Introduction
In computer science, problem-solving refers to artificial intelligence techniques, including forming green algorithms, heuristics, and acting root reason analysis to locate solutions. Search algorithms are fundamental tools for fixing a big range of issues in computer science. They provide a systematic technique to locating answers by way of exploring a hard and fast of feasible alternatives. These algorithms are used in various applications with path locating, scheduling, and information retrieval. In this article, we will look into the problem-solving techniques used by various search algorithms.
Overview:
- Learn about the role of problem-solving by searching in AI and its importance in addressing complex computational challenges.
- Gain an understanding of the properties of search algorithms and how they guide the search process toward optimal solutions.
- Discover various problem-solving techniques employed by search algorithms, including both uninformed and informed approaches.
- Explore the types of search algorithms, focusing on their use cases and applications in fields like pathfinding, scheduling, and data retrieval.
- Compare different uninformed search algorithms and how they contrast with informed search algorithms based on their effectiveness.
- Examine the advantages and limitations of uninformed and informed search algorithms, highlighting their differences in approach and efficiency.
- Understand the key takeaways for selecting the appropriate algorithm for specific AI problem-solving scenarios.
This article was published as a part of the Data Science Blogathon.
Table of contents
- Introduction
- Examples of Problems in Artificial Intelligence
- Problem-Solving Techniques
- Properties of Search Algorithms
- Types of Search Algorithms
- Uninformed Search Algorithms
- Comparison of various Uninformed Search Algorithms
- Informed Search Algorithms
- Comparison of Uninformed and Informed Search Algorithms
- Conclusion
Examples of Problems in Artificial Intelligence
In today’s fast-paced digitized world, artificial intelligence techniques are used widely to automate systems that can use resources and time efficiently. Some of the well-known problems experienced in everyday life are games and puzzles. Using AI techniques, we can solve these problems efficiently. In this sense, some of the most common problems resolved by AI are:
- Travelling Salesman Problem
- Tower of Hanoi Problem
- Water-Jug Problem
- N-Queen Problem
- Chess
- Sudoku
- Crypt-arithmetic Problems
- Magic Squares
- Logical Puzzles and so on.
Problem-Solving Techniques
In artificial intelligence, problems can be solved by using searching algorithms, evolutionary computations, knowledge representations, etc. I will discuss the various searching techniques used to solve problems. In general, searching is referred to as finding the information one needs.
The process of problem-solving using searching consists of the following steps.
- Define the problem
- Analyze the problem
- Identification of possible solutions
- Choosing the optimal solution
- Implementation
Let’s discuss some of the essential properties of search algorithms.
Properties of Search Algorithms
Let us now look at the properties of search algorithms in AI.
Completeness
A search algorithm is considered complete when it gives a solution or returns any solution for a given random input.
Optimality
If a solution found is the best (lowest path cost) among all the solutions identified, then that solution is said to be optimal.
Time complexity
The time taken by an algorithm to complete its task is called time complexity. If the algorithm completes a task in a shorter amount of time, then it is efficient.
Space complexity
It is the maximum storage or memory the algorithm takes while searching.
These properties are also used to compare the efficiency of the different types of searching algorithms.
Types of Search Algorithms
Now, let’s look at the types of search algorithms.
Based on the search problems, we can classify the search algorithm as
- Uninformed search
- Informed search
Uninformed Search Algorithms
The uninformed search algorithm does not have any domain knowledge, such as closeness, location of the goal state, etc. It behaves in a brute-force way. It only knows how to traverse the given tree and find the goal state. This algorithm is also known as the Blind search algorithm or brute-force algorithm. There are six types of uninformed search strategies.
They are:
- Breadth-first search
- Depth-first search
- Depth-limited search
- Iterative deepening depth-first search
- Bidirectional search
- Uniform cost search
Let’s discuss these six strategies one by one.
1. Breadth-first search
It is one of the most common search strategies. A breadth-first search generally starts from the root node, examines the neighbor nodes, and then moves to the next level. It uses the First-in, First-out (FIFO) strategy as it gives the shortest path to achieving the solution.
BFS is used where the given problem is very small and space complexity is not considered.
Now, consider the following tree.
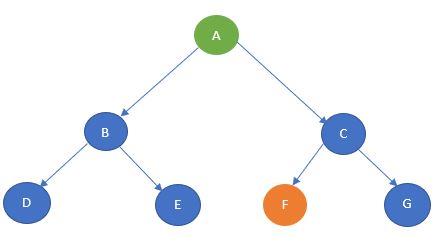
Source: Author
Let’s take node A as the start state and node F as the goal state.
