This article was published as a part of the Data Science Blogathon
Introduction
Ensemble modeling is the process by which a machine learning model combines distinct base models to generate generalized predictions using a combination of the predictive power of each of its components. Each base model differs with respect to the variable elements i.e. training data used and algorithm/model architecture. Each of these may capture only a few aspects or learn effectively from only a part of the training data, due to its specific tuning. Ensemble modeling provides us with the opportunity to combine all such models to acquire a single superior model which is based on learnings from most or all parts of the training dataset. Averaging of predictions also help eradicate the issue of individual models fixating on local minima. An interesting feature of ensemble modeling is that there is no limit on the number of base models that can be used. It may range from anything from as low as 2, to as high as 10 base models or ‘ensemble members’.
While ensemble modeling is fundamentally performed to improve the computational power of models used for classification or prediction problems, as can be seen from multiple Kaggle contests where the winner has simply combined several base models to produce a single generalizable model with greater accuracy; they can be used for a variety of other functions.
Advantages of Ensemble Modeling for Neural Networks
Its advantages can be classified under two broad categories:
1) Enhancement of Performance – By combining the prediction power of its ‘ensemble members’ an ensemble model is able to produce results with greater generalizability and even greater accuracy in most cases.
While dealing with any machine learning problem, the main aim is to build a model which produces low generalization error and high accuracy. By using suitable aggregation combinations of base models or ‘weak learners’, an ensemble model is able to create a model that is able to learn better from the training data, and thus produce better results.
2) Enhancement of Reliability – Single, base models often suffer from problems related to variance, bias and noise. By reducing bias and variance and giving weightage to a higher number of features, the ensemble model generally enhances reliability and robustness. Robustness represents low variance which indicates a model unaffected by small inconsistencies in training data. Even if the accuracy of the model is not improved, the ensemble achieves a reduction in the variance or spread of prediction.
Depicted below, is a representation of the bias-variance tradeoff, which is a very important parameter for any supervised machine learning model. The bias-variance tradeoff of a model can be understood by considering them to be complements of each other. Variance estimates the impact of new training data on the model, whereas bias represents the prejudice or ‘bias’ in results of a model which makes incorrect assumptions about the data. An increase in one leads to the decrease of the other, and vice versa. A good bias-variance tradeoff value improves the predictive accuracy of the model while dealing with unseen data.
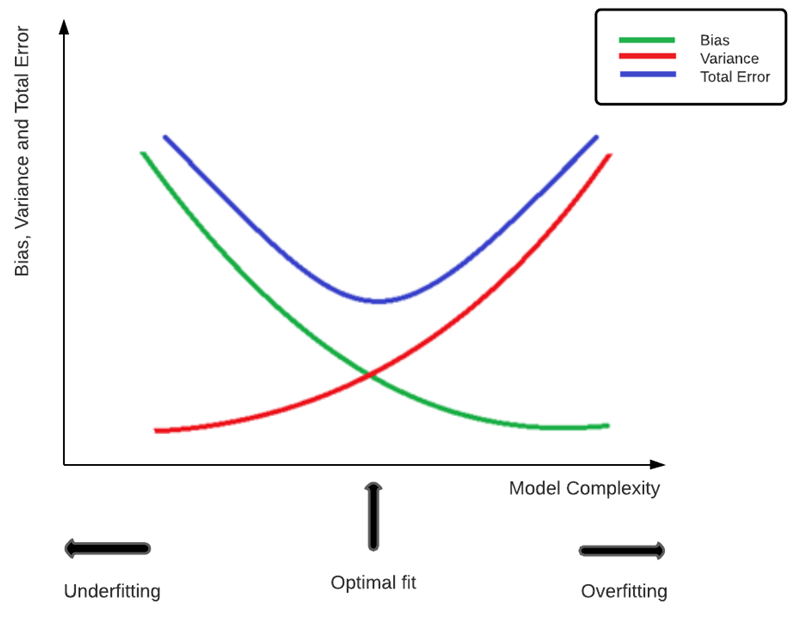
As seen above, overfitting of training data occurs to a model with high variance, while underfitting occurs when a model has a high bias.
This takes effect because a model with high variance tends to be too complex, thus leading to an increase in sensitivity, which ultimately results in the model being adversely affected by noise and thus overfitting the data. In such a case, the model will be able to perform extremely well on the training data but fails to produce accurate results when it encounters unseen data.
An underfit model on the other hand performs poorly on both trainings as well as unseen or test data. Such models are overly simplified and unable to capture the patterns in the dataset due to high bias and low variance. An optimal fit model is the ultimate aim of any data scientist and this is achieved at the ideal values of both bias and variance.
Thus, an ensemble model leads to a significant improvement in the performance of the overall model. Additionally, it offers greater flexibility in the building of models, by allowing various different combinations of constituent models as well as techniques.
While it is important to understand how to apply ensemble modeling, it is equally important to understand when and where we should use it.
