This article was published as a part of the Data Science Blogathon
What if you could simply talk or converse with a computer just the way you talk to a human?
Sounds impressive, doesn’t it?
Natural Language Processing helps us do just that!
Natural language processing (NLP) can be thought of as an intersection of Linguistics, Computer Science and Artificial Intelligence that helps computers understand, interpret and manipulate human language.
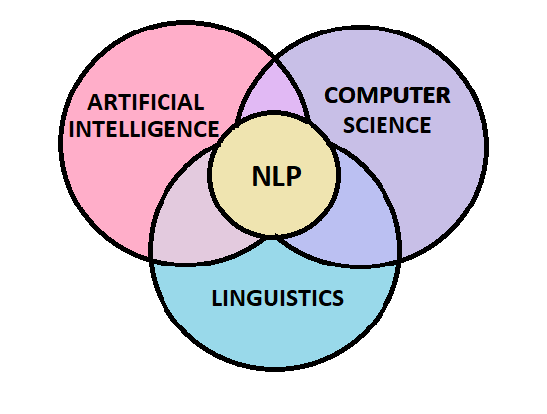
Here’s a fun fact! The root of Natural Language Processing dates back to the 1950s when Alan Turing first devised the Turing Test. The objective of the Turing Test was to determine whether a computer was truly intelligent based on its ability to interpret and generate natural language as a criterion of intelligence.
Ever since then, there has been an immense amount of study and development in the field of Natural Language Processing. Today NLP is one of the most in-demand and promising fields of Artificial Intelligence!
There are two main parts to Natural Language Processing:
- Data Preprocessing
- Algorithm Development
The idea of this article is to help you get started with NLP and provide you with the basic concepts and tools that are needed to work with text data. We shall be focusing mainly on the first and the most crucial part of Natural Language Processing – Text Preprocessing.
Text Preprocessing For NLP
Data Preprocessing is the most essential step for any Machine Learning model. How well the raw data has been cleaned and preprocessed plays a major role in the performance of the model. Likewise in the case of NLP, the very first step is Text Processing.
The various preprocessing steps that are involved are :
- Lower Casing
- Tokenization
- Punctuation Mark Removal
- Stop Word Removal
- Stemming
- Lemmatization
Let us explore them one at a time!
Text Pre-processing Using Lower Casing
It’s quite evident from the name itself, that we are trying to convert our text data into lower case. But why is this step needed?
When we have a text input, such as a paragraph we find words both in lower as well as upper case. However, the same words written in different cases are considered as different entities by the computer. For example: ‘Girl‘ and ‘girl‘ are considered as two separate words by the computer even though they mean the same.
In order to resolve this issue, we must convert all the words to lower case. This provides uniformity in the text.
sentence = "This text is used to demonstrate Text Preprocessing in NLP." sentence = sentence.lower() print(sentence)
Output: this text is used to demonstrate text preprocessing in nlp.
Understand Tokenization In Text Pre-processing
The next text preprocessing step is Tokenization. Tokenization is the process of breaking up the paragraph into smaller units such as sentences or words. Each unit is then considered as an individual token. The fundamental principle of Tokenization is to try to understand the meaning of the text by analyzing the smaller units or tokens that constitute the paragraph.
To do this, we shall use the NLTK library. NLTK is the Natural Language Toolkit library in python that is used for Text Preprocessing.
import nltk
nltk.download('punkt')
Output:

Sentence Tokenize
Now we shall take a paragraph as input and tokenize it into its constituting sentences. The result is a list stored in the variable ‘sentences’. It contains each sentence of the paragraph. The length of the list gives us the total number of sentences.
import nltk
# nltk.download('punkt')
sentence = "This text is used to demonstrate Text Preprocessing in NLP."
sentence = sentence.lower()
print(sentence)
paragraph="Linguistics is the scientific study of language. It encompasses the analysis of every aspect of language, as well as the methods for studying and modeling them. The traditional areas of linguistic analysis include phonetics, phonology, morphology, syntax, semantics, and pragmatics."
# Tokenize Sentences
sentences = nltk.sent_tokenize(paragraph.lower())
print("-------------------------------------")
print(sentences)
print("-------------------------------------")
print(len(sentences))
Word Tokenize
Similarly, we can also tokenize the paragraph into words. The result is a list called ‘words’, containing each word of the paragraph. The length of the list gives us the total number of words present in our paragraph.
# Tokenize Words words = nltk.word_tokenize(paragraph.lower()) print (words) print (len(words))

Note: Here we observe that the punctuations have also been considered as separate words.
Punctuation Mark Removal
This brings us to the next step. We must now remove the punctuation marks from our list of words. Let us first display our original list of words.
print (words)

Now, we can remove all the punctuation marks from our list of words by excluding any alphanumeric element. This can be easily done in this manner.
new_words= [word for word in words if word.isalnum()]
Stop Word Removal
Have you ever observed that certain words pop up very frequently in any language irrespective of what you are writing?
These words are our stop words!
Stop words are a collection of words that occur frequently in any language but do not add much meaning to the sentences. These are common words that are part of the grammar of any language. Every language has its own set of stop words. For example some of the English stop words are “the”, “he”, “him”, “his”, “her”, “herself” etc.
To do this, we will have to import stopwords from nltk.corpus
from nltk.corpus import stopwords
nltk.download('stopwords')
Output:

