This article was published as a part of the Data Science Blogathon
Introduction
Data structures refer to the pattern of data arrangement on a disK that allows for convenient storage and display in the computing domain. They are related to the field of data science, which is expected to be a lucrative career choice in 2021. Large-scale deep learning models and next-generation smart devices, according to predictions for the next few years, will pave the way for this sector’s future.
Thus, learning data structures will be necessary for finding a suitable career amidst technological advancement.
We use Data structures to design the pathways for allocation, management, and retrieval of information. Data structures are especially important for drafting and improving the overall efficiency of processed data. They manage data by grouping and organising it to make information exchange more efficient.
Table of contents
Trees in Data Structures
ADTs (Abstract Data Types) which follow a hierarchical pattern for data allocation is known as ‘trees.’ A tree is essentially a collection of multiple nodes connected by edges. These ‘trees’ form a tree-like data structure, with the ‘root’ node leading to ‘parent’ nodes, which eventually lead to ‘children’ nodes. The connections which are formed by lines known as ‘edges.’
Endpoints that have no children nodes are referred to as ‘leaf’ nodes. Trees in data structures play an important role due to the non-linear nature of their structure. This allows for a faster response time during a search as well as greater convenience during the design process.
Types of Trees in Data Structure
1. General Tree
2. Binary Tree
3. Binary Search Tree
4. AVL Tree
5. Red Black Tree
6. Splay Tree
7. Treap
8. B-Tree
Let’s discuss each in detail below:
1. General Tree
A general tree is characterised by the lack of any configuration or limitations on the number of children a node can have. Any tree with a hierarchical structure can be described as a general tree. A node can have any number of children, and the tree’s orientation can be any combination of these. The degree of the nodes can range from 0 to n.
The data structure below is a classic example of a general tree, with ‘2′ at the top as the root node.
.svg.png)
2. Binary Tree
A binary tree is made up of nodes that can have two children, as described by the word “binary,” which means “two numbers.” In a binary tree, any node can have a maximum of 0, 1, or 2 nodes. Data structures’ binary trees are highly functional ADTs that can be further subdivided into a variety of types.
They are most commonly used in data structures for two reasons:
1) For obtaining nodes and categorising them, as observed in Binary Search Trees.
2) For representing data through a bifurcating structure.
A basic diagram of a binary tree is a data structure is shown below:
.png)
3. Binary Search Tree
A Binary Search Tree (BST) is a subtype of binary tree that is organised in such a way that it allows for faster searching, lookup, and addition/removal of data. The representation of nodes in a BST is defined by three fields: the data, its left child, and its right child.
BST is governed by the following factors:
· Every node on the left side (left child) must have a value less than the value of its parent node.
· Every node on the right side (right child) must have a higher value than its parent node.
An arrangement like this reduces the search times to half of a linear search, as found in an array. In comparison to other ADTs, binary search trees in data structures are widely applicable for searching and sorting.
.png)
Despite the fact that both BTs and BSTs are primarily trees in data structures, but don’t be confused by their names.
4. AVL Tree
The Adelson-Velsky-Landis (AVL) tree is named after its creators, Adelson-Velsky and Landis. The self-balancing characteristic of the AVL tree is unique. The heights of two subtrees from its root nodes are limited to two. The child nodes are rebalanced when the height difference exceeds one.
They (AVL trees) are height-balanced and are rebalanced through single or double rotations. The balancing factor is the difference in heights between the left and right subtrees, and its values are -1, 0, and 1.
.png)
5. Red Black Tree
This type is similar to the AVL trees because red-black trees are also height-balanced. What differentiates them is that they can be balanced in less than three rotations. They have an extra bit that defines whether a node is red or black, these colours are mainly used to make sure that the tree remains balanced during insertions and deletions. During changes, the red-black colour coding is also repainted but at almost no extra cost of memory.
.png)
6. Splay Tree
The splay tree, a subtype of the binary search tree, has the unique feature of performing rotational operations to adjust the most recent node. By performing a rotation, the most recently accessed node is arranged as the root node. Although it is a balanced tree, it is not of the height-balanced variety.
As tree rotations are performed in a specific manner, the act of ‘splaying’ occurs after the initial binary tree search. The tree is rotated to balance itself after each operation, and the searched element is arranged at the top as a root node.
