This article was published as a part of the Data Science Blogathon
Introduction
Every day, we are inundated with information. There are numerous articles that we read on a daily basis. As a result, there is a lot of data moving about, largely in the form of text. If we need to learn something about an article, we must read the entire piece to understand it, and many times those articles become excessively long, such as a 5000-word article, which takes a long time. So, in order to receive the useful information contained in 1000 words, we must read the entire 5000-word article, which is a complete waste of time, and if we need to read several articles like that for work purposes, it will take a long time, resulting in a loss of work hour. The goal of text summarizing is to see if we can come up with a method that employs natural language processing to do so. This method will not only save time in comprehending a text, but it will also allow someone to read multiple texts in a short period of time, saving time in the long term.
Types of Text Summarization
There are two types of Text Summarization, one is Extractive Type and another one is Abstractive Type. Extractive summarization takes the original text and extracts information that is identical to it. In other words, rather than providing a unique summary based on the full content, it will rate each sentence in the document against all others, based on how well each line explains. On the other hand, abstractive seeks to construct a one-of-a-kind summary by learning the most significant points from the original text.
An encoder-decoder neural network with an attention model would most likely be used to do abstractive summarization. Rather than using the most representative existing extracts to accomplish the summarizing, abstractive text summarization employs natural language processing techniques to understand the text and generate fresh summarized material. The information from the source text is re-used in this manner. However, it is more difficult to apply because it includes ancillary issues such as semantic representations.
The conventional method and cosine similarity method of text summarization fall under extractive type, and Hugging Face Transformer falls under abstractive type text summarization technique.
The objective of Text Summarization
- Extraction of useful information out of a huge amount of text.
- Reduction of reading time.
- Enable to read more articles as the time for reading each article will be reduced thus gather more information from different articles without losing much time.
- Selecting articles allows one to process more information when reading because only the most significant aspects of the content are captured.
Problem Statement for Text Summarization
An article about Sachin Tendulkar has been collected from the internet which is made of around 691 words. Text summarization will be achieved using Natural Language Processing (NLP) to get important points about that article which are enough in gaining an understanding of the idea of the text.
The codes to achieve this text summarization is written below.
The text document was obtained from the following-
From the source, the text was copied and saved in a Text.txt file which was later uploaded in Google Drive and then in the python notebook that drive was mounted and the .txt file which contains the document was read and stored in a list named contents.
#Google drive file was mounted by running the following code snippet. Now one can access any file from your colab, you can write as well as read from it. The changes will be done in real-time on your drive and anyone having the access link to your file can view the changes made by you from your colab.
from google.colab import drive
drive.mount('/content/drive/')
# file was read and stored in a list named contents
f=open('/content/drive/MyDrive/Text.txt','r',encoding='latin1')
f1=f.readlines()
contents=[]
for line in f1:
contents.append(line)
contents

The list was converted to a string and then Unicode characters “x91” and “]x92” were removed from the string and kept in a variable named text.
#list contents were converted to a string and stored in text
text = ' '.join([str(elem) for elem in contents])
# Unicode character x91 and x92 was replaced with “‘” and kept in variable text.
text=text.replace("x91","'")
text=text.replace("x92","'")
text

The length of the text is found out.
len(text)

Number of words in the string
f=len(text.split())
print ("The number of words in the given text is : " + str(f))

Importing the important libraries.
The spacy library is imported. Spacy is a free open source library for advanced Natural Language Processing. From Spacy STOP_WORDS have been imported.
From String, class punctuation has been imported.
import spacy from spacy.lang.en.stop_words import STOP_WORDS from string import punctuation
“en_core_web_sm” is a small-sized English language model which is loaded via spacy. load and which returns a language object containing all components and data required to process text.
To load the models and data for the English Language, you have to use
spacy. load(‘en_core_web_sm’). Here nlp object is referred to as a language model instance.
nlp= spacy.load("en_core_web_sm")
The whole text has been applied to the NLP model and assigned to some doc objects.
When dealing with spaCy, the initial step for a text string is to give it to an NLP object. This object is essentially a text pre-processing pipeline through which the input text string must pass. Tokenizer, tagger, parser, ner, and other components make up the NLP pipeline. So, before we can act on the input text string, it must pass through all of these components.
The raw text data often referred to as text corpus has a lot of noise. There is punctuation, suffices, and stop words that do not give us any information. Text Processing involves preparing the text corpus to make it more usable for NLP tasks. A text can be converted into nlp object of spaCy as shown using nlp(text) function. Here ‘nlp’ is an object of our small-sized model so we are going to use it for further coding. Processing text with the nlp object returns a Doc object that holds all information about the sequence of tokens, their linguistic features and their relationships.
doc=nlp(text)
Iterate over every single token using list comprehension and these are the tokens to be worked upon.
tokens=[token.text for token in doc] print(tokens)