The BFS algorithm starts with the start state, moves to the next level, and visits each node until it reaches the goal state.
In this example, it starts from A and then travels to the next level and visits B and C and then
Travel to the next level and visit D, E, F, and G. Here, the goal state is defined as F, so the traversal will stop at F.
The path of traversal is:
A —-> B —-> C —-> D —-> E —-> F
Let’s implement the same in Python programming.
Python Code:
graph = {
'A' : ['B','C'],
'B' : ['D', 'E'],
'C' : ['F', 'G'],
'D' : [],
'E' : [],
'F' : [],
'G' : []
}
visited = []
queue = []
goal = 'F'
def bfs(visited, graph, node):
visited.append(node)
queue.append(node)
while queue:
s = queue.pop(0)
print (s, end = "\n")
for neighbour in graph[s]:
if neighbour not in visited:
visited.append(neighbour)
queue.append(neighbour)
if goal in visited:
break
bfs(visited, graph, 'A')Advantages of BFS
- BFS will never be trapped in any unwanted nodes.
- If the graph has more than one solution, then BFS will return the optimal solution with the shortest path.
Disadvantages of BFS
- BFS stores all the nodes in the current level and then moves them to the next level. This requires a lot of memory.
- BFS takes more time
to reach the goal state, which is far away.
2. Depth-first search
The depth-first search uses Last-in, First-out (LIFO) strategy and hence it can be implemented by using stack. DFS uses backtracking. It starts from the initial state and explores each path to its greatest depth before it moves to the next path.
DFS will follow
Root node —-> Left node —-> Right node
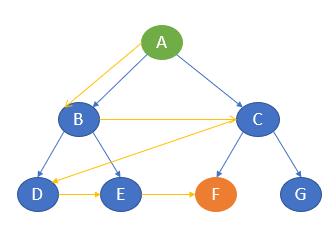
Now, consider the same example tree mentioned above.
Here, it starts from the start state A, then travels to B, then goes to D. After reaching D, it backtracks to B. B is already visited, so it goes to the next depth, E, and then backtracks to B. As it is already visited, it goes back to A. A is already visited, so it goes to C and then to F. F is our goal state, and it stops there.
The path of traversal is:
A —-> B —-> D —-> E —-> C —-> F
Let’s try to code it.
graph = {
'A' : ['B','C'],
'B' : ['D', 'E'],
'C' : ['F', 'G'],
'D' : [],
'E' : [],
'F' : [],
'G' : []
}
goal = 'F'
visited = set()
def dfs(visited, graph, node):
if node not in visited:
print (node)
visited.add(node)
for neighbour in graph[node]:
if goal in visited:
break
else:
dfs(visited, graph, neighbour)
dfs(visited, graph, 'A')The output path is as follows.

Advantages of DFS
- It takes lesser memory as compared to BFS.
- The time complexity is lesser when compared to BFS.
- DFS does not require much more search.
Disadvantages of DFS
- DFS does not always guarantee to give a solution.
- As DFS goes deep down, it may get trapped in an infinite loop.
3. Depth-limited search
Depth-limited search works similarly to depth-first search. The difference is that depth-limited search has a pre-defined limit up to which it can traverse the nodes. Depth-limited search solves one of DFS’s drawbacks, as it does not go to an infinite path.
DLS ends its traversal if any of the following conditions exits.
Standard Failure
It denotes that the given problem does not have any solutions.
Cut off Failure Value
It indicates no solution for the problem within the given limit.
Now, consider the same example.
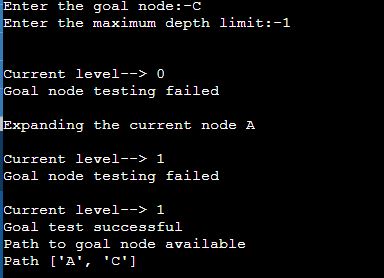
Let’s take A as the start node and C as the goal state and limit as 1.
The traversal starts with node A and then goes to the next level, 1. The goal state C is there, and it stops the traversal.
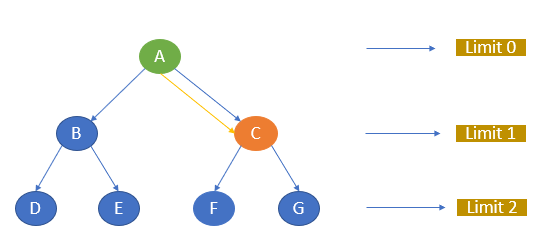
The path of traversal is:
A —-> C
If we give C as the goal node and the limit as 0, the algorithm will not return any path as the goal node is unavailable within the given limit.
