This article was published as a part of the Data Science Blogathon
Introduction
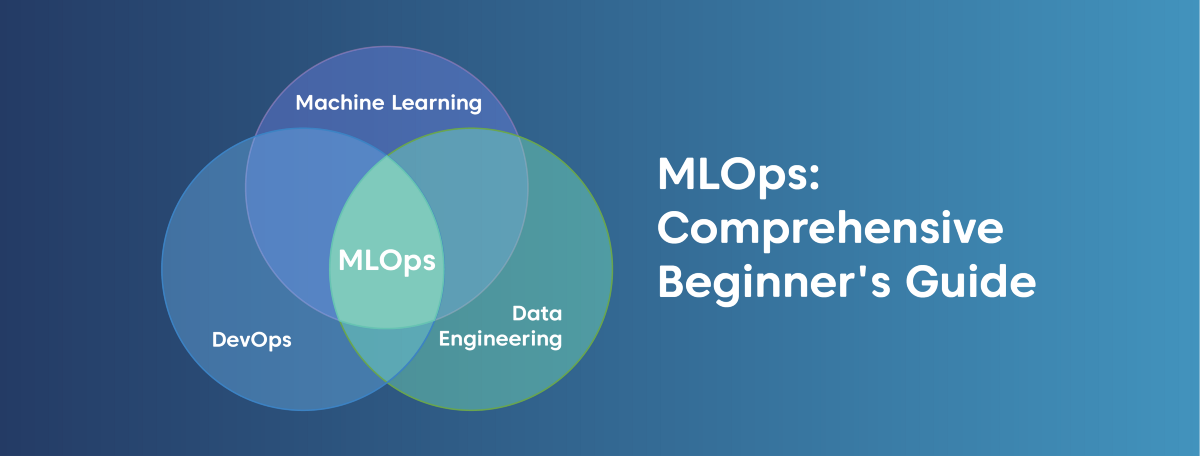
Image link: https://medium.com/sciforce/mlops-comprehensive-beginners-guide-c235c77f407f
Is your company looking to expand in the area of machine learning? A lot of companies are looking to explore machine learning to help bring more benefits. More often than not, it is not easy to begin implementing a live machine learning project without any prior experience. ML can boost up business in all the industries quite easily. The fintech sector has in fact taken to adopting scorecards for all their lending automation. Similarly, FMCG companies have taken up customer segmentation and personalized offers to bring in more business as is evident from all the e-commerce websites.
So What is MLOps?
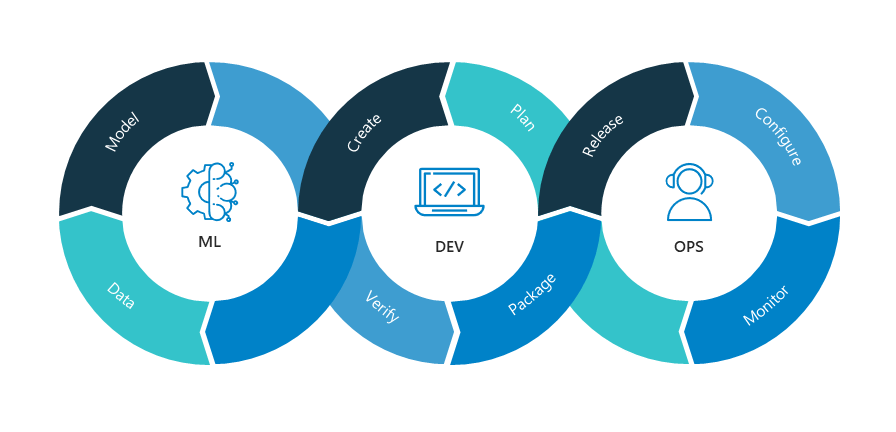
Image link: https://nealanalytics.com/expertise/mlops/
MLOps is nothing but the amalgamation of machine learning, data engineering as well as DevOps. Every company is looking to expand in the field of machine learning. To develop and deploy an ML project you cannot use a regular DevOps technique. You need to use something called MLOps. It is nothing but the combination of all three factors – data, ML, and regular DevOps.
Scope of MLOps
Although tremendous amounts of new projects have been developed using machine learning, there is still scope for more. Such is the nature of ML. Every company is tapping into the potential offered by machine learning. Take the BFSI (Banking and Finance sector) for example, ML-based scorecards have been built by many of the institutions in order to automate the loan processing journeys.
All the tasks which used to rely on human instinct-based resolutions are being automated using ML-based approaches. Every vertical, right from the automobile industry, finance, e-commerce, etc has begun tapping into the huge potential offered by ML. Companies offer you products based on your search histories, personalize their offerings for you, and do much more. These are some of the interesting use cases of ML.
Benefits of MLOps
Some of the benefits of MLOps are as follows:
- Creating ML models is one thing and deploying them is another thing. MLOps helps in deploying them in a much faster and easier way.
- Consider this scenario. You create an ML model and deploy it separately. After some time validating it and fine-tuning the parameters and then redeploying the model becomes a huge hassle involving multiple people and multiple tasks. This takes up a huge chunk of time, effort, and money. MLOps avoids all this since the whole project is integrated in a seamless manner.
- You can also easily reuse the model for other use cases.
- Since the validation and reporting are integrated into the system, monitoring becomes a very easy job.
Challenges of MLOps
So what are the common challenges faced while deploying an MLOps project?
- For any ML-based project, the first and foremost requirement is the infrastructure. A huge amount of computing power and memory capacity is generally required. If only on-premises servers are relied upon, then adequate planning and arrangements need to be made for the project.