Is Ensemble Modeling always the best choice?
The straightforward answer to this question is no. When it comes to ensemble modeling, while the pros seem to outweigh the cons, it is always a good idea to properly analyze the problem and its requirements before opting for an ensemble model.
Let us consider a simple predictive problem consisting of a small dataset with few features. Ensemble modeling involves combining several models, which automatically translates to higher training and computational time. In such a scenario, choosing a single model for e.g. simple linear regression, may in fact lead to better results and a more accurate model.
Ensemble methods are usually performed when there is a need to optimize model performance, and in situations where we have already obtained a highly accurate model, there is little to no need for an ensemble model. It is also quite possible that an ensemble model may not increase the overall accuracy. This is possible if only one of the members is performing well and the others are either not contributing at all or even leading to a reduction in the average prediction accuracy. Ensemble modeling also leads to a significant reduction in the explainability of the model.
Hence, to better summarize why ensemble modeling is not always the best choice, let us take a look at the pros and cons of any ensemble model.
Pros
1) Greater generalizability and better overall performance.
2) Reduction in variance, bias, and noise.
3) Better learning from large datasets and improved feature selection.
Cons
1) Increased complexity as there is a need to construct and combine more than one base model.
2) Loss in explainability of the model.
Thus, it is essential to know when and where it should be applied, so as to avoid redundancy in modeling. Also, in a manner similar to how we experiment with various models before choosing the best-fit one, it is important to choose the correct ensemble technique and tune its various parameters to suit the problem requirements.
In this article, the usage of ensemble modeling to overcome the limitations posed by a large dataset is described.
Motivation behind Ensemble Modeling for Neural Networks with Large Datasets
Most IDEs like Jupyter Notebook have limited default memory sizes, which can be expanded, however, other memory-related issues remain. While a more robust CPU or larger RAM may be probable solutions, these may be expensive. A cost-effective solution would be to split the dataset into smaller subsets and these subsets thus created can be easily loaded and utilized by the individual base models.
A common error committed by beginners using large datasets is that they discard a part of them. This can lead to a less accurate model as important features may be lost along with a portion of the dataset. For example, let us consider a dataset in the form of brain scans of patients, used to build a classifier to detect the presence of a mental disorder. The classifier takes into account the patterns from each image in order to learn how to classify the presence or absence of the disorder. Discarding a portion of the dataset may lead to a drop in accuracy since important features (patterns) may be lost. Thus, the most cost-effective and effective method of using a large dataset to train a neural network is by ensemble modeling.
Why use Ensemble Modeling for Neural Networks?
Neural networks are highly complex models and can be used for a variety of applications. As model complexity rises, so does their ability to better fit the training data. However, this is accompanied by the bane of increased sensitivity. Oversensitivity leads to the neural network being adversely affected by the presence of noise in the data and neglect of important features and patterns essential to training. Thus, almost all neural networks suffer from the same drawback i.e., high variance or the tendency to overfit.
Ensemble modeling of neural networks leads to the addition of bias, which in turn, results in an improvement of the bias-variance tradeoff of the overall model, by lowering the high variance value of the individual members. Apart from an increase in reliability and reduction in generalization error, it may also increase the accuracy of predictions.
Why use large datasets?
One of the main factors which set apart deep learning methods like neural networks from other machine learning techniques is the sheer volume of data required to train them in order to obtain adequate performance. Training on large datasets helps counter the neural network problem of high variance to a certain extent. The chances of overfitting the training data are drastically reduced when the model is exposed to a larger number of samples of data. The main function of deep learning models is to determine the best path from the input parameters to the output ones. For this, it must select suitable features and detect inconspicuous patterns in the dataset. A large dataset enables it does so by offering the following advantages:
1) Feature Selection – Improved feature selection due to exposure to a wide range of features and greater opportunity to identify such patterns.
2) Reduction in Noise – Aids in combatting the problem of noise in data. The more the data, the easier it is to find underlying patterns and overcome the noise.
3) Improved Accuracy – More training data also improves the accuracy and
performance of the model.
Thus, to leverage these benefits, larger datasets are preferred for the training of neural networks.
Procedure of Ensemble Modeling for Neural Networks
In this case, the following steps are performed to create the ensemble model:
1) The dataset is divided into two or more subsets (depending on the size of the dataset)
2) Base models (Convolutional Neural Networks – CNNs here) are built on the subsets of the data. Individual CNNs having similar (or the same) architecture can be used as they will have equivalent performance on subsets of the same dataset. Each model is stored under unique names.
3) The models are loaded.
4) Base models are combined using Keras functional API methods.