If we give the goal node as F and the limit as 2, the path will be A, C, F.
Let’s implement DLS.
graph = {
'A' : ['B','C'],
'B' : ['D', 'E'],
'C' : ['F', 'G'],
'D' : [],
'E' : [],
'F' : [],
'G' : []
}
def DLS(start,goal,path,level,maxD):
print('nCurrent level-->',level)
path.append(start)
if start == goal:
print("Goal test successful")
return path
print('Goal node testing failed')
if level==maxD:
return False
print('nExpanding the current node',start)
for child in graph[start]:
if DLS(child,goal,path,level+1,maxD):
return path
path.pop()
return False
start = 'A'
goal = input('Enter the goal node:-')
maxD = int(input("Enter the maximum depth limit:-"))
print()
path = list()
res = DLS(start,goal,path,0,maxD)
if(res):
print("Path to goal node available")
print("Path",path)
else:
print("No path available for the goal node in given depth limit")When we give C as the goal node and 1 as the limit, the path will be as follows.
Advantages of DLS
- It takes lesser memory when compared to other search techniques.
Disadvantages of DLS
- DLS may not offer an optimal solution if the problem has multiple solutions.
- DLS also encounters incompleteness.
4. Iterative deepening depth-first search
Iterative deepening depth-first search is a combination of depth-first search and breadth-first search. IDDFS find the best depth limit by gradually adding the limit until the defined goal state is reached.
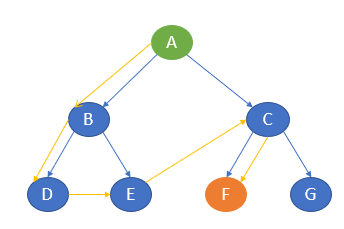
Let me try to explain this using the same example tree.
Consider A as the start node and E as the goal node. Let the maximum depth be 2.
The algorithm starts with A, moves to the next level, and searches for E. If it does not find E, it moves to the next level and finds it again.
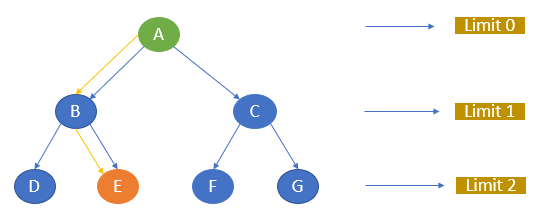
The path of traversal is
A —-> B —-> E
Let’s try to implement this.
graph = {
'A' : ['B','C'],
'B' : ['D', 'E'],
'C' : ['F', 'G'],
'D' : [],
'E' : [],
'F' : [],
'G' : []
}
path = list()
def DFS(currentNode,destination,graph,maxDepth,curList):
curList.append(currentNode)
if currentNode==destination:
return True
if maxDepth<=0:
path.append(curList)
return False
for node in graph[currentNode]:
if DFS(node,destination,graph,maxDepth-1,curList):
return True
else:
curList.pop()
return False
def iterativeDDFS(currentNode,destination,graph,maxDepth):
for i in range(maxDepth):
curList = list()
if DFS(currentNode,destination,graph,i,curList):
return True
return False
if not iterativeDDFS('A','E',graph,3):
print("Path is not available")
else:
print("Path exists")
print(path.pop())The path generated is
as follows.

Advantages of IDDFS
- IDDFS has the advantages of both BFS and DFS.
- It offers fast search and uses memory efficiently.
Disadvantages of IDDFS
- It does all the work of the previous stage again and again.
5. Bidirectional search
The bidirectional search algorithm is completely different from all other search strategies. It executes two simultaneous searches called forward and backward searches and reaches the goal state. Here, the graph is divided into two smaller sub-graphs. In one graph, the search is started from the initial start state, and in the other graph, it is started from the goal state. When these two nodes intersect, the search will be terminated.
Bidirectional search requires the well-definition of both the start and goal start and the same branching factor in both directions.
Consider the graph below.
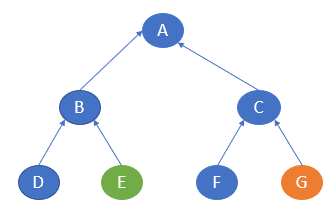
Here, the start state is E, and the goal state is G. In one sub-graph, the search starts from E, and in the other, it starts from G. E will go to B and then A, and G will go to C and then A. Here, both traversals meet at A, and hence, the traversal ends.