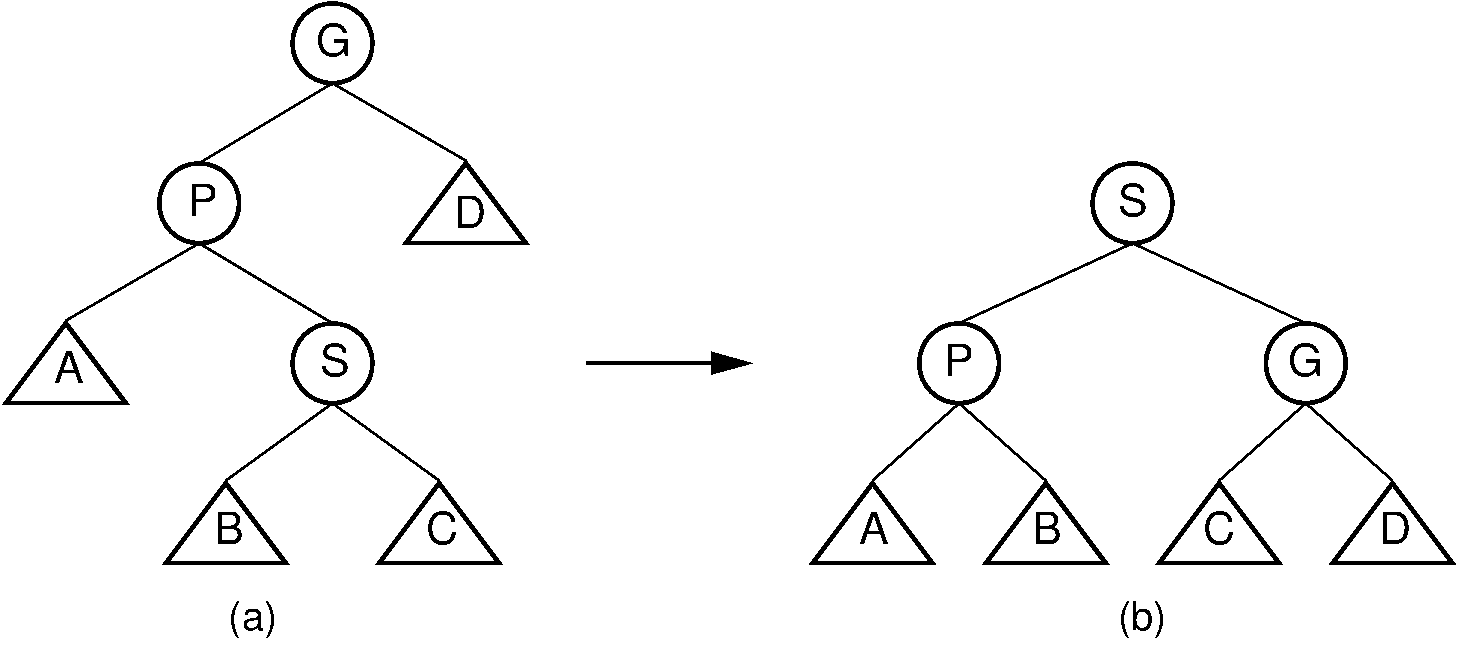
SPLAY TREE. SOURCE
7. Treap
Treaps are a combination of trees and heaps in data structures. In BSTs, the value of the left child must be less than the value of the root node, while the value of the right child must be greater. The root node in a heap data structure has the lowest value, and its child nodes (both left and right) have higher values.
As a result, a treap has a value in the form of a key (similar to BSTs) and a priority (like heaps). The nodes with the highest priority are inserted first into a binary search tree so that the priority numbers are independent random numbers. They keep a dynamic set of ordered keys and support binary searches within them.
.png)
8. B-Tree
B-Tree is a self-balancing type of tree in data structures that sorts data in logarithmic time to allow for search, sequential access, deletions, and insertions. A B-tree, unlike a binary tree, allows its nodes to have more than two children. They can read and write larger blocks of data in databases and file systems.
In data structures, a B-tree is used for larger storage systems, such as discs. All of the leaves contain no information and appear on the same level. A B-tree’s internal nodes can have a range of child nodes with varying sizes.
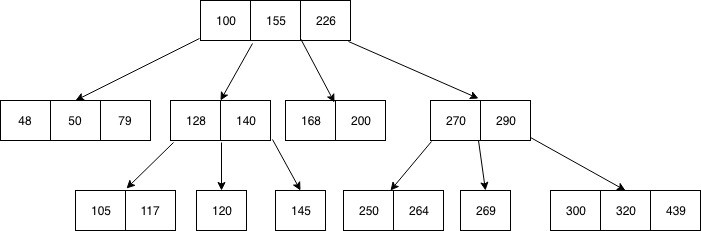
A SAMPLE B-TREE. SOURCE
Conclusion
These are the trees in data structures that programmers use to design the flow of data. Understanding their distinct characteristics and applications is important to your journey to becoming a data scientist. Another way to improve your skills is to work on projects that require knowledge of trees in data structures and other types of ADTs.
FAQs
Q1. What are the applications of tree?
1. Organize data efficiently
2. Represent complex relationships
3. File systems
4. Databases
5. Search engines
6. Artificial intelligence
7. Compilers
8. Networking
9. Graphics and UI design
Q2. What are the advantages of tree data structures?
Tree data structures are efficient for searching and retrieval, can grow and shrink dynamically, have a natural hierarchical organization, and are flexible.
About The Author
Prashant Sharma
Currently, I Am pursuing my Bachelors of Technology( B.Tech) from Vellore Institute of Technology. I am very enthusiastic about programming and its real applications including software development, machine learning and data science.
Hope you like the article. If you want to connect with me then you can connect on:
or for any other doubts, you can send a mail to me also
Hello, my name is Prashant, and I'm currently pursuing my Bachelor of Technology (B.Tech) degree. I'm in my 3rd year of study, specializing in machine learning, and attending VIT University.
In addition to my academic pursuits, I enjoy traveling, blogging, and sports. I'm also a member of the sports club. I'm constantly looking for opportunities to learn and grow both inside and outside the classroom, and I'm excited about the possibilities that my B.Tech degree can offer me in terms of future career prospects.
Thank you for taking the time to get to know me, and I look forward to engaging with you further!