Once this is done, we can now display the stop words of any language by simply using the following command and passing the language name as a parameter.
print(stopwords.words("english"))

These are all the English stop words.
You can also get the stop words of other languages by simply changing the parameter. Have some fun and try passing “Spanish” or “French” as the parameter!
Since these stop words do not add much value to the overall meaning of the sentence, we can easily remove these words from our text data. This helps in dimensionality reduction by eliminating unnecessary information.
WordSet = []
for word in new_words:
if word not in set(stopwords.words("english")):
WordSet.append(word)
print(WordSet)

print(len(WordSet))
Output: 24
We observe that all the stop words have been successfully removed from our set of words. On printing the length of our new word list we see that the length is now 24 which is much less than our original word list length which was 49. This shows how we can effectively reduce the dimensionality of our text dataset by removal of stop words without losing any vital information. This becomes extremely useful in the case of large text datasets.
Stemming
Now, what do you mean by stemming?
As the name suggests, Stemming is the process of reduction of a word into its root or stem word. The word affixes are removed leaving behind only the root form or lemma.
For example: The words “connecting”, “connect”, “connection”, “connects” are all reduced to the root form “connect”. The words “studying”, “studies”, “study” are all reduced to “studi”.
Let us see, how this can be done.
To do this we must first import PorterStemmer from nltk.stem and create an object of the PorterStemmer class.
from nltk.stem import PorterStemmer ps = PorterStemmer()
After that using the PorterStemmer object ‘ps’ we shall call the stem method to perform stemming on our wordlist.
WordSetStem = [] for word in WordSet: WordSetStem.append(ps.stem(word)) print(WordSetStem)
Output: [‘linguist’, ‘scientif’, ‘studi’, ‘languag’, ‘encompass’, ‘analysi’, ‘everi’, ‘aspect’, ‘languag’, ‘well’, ‘method’, ‘studi’, ‘model’, ‘tradit’, ‘area’, ‘linguist’, ‘analysi’, ‘includ’, ‘phonet’, ‘phonolog’, ‘morpholog’, ‘syntax’, ‘semant’, ‘pragmat’]
Carefully observe the result that we have obtained. All the words in our list have been reduced to their stem words or lemma. For example, “linguistics” has been reduced to “linguist”, the word “scientific” has been reduced to “scientif” and so on.
Note: The word list obtained after performing stemming does not always contain words that are a part of the English vocabulary. In our example, words such as “scientif“, “studi“, “everi” are not proper words, i.e. they do not make sense to us.
Lemmatization
We have just seen, how we can reduce the words to their root words using Stemming.
However, Stemming does not always result in words that are part of the language vocabulary. It often results in words that have no meaning to the users. In order to overcome this drawback, we shall use the concept of Lemmatization.
Let’s dive into the code.
from nltk.stem import WordNetLemmatizer
lm= WordNetLemmatizer()
nltk.download('wordnet')
Output:

WordSetLem = [] for word in WordSet: WordSetLem.append(lm.lemmatize(word)) print(WordSetLem)

We see that the words in our list have been lemmatized. Each word has been converted into a meaningful parent word.
Another key difference between stemming and lemmatization is that in the case of lemmatization we can pass a POS parameter. This is used to provide the context in which we wish to lemmatize our words by mentioning the Parts Of Speech(POS). If nothing is mentioned, the default is ‘noun’.
Let’s see this in action!
When we do not pass any parameter, or specify pos as “n” (Noun). We get the following output:
test = [] for word in ["changing", "dancing","is", "was"]: test.append(lm.lemmatize(word, pos="n")) print(test)
Output: [‘changing’, ‘dancing’, ‘is’, ‘wa’]
Here we see that “changing” and “dancing” remain unchanged after lemmatization. This is because these have been considered as nouns. Now let us change the part of speech to verb by specifying pos to “v”.
test = []
for word in [“changing”, “dancing”,”is”, “was”]:
test.append(lm.lemmatize(word, pos=”v”))
print(test)
Output: [‘change’, ‘dance’, ‘be’, ‘be’]
Now the words have been changed to their proper root words. The words such as “is” and “was” have also been converted to “be“. Thus we observe that we can accurately specify the context of lemmatization by passing in the desired parts of speech in the parameter of the lemmatize method.
Conclusion
With this, we come to the end of our blog!
We have gone through the fundamental preprocessing steps that must be performed while working on text data. This can be considered as the very first step for anyone who is getting started with NLP. After these fundamental pre-processing steps have been performed models such as Bag Of Words, TF-IDF, Word2Vec can be used to further process the data.
You now know how to get started with pre-processing Text data and hopefully, you found this interesting! Now that you are familiar with the basics, I strongly encourage you to explore this domain further!
Happy Learning!
About Me:
Hey there, I’m Tithi Sreemany. Hope you liked reading this article and found it useful!
You can reach out to me on LinkedIn.
Do check out my other articles here: link.
Thanks for reading!