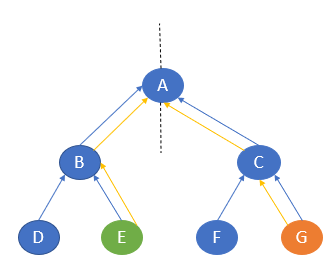
The path of traversal is
E —-> B —-> A —-> C —-> G
Let’s implement the same in Python.
from collections import deque
class Node:
def __init__(self, val, neighbors=[]):
self.val = val
self.neighbors = neighbors
self.visited_right = False
self.visited_left = False
self.parent_right = None
self.parent_left = None
def bidirectional_search(s, t):
def extract_path(node):
node_copy = node
path = []
while node:
path.append(node.val)
node = node.parent_right
path.reverse()
del path[-1]
while node_copy:
path.append(node_copy.val)
node_copy = node_copy.parent_left
return path
q = deque([])
q.append(s)
q.append(t)
s.visited_right = True
t.visited_left = True
while len(q) > 0:
n = q.pop()
if n.visited_left and n.visited_right:
return extract_path(n)
for node in n.neighbors:
if n.visited_left == True and not node.visited_left:
node.parent_left = n
node.visited_left = True
q.append(node)
if n.visited_right == True and not node.visited_right:
node.parent_right = n
node.visited_right = True
q.append(node)
return False
n0 = Node('A')
n1 = Node('B')
n2 = Node('C')
n3 = Node('D')
n4 = Node('E')
n5 = Node('F')
n6 = Node('G')
n0.neighbors = []
n1.neighbors = [n0]
n2.neighbors = [n0]
n3.neighbors = [n1]
n4.neighbors = [n1]
n5.neighbors = [n2]
n6.neighbors = [n2]
print(bidirectional_search(n4, n6))The path is generated as follows.

Advantages of bidirectional search
- This algorithm searches the graph fast.
- It requires less memory to complete its action.
Disadvantages of bidirectional search
- The goal state should be pre-defined.
- The graph is quite
difficult to implement.
6. Uniform cost search
Uniform cost search is considered the best search algorithm for a weighted graph or graph with costs. It searches the graph by giving maximum priority to the lowest cumulative cost. Uniform cost search can be implemented using a priority queue.
Consider the below graph where each node has a pre-defined cost.
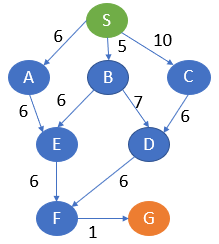
Here, S is the start node and G is the goal node.
From S, G can be reached in the following ways.
- S, A, E, F, G -> 19
- S, B, E, F, G -> 18
- S, B, D, F, G -> 19
- S, C, D, F, G -> 23
Here, the path with the least cost is S, B, E, F, G.
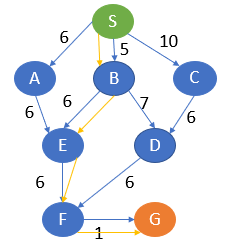
Let’s implement UCS in Python.
graph=[['S','A',6],
['S','B',5],
['S','C',10],
['A','E',6],
['B','E',6],
['B','D',7],
['C','D',6],
['E','F',6],
['D','F',6],
['F','G',1]]
temp = []
temp1 = []
for i in graph:
temp.append(i[0])
temp1.append(i[1])
nodes = set(temp).union(set(temp1))
def UCS(graph, costs, open, closed, cur_node):
if cur_node in open:
open.remove(cur_node)
closed.add(cur_node)
for i in graph:
if(i[0] == cur_node and costs[i[0]]+i[2] < costs[i[1]]):
open.add(i[1])
costs[i[1]] = costs[i[0]]+i[2]
path[i[1]] = path[i[0]] + ' -> ' + i[1]
costs[cur_node] = 999999
small = min(costs, key=costs.get)
if small not in closed:
UCS(graph, costs, open,closed, small)
costs = dict()
temp_cost = dict()
path = dict()
for i in nodes:
costs[i] = 999999
path[i] = ' '
open = set()
closed = set()
start_node = input("Enter the Start State: ")
open.add(start_node)
path[start_node] = start_node
costs[start_node] = 0
UCS(graph, costs, open, closed, start_node)
goal_node = input("Enter the Goal State: ")
print("Path with least cost is: ",path[goal_node])The optimal output path is generated.

