This article was published as a part of the Data Science Blogathon
Introduction
Recommender System is a software system that provides specific suggestions to users according to their preferences. These techniques may provide decision-making capabilities to the user. Items refer to any product that the recommender system suggests to its user like movies, music, news, travel packages, e-commerce products, etc.
 Image Source : Google Images
Image Source : Google ImagesA Recommender system is built for a specific type of application depending on the items it recommends and accordingly its graphical user interface and design are customized. Recommender system development emerged from the general idea that individuals rely on others to take regular decisions in their life. The explosive growth in volume and variety of information available on the web has contributed to the development of recommender systems which has, in turn, led to an increase in profit and benefits to the user.
Types of Recommender Systems
There are three broad categories of recommender systems:
.jpg)
Image Source: Google images
1.Collaborative filtering-based systems:
These systems recommend items to users based on the similarity computation of these users to similar users in the system or based on the items similar to the items liked by the user in past. So collaborative filtering can be further divided into two categories-
- i) user-based collaborative filtering– The recommender system tries to find out similar users to the target user by calculating certain similarity measures and then suggest items to the target user based on similar user preferences. Similarity calculation is an important task here.
- ii.) item-based collaborative filtering– The recommender system tries to find out items based
on previous user preferences of the user and then recommend similar items to
the user. These items might be of interest to the user.
2. Content-based Recommender Systems:
The system focuses on the properties of the items to be suggested to the users. For example, if a YouTube user has watched comedy videos then the system will recommend comedy genre videos to him. Similarly, if a Netflix user has watched movies of a particular director then the system will recommend those movies to him.
3. Hybrid Systems: These systems are a combination of collaborative and content-based systems.
Building a Course Recommender System
Step 1: Reading the dataset.
#importing necessary libraries. import pandas as pd data = pd.read_csv(r"C:UsersDellDesktopDatasetdataset.csv") data.head()
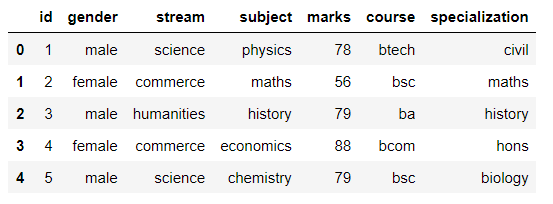
About the dataset:
It includes data of students enrolled in high school with their ids, streams, favorite subject, and marks obtained in class 12. It also includes result columns of the course and specialization they pursued in graduation.
We would like to recommend courses to students with similar marks, streams, and favorite subjects.
Now we will build a content-based recommender system that could recommend courses to students based on their basic information.
Step 2: Creating a combined description of every student in the dataset.
descriptions =data['gender'] +' '+ data['subject'] + ' ' + data['stream'] +' '+ data['marks'].apply(str) #Printing the first description descriptions[0]
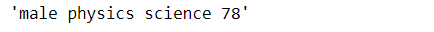
Step 3: Creating a similarity matrix between the students.
# import TfidfVector from sklearn.
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import linear_kernel
def create_similarity_matrix(new_description, overall_descriptions):
#Append the new description to the overall set.
overall_descriptions.append(new_description)
# Define a tfidf vectorizer and remove all stopwords.
tfidf = TfidfVectorizer(stop_words="english")
#Convert tfidf matrix by fitting and transforming the data.
tfidf_matrix = tfidf.fit_transform(overall_descriptions)
# output the shape of the matrix.
tfidf_matrix.shape
# calculating the cosine similarity matrix.
cosine_sim = linear_kernel(tfidf_matrix,tfidf_matrix)
return cosine_sim
The function create_similarity_matrix() is used to generate the cosine similarity matrix of the students’ descriptions.
It firstly appends the new student description to whom recommendations are being made to the overall descriptions.
Then, Student descriptions needed to be converted into word vectors(vectorized representation of words). So we will use TFIDF (Term Frequency Inverse document frequency) for converting them. the TF-IDF score is the frequency of a word occurring in a document, down-weighted by the number of documents in which it occurs. This is done to reduce the importance of words that frequently occur in descriptions and, therefore, their significance in computing the final similarity score.