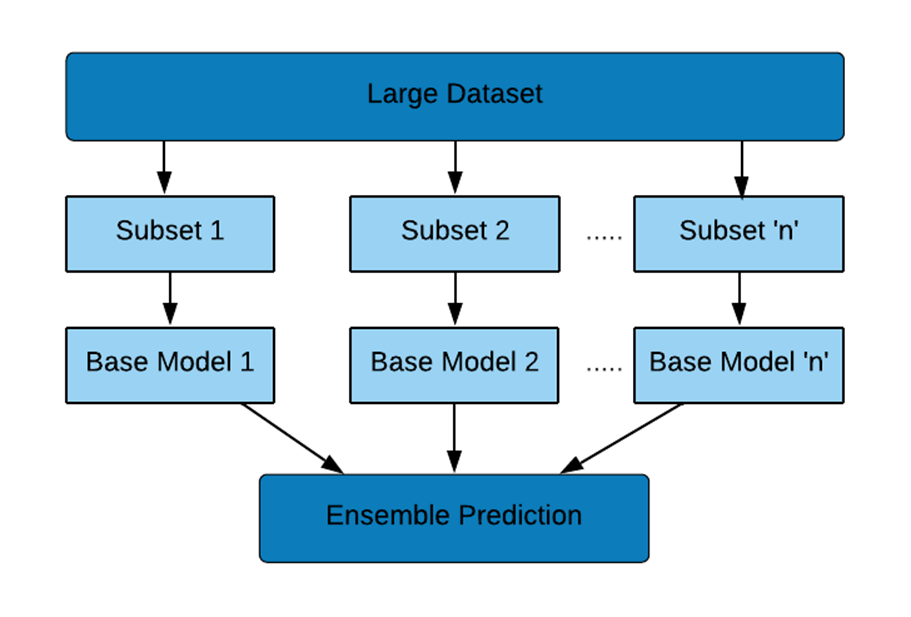
‘n’ in the above flowchart is the suitable number of subsets/base models depending on the size of the training dataset.
Keras functional API provides greater flexibility in the creation of models when compared with Keras sequential API. Complex problems including those with multiple input or output models can be solved with ease using this functionality of Keras. Here, we use Keras sequential API for the creation of base models and Keras functional API for combining them.
Method Summary
Divide the dataset into two or more subsets either manually or by using code.
Create the individual base models using the subsets. Base models may be optimized for their respective subsets by choosing suitable parameters. However, it needs to be ensured that the input shape is constant for all.
Below, the sample code for creation of the average ensemble model using Keras functional API’s Average functional interface, has been provided. Model Averaging is a technique in which multiple models are used for the same problem, and it combines their predictions to obtain a single unified, more accurate model.
Sample code:
After creating the individual base models using the subsets of the training data, the models can be saved as follows:
model.save("m1.tf")
print("Saved model to disk")
Loading all the base models:
from tensorflow.keras.models import load_model
model1 = load_model('m1.tf')
model2 = load_model('m2.tf')
model3 = load_model('m3.tf')
import tensorflow.keras import tensorflow as tf
#Initiating the usage of individual models
keras_model = tensorflow.keras.models.load_model('m1.tf, compile=False)
keras_model._name = 'model1'
keras_model2 = tensorflow.keras.models.load_model('m2.tf', compile=False)
keras_model2._name = 'model2'
keras_model3 = tensorflow.keras.models.load_model('m3.tf', compile=False)
keras_model3._name = 'model3'
models = [keras_model, keras_model2, keras_model3] #stacking individual models in a list
model_input = tf.keras.Input(shape=(124, 124, 1)) #takes a list of tensors as input, all of the same shape
model_outputs = [model(model_input) for model in models] #collects outputs of models in a list
ensemble_output = tf.keras.layers.Average()(model_outputs) #averaging outputs
ensemble_model = tf.keras.Model(inputs=model_input, outputs=ensemble_output)
ensemble_model.summary() #prints a comprehensive summary of the Keras model
Other Keras functions which may be used in place of ‘Average’ (computes the average of a list of inputs, element-wise) are the functions of ‘Maximum’ (computes the maximum of a list of inputs, element-wise) and ‘Add’ (adds a list of inputs) depending on the requirements of the model. The code remains the same, simply replace the word ‘Average’ by ‘Maximum’ or ‘Add’.
Conclusion
We are often faced with memory or computational issues while dealing with large datasets. Neural networks being complex models require large datasets to enhance their performance and thus face such issues often. A simplistic solution to this problem is the splitting of the dataset into suitable number of subsets and building base models on each subset. These subsets are then combined using ensemble modeling – using Keras functional API here. Apart from overcoming the challenge of handling large datasets, ensemble modeling helps overcome several other issues such as large variance and generalization error, by improving the overall accuracy of the model. Thus, to summarize the article, we can state that ensemble modeling offers an easy and cost-effective solution in improving the performance of the model, while also optimizing the usage of computational and storage resources.
About the Author

I am a Data Science enthusiast with a keen interest in the applications of AI in the healthcare sector. Being a first-time blogger, I am writing about my practical experiences while dealing with research projects in this field. Feel free to contact me on LinkedIn: https://www.