Advantages of UCS
- This algorithm is optimal as the selection of paths is based on the lowest cost.
Disadvantages of UCS
- The algorithm does
not consider how many steps it takes to reach the lowest path. This may result in an infinite loop also.
Comparison of various Uninformed Search Algorithms
Now, let me compare the six uninformed search strategies based on the complexity of the time.
| Algorithm | Time | Space | Complete | Optimality |
| Breadth First | O(b^d) | O(b^d) | Yes | Yes |
| Depth First | O(b^m) | O(bm) | No | No |
| Depth Limited | O(b^l) | O(bl) | No | No |
| Iterative Deepening | O(b^d) | O(bd) | Yes | Yes |
| Bidirectional | O(b^(d/2)) | O(b^(d/2)) | Yes | Yes |
| Uniform Cost | O(bl+floor(C*/epsilon)) | O(bl+floor9C*/epsilon)) | Yes | Yes |
This is all about uninformed search algorithms.
Let’s take a look at informed search algorithms.
Informed Search Algorithms
The informed search algorithm is also called heuristic search or directed search. In contrast to uninformed search algorithms, informed search algorithms require details such as distance to reach the goal, steps to reach the goal, and cost of the paths, which makes this algorithm more efficient.
Here, the goal state can be achieved by using the heuristic function.
The heuristic function achieves the goal state with the lowest cost possible. This function estimates how close a state is to the goal.
Let’s discuss some of the informed search strategies.
1. Greedy best-first search algorithm
Greedy best-first search uses the properties of both depth-first search and breadth-first search. It traverses the node by selecting the path that appears best at the moment. The closest path is selected using the heuristic function.
Consider the below graph with the heuristic values.
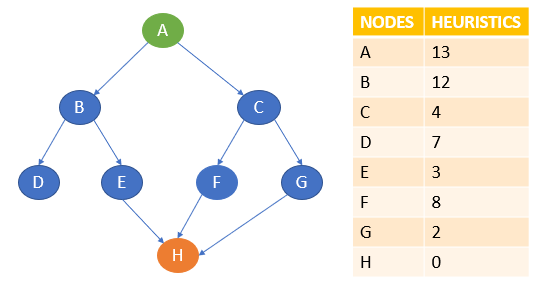
Here, A is the start node, and H is the goal node.
Greedy best-first search starts with A and then examines the next neighbours, B and C. Here, the heuristics of B are 12 and C are 4. The best path at the moment is C, so it goes to C. From C, it explores the neighbours F and G. The heuristics of F are 8 and G are 2, so it goes to G. From G, it goes to H, whose heuristic is 0, which is also our goal state.
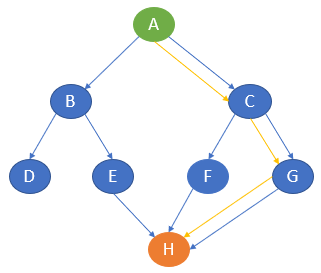
The path of traversal is
A —-> C —-> G —-> H
Let’s try this with Python.
graph = {
'A':[('B',12), ('C',4)],
'B':[('D',7), ('E',3)],
'C':[('F',8), ('G',2)],
'D':[],
'E':[('H',0)],
'F':[('H',0)],
'G':[('H',0)]
}
def bfs(start, target, graph, queue=[], visited=[]):
if start not in visited:
print(start)
visited.append(start)
queue=queue+[x for x in graph[start] if x[0][0] not in visited]
queue.sort(key=lambda x:x[1])
if queue[0][0]==target:
print(queue[0][0])
else:
processing=queue[0]
queue.remove(processing)
bfs(processing[0], target, graph, queue, visited)
bfs('A', 'H', graph)The output path with the lowest cost is generated.

The time complexity of Greedy best-first search is O(bm) in worst cases.
Advantages of Greedy best-first search
- Greedy best-first search is more efficient compared with breadth-first search and depth-first search.
Disadvantages of Greedy best-first search
- In the worst-case scenario, the greedy best-first search algorithm may behave like an unguided DFS.
- There are some possibilities for greedy best-first to get trapped in an infinite loop.
- The algorithm is not
an optimal one.
Next, let’s discuss the other informed search algorithm called the A* search algorithm.
2. A* search Algorithm
A* search algorithm is a combination of uniform cost search and greedy best-first search algorithms. It combines the advantages of both with better memory usage. It uses a heuristic function to find the shortest path. A* search algorithm uses the sum of the node’s cost and heuristic to find the best path.
