone working on Data Science and AI, AutoEDA can be very helpful to get an initial impression of the data at hand. However, these Auto EDA libraries tend to be very slow in preparing the complete reports while processing large datasets. But these are definitely helpful in speeding up the EDA for beginners to advanced users.
I frequently use these libraries when starting the EDA to uncover interesting trends and patterns quickly with minimum code. I hope you will find these libraries interesting and useful too!
References:
https://pypi.org/project/pandas-profiling/[accessed: Aug-09-2021]
https://pypi.org/project/sweetviz/ [accessed: Aug-09-2021]
https://pypi.org/project/autoviz/ [accessed: Aug-09-2021]
Author Bio:
Devashree has an M.Eng degree in Information Technology from Germany and a Data Science background. As an Engineer, she enjoys working with numbers and uncovering hidden insights in diverse datasets from different sectors to build beautiful visualizations to try and solve interesting real-world machine learning problems.
In her spare time, she loves to cook, read & write, discover new Python-Machine Learning libraries or participate in coding competitions.
You can follow her on LinkedIn, GitHub, Kaggle, Medium, Twitter.








It's very helpful. Thanks.