- It would be a good idea to expand to cloud architecture to avoid this hassle as scaling up and scaling down becomes an easy task. A lot of companies are moving towards AWS services for this purpose.
- A process of continuous monitoring is required. ML models may have been validated before moving to the production environment but it doesn’t mean that they will stay relevant forever. Frequent monitoring of the parameters and changing the model variables are required periodically.
Process of MLOps
MLOps has 5 main steps to be taken note of. These steps can help you to complete the project in an easy and seamless manner.
To begin with, if you have a good ML project idea and a team that includes a data scientist, data engineer, developers, testers, you are good to start. In a lot of ways, developing an ML project is similar to a regular software project except that it has a few added steps.
https://twitter.com/lawrencehecht/status/1164470771026190341?lang=ga
Let us take a look at the 5 important steps required to implement a successful ML project.
1. Team Integration
Planning and assembling the right team is the first step. You need one or more machine learning engineers (ML engineers), data engineers, and DevOps engineers. The number of people required will be based on the complexity of the project. Data engineers are required for manipulating data from various sources, data scientists for the modeling part, and the DevOps team for the regular development and testing.
2. ETL step
This step is aimed more at the machine learning part than at the DevOps part. For the modeling, extract the data from all the sources and create a pipeline to ensure that the data extraction will be seamless even in the system.
Work through the data to identify any nulls, exceptions, or useless values. You need to identify the ideal replacement mechanism for it. It could be anything ranging from replacing them with the average, median, mode, etc. In some cases, you could also remove the entire row.
Create an automated system, wherein the data will flow from the various sources into your system with all the necessary transformations in a seamless manner.
3. Version Control
Version control is followed quite strictly with respect to DevOps. In the same manner, it is important to have strict version control in place for the ML model as well. You can use a Git repository for this as well.
So why is versioning important for ML modeling? Well, each time you run the model, you may be changing the various parameters. This in turn will give different results. If say in the future you wish to go back to the previous set of parameters, versioning will help. another important point is that versing can help you study the various changes done to the model and how it has evolved over the years/months. To help with the pipelining activity a lot of companies rely on end-to-end solutions such as KubeFlow or MLFlow.

Image Link: https://predera.com/end-to-end-ml-platform-are-we-there-yet-part-4/
4. Testing
Now, this step can get you thinking. A DevOps project has unit testing, integration testing, etc. In an ML project what exactly constitutes testing?
Well, in simple terms, the model validations are what is considered testing for an ML model. So the testing phase should ideally have 2 steps – one for model validation and the other for data validation.
Model validations include checking for the bad rates, accuracy, ROC, area under the curve, Population Stability Index (PSI), Characteristic Stability Index (CSI), and so on. The parameters for validation ned to be set based on the models being used and the use cases. The validation parameters will vary based on the models being used. For example, if you are using an unsupervised ML model like k-means clustering then accuracy, F-measure, precision, and recall are good validation parameters. On the other hand, if you are using logistic regression or linear regression models, then PSI, CSI, GINI are good validators.
So what does data validation do? ML models are oddly specific in a certain way. If the input changes, then the output will also vary. As long as the model is able to make sense of the input, it will give out sensible predictions. So the data validations are done to ensure that the input from the various sources does not change the format. They should be present in the format required for processing the ML model. This is also an important step in the lifecycle of MLOps.
5. Monitoring
So, once your project is properly integrated and has gone live, the work doesn’t end. In a regular DevOps project, once the project goes live, the work of the developer is completed unless there are further enhancements. In an MLOps project, it is important to periodically monitor the performance of the ML model. In any ML modeling, periodic monitoring ad validation is an integral component.
The periodicity of monitoring will depend on the model used. However, it has to be regularly validated against the live data using the same validation parameters used to ensure that the model is working as expected. If at any point you find that the validation parameters are not working properly, you will need to rework the modeling activity. This could either be a minor exercise where a small level of fine-tuning might suffice or a major activity where the model parameters need to be completely reworked.
You can even set up automated reporting to enable easier tracking of these parameters. A periodic reporting can help you notice even the minor deviations in the performance metrics which can be adjusted through a little bit of fine-tuning.
Final Thoughts
To conclude, although it is not a child’s play to implement an MLOps project neither is it a gargantuan task. The first-ever MLOps project might seem very complicated and time-consuming but the subsequent projects will become easier to implement and will definitely take less time. The first one is always where you get to learn the basics of implementing an MLOps project. So do not get bogged down and get going as the second, third, and subsequent projects will be a breeze to manage.

About the Author
Hi there! This is Aishwarya Murali, currently working in the analytics division of Karnataka Bank’s – Digital Centre of Excellence in Bangalore. Some of my interesting projects include ML-based scorecards for loan journey automation, customer segmentation, and improving the market share via selective profiling of customers using some machine learning analytics.
I have a master’s in computer applications and have done certification in Business Analytics from IIM-K. Currently, I am working on R&D innovations at my workplace.
You can connect with me at
https://www.linkedin.com/in/aishwarya-murali-b710a978/
You can also mail me at
The media shown in this article are not owned by Analytics Vidhya and are used at the Author’s discretion.
Hi there! This is Aishwarya Murali, currently working in the analytics division of HSBC in Bangalore. Some of my interesting projects include ML-based scorecards for loan journey automation, customer segmentation, and improving the market share via selective profiling of customers using some machine learning analytics.