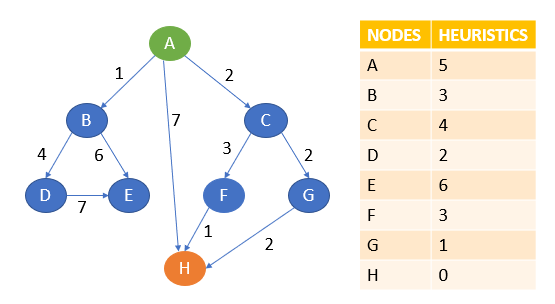
Let A be the start node, and H be the goal node.
The algorithm will start with A. From A, it can move to B, C, or H.
Note that an A* search uses the sum of path cost and heuristics value to determine the path.
Here, from A to B, the sum of cost and heuristics is 1 + 3 = 4.
From A to C, it is 2 + 4 = 6.
From A to H, it is 7 + 0 = 7.
Here, the lowest cost is 4, and the path A to B is chosen. The other paths will be on hold.
Now, from B, it can go to D or E.
The cost is 1 + 4 + 2 = 7 from A to B to D.
From A to B to E, 1 + 6 + 6 = 13.
The lowest cost is 7. Path A to B to D is chosen and compared with other on-hold paths.
Here, paths A to C are of less cost. That is 6.
Hence, A to C is chosen, and other paths are kept on hold.
From C, it can now go to F or G.
From A to C to F, the cost is 2 + 3 + 3 = 8.
The cost is 2 + 2 + 1 = 5 from A to C to G.
The lowest cost is 5, which is also less than other paths on hold. Hence, paths A to G are chosen.
From G, it can go to H, whose cost is 2 + 2 + 2 + 0 = 6.
Here, 6 is less than the cost of other paths, which is on hold.
Also, H is our goal state. The algorithm will terminate here.
Python
Let’s try this in Python.
graph=[['A','B',1,3],
['A','C',2,4],
['A','H',7,0],
['B','D',4,2],
['B','E',6,6],
['C','F',3,3],
['C','G',2,1],
['D','E',7,6],
['D','H',5,0],
['F','H',1,0],
['G','H',2, 0]]
temp = []
temp1 = []
for i in graph:
temp.append(i[0])
temp1.append(i[1])
nodes = set(temp).union(set(temp1))
def A_star(graph, costs, open, closed, cur_node):
if cur_node in open:
open.remove(cur_node)
closed.add(cur_node)
for i in graph:
if(i[0] == cur_node and costs[i[0]]+i[2]+i[3] < costs[i[1]]):
open.add(i[1])
costs[i[1]] = costs[i[0]]+i[2]+i[3]
path[i[1]] = path[i[0]] + ' -> ' + i[1]
costs[cur_node] = 999999
small = min(costs, key=costs.get)
if small not in closed:
A_star(graph, costs, open,closed, small)
costs = dict()
temp_cost = dict()
path = dict()
for i in nodes:
costs[i] = 999999
path[i] = ' '
open = set()
closed = set()
start_node = input("Enter the Start Node: ")
open.add(start_node)
path[start_node] = start_node
costs[start_node] = 0
A_star(graph, costs, open, closed, start_node)
goal_node = input("Enter the Goal Node: ")
print("Path with least cost is: ",path[goal_node])The output is given
as

The time complexity of the A* search is O(b^d), where b is the branching factor.
Advantages of A* search algorithm
- This algorithm is best when compared with other algorithms.
- This algorithm can be used to solve very complex problems, and it is an optimal one.
Disadvantages of A* search algorithm
- The A* search is based on heuristics and cost. It may not produce the shortest path.
- Memory usage is more as it keeps all the nodes in the memory.
Now, let’s compare uninformed and informed search strategies.
Comparison of Uninformed and Informed Search Algorithms
Uninformed search is also known as blind search, whereas informed search is also called heuristics search. Uniformed search does not require much information, whereas informed search requires domain-specific details. Compared to uninformed search, informed search strategies are more efficient, and the time complexity of uninformed search strategies is greater. Informed search handles the problem better than blind search.
Conclusion
Search algorithms are used in games, stored databases, virtual search spaces, quantum computers, etc. In this article, we have discussed some of the important search strategies and how to use them to solve AI problems; this is not the end. Several algorithms can solve any problem. Nowadays, AI is growing rapidly and applies to many real-life problems. Keep learning! Keep practising!
The media shown in this article are not owned by Analytics Vidhya and are used at the Author’s discretion.