The above function then finally outputs the cosine similarity matrix.
Step 4: Define get_recommendations() function.
def get_recommendations(new_description,overall_descriptions): # create the similarity matrix cosine_sim = create_similarity_matrix(new_description,overall_descriptions) # Get pairwise similarity scores of all the students with new student. sim_scores = list(enumerate(cosine_sim[-1])) # Sort the descriptions based on similarity score. sim_scores = sorted(sim_scores,key =lambda x:x[1],reverse= True ) # Get the scores of top 10 descriptions. sim_scores = sim_scores[1:10] # Get the student indices. indices = [i[0]for i in sim_scores] return data.iloc[indices]
Step 5: Recommend the course to a new student.
new_description = pd.Series('male physics science 78')
get_recommendations(new_description,descriptions)

Showing the top two recommendations.
Issues in Recommender Systems:
1. Cold Start Problem :
Whenever a new user enters a recommender system, the question arises of what to recommend him/her and on what basis as previous data is not available and similarity calculation could not be performed. One solution to this problem is to make the new users enter a small introduction form containing basic information about a person’s interests, hobbies, occupation, and creating a basic user profile and then recommending items to the new user. This would solve the cold start problem to a great extent.
2. Data Sparsity Problem:
The major issue in a recommender system is the unavailability of appropriate data which is the main requirement for the recommendation process. Many users don’t bother to review items they bought. As a result, the user-item rating matrix has many sparse entries which degrade the performance of the similarity calculation algorithm. So one solution is to predict sparse entries and many researchers have given algorithms to predict these ratings such as a negative weighted one slope algorithm.
3. Changing Dataset:
With the increase in the amount of data every day, there is an increase in the inclusion of data in the previous dataset of the recommender system which may alter the overall structure and composition of the dataset. Both new users and new items needed to get included in the dataset. So this change needed to be accommodated in the dataset.
4. Scalability Problem:
In a practical scenario, it is not always possible to find similar users and similar items every time and prevent the system from failure. So building a scalable recommender system is a major concern.
5. Shilling attack:
Shilling attack is defined as the process of inclusion of fake profiles and biased reviews and ratings to bias the entire recommendation process. A malicious attacker may inject these profiles so as to increase/decrease recommending frequency of target items.
Benefits of a recommender system:
1. Increasing profit by increasing the number of items sold: One of the major objectives of building commercial recommender systems is to enhance business and increase profit. This could be done by suggesting users new items which may attract the users and they may buy more items as compared to those without Recommender Systems.
2. Enhanced user satisfaction: The main motive of any business application should be user satisfaction as it enhances overall business growth and the healthy survival of the company. A well-designed recommender system enhances the user’s overall experience in using that application. They may find recommendations useful and relevant to user needs. So the major purpose of RS is to satisfy the users and make them happy.
3. Extraction of useful patterns: The recommender system provides a way of extracting useful patterns of users’ needs and preferences that could serve as strategic information for the business. For example, if a business company could get insights about which product is being extensively liked b its customers and which product is not being liked then they could change their product list.
4.Provide more diverse items to users: Sometimes
it is impossible to find the items personally that a recommender system may
provide. This increases the variety of items that users get from
recommendations.
End Notes
Nowadays, Recommender systems have become extremely popular. Many popular e-commerce websites such as Amazon have employed personalized recommender systems for their users to suggest items that they could buy learned from their past behaviour. RS have increased their profits. Websites like YouTube and Netflix suggest movies and music to users based on genres, actors, artists of movies that have been previously watched by the customers. Travel websites like MakeMyTrip provide customized travel packages to the customers based on their preferences and deal with a variety of users through recommender systems.
And finally, it doesn’t go without saying.
Thanks for reading!







Hi all, Can anyone share the raw data file link ?
Hi, PLease where can i get this daaset?