These are the all punctuations and one extra punctuation ‘n’ has been added.
punctuation=punctuation+’n’
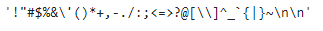
Text Cleaning
An empty dictionary word_freq has been created.
word_freq={}
The list of STOP_WORDS has been stored in the stop_words variable.
stop_words= list(STOP_WORDS)
A loop has been run over the doc to get those words that are not in the list of STOP_WORDS and also not in the list of punctuations, and then the words were added to the word_freq dictionary and the number of times they appear in doc has been added as a value in the dictionary.
for word in doc:
if word.text.lower() not in stop_words:
if word.text.lower() not in punctuation:
if word.text not in word_freq.keys():
word_freq[word.text]= 1
else:
word_freq[word.text]+= 1
print(word_freq)
The maximum no of times a word appear has been figured out stored in variable max_freq.
x=(word_freq.values()) a=list(x) a.sort() max_freq=a[-1] max_freq
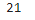
All the score of the words in word_freq dictionary has been normalized by dividing each value in the dictionary by max_freq and to do this a loop has been run on word_freq dictionary and all the values were normalized.
Sentence Tokenization
for word in word_freq.keys(): word_freq[word]=word_freq[word]/max_freq print(word_freq)
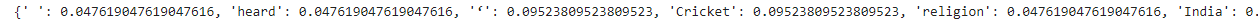
Sentences in doc objects have been segmented by using the list comprehension method and kept in variable sent_tokens.
sent_score={}
sent_tokens=[sent for sent in doc.sents]
print(sent_tokens)

A score of each individual sentence has been found out based on the word_freq counter. An empty dictionary sent_score has been created which will hold each sentence as a key and its value as a score. A loop was iterated on each individual sentence and it was checked the words in those sentences if appear in word_freq dictionary and then based on the score of a word in word_freq dictionary sent_score has been determined.
for sent in sent_tokens:
for word in sent:
if word.text.lower() in word_freq.keys():
if sent not in sent_score.keys():
sent_score[sent]=word_freq[word.text.lower()]
else:
sent_score[sent]+= word_freq[word.text.lower()]
print(sent_score)

Select 30% sentences with a maximum score
From the above shown sent_score values it can be observed that the first-ever sentence having a score of 0.57, and so on. So we tried to grab all the sentences having the maximum value. Here we tried to grab 30% of sentences which is having a maximum score out of this sent_score dictionary was selected and to do that first we grabbed how many total sentences are there in the dictionary by passing sent_score in the len() function which gives us a value of 44, then we evaluated 30% of that which comes to 13, that means maximum 13 sentences we can grab and to grab first 13 sentences we used nlargest() function and these particular 13 sentences will just combine and we will assign it as a summary of all.
There is no hard and fast rule of choosing the first 30% of sentences having a maximum score, for my case I have chosen that, one can choose 20 or 40 percent as well. If a lower percentage is chosen, the total number of sentences required to comprehend the entire text will be reduced, so to preserve a balance We chose 30% since there aren’t too few sentences that won’t help us comprehend the core of the text, and there aren’t too many sentences that will make the summary too long.
A priority queue is commonly represented using the data structure ‘heap.’ The heapq module in the Python standard library can be used to carry out this implementation. The functions of the heapq module serve the goal of choosing the best element. In Python, the heap data structure has the feature of always popping the smallest heap member (min-heap). The heap structure is preserved whenever data pieces are popped or pushed.
From heapq module nlargest library was imported. from the total sent_score, 30% has been evaluated which comes to 13, which means a maximum of 13 sentences can be extracted which contains all important information.
from heapq import nlargest len(sent_score) *0.3
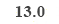
Getting Summary
This nlargest(k, iterable, key = fun): This function is used to return the k prominent elements from the iterable specified and satisfying the key if mentioned.
Three parameters were passed to nlargest() function. The first parameter is the maximum number of sentences which in this case is 13. The second parameter is iterable on which we are going to apply this and in this case, it’s sent_score. The third parameter is based on which key we are going to do all these things are here it s sent_score.get, here get is used as a function which will return us those values sent_score based on which we will get 13 sentences having 30% of maximum value.
summary=nlargest(n=13,iterable=sent_score,key=sent_score.get) print(summary)

List comprehension was applied to get the final summarized text.
final_summary=[word.text for word in summary] final_summary

re module was imported to perform regex operation.
import re
Empty list f1 was created and a loop was run on the final extracted text, then regex operation was done to remove ‘n’ from all text and appended to list f1.
f1=[]
for sub in final_summary:
f1.append(re.sub('n','',sub))
f1

The list of final summarized text was converted to string using the join() function and kept in variable f2.
f2=" ".join(f1) f2

The split() function was used to count the number of words in the final string.
f3=len(f2.split())
print ("The number of words in final summary is : " + str(f3))

Text Summarization using Hugging Face Transformer
Hugging Face Transformer uses the Abstractive Summarization approach where the model develops new sentences in a new form, exactly like people do, and produces a whole distinct text that is shorter than the original.
The procedures of text summarization using this transformer are explained below.
Required Libraries have been installed.
!pip install transformers
import transformers
File is read
f = open("/content/drive/MyDrive/Text.txt", "r", encoding="latin1")
to_tokenize = f.readlines()
# Initialize the HuggingFace summarization pipeline
summarizer = pipeline("summarization")
summarized = summarizer(to_tokenize, min_length=75, max_length=300)
# # Print summarized text
print(summarized)
The list is converted to a string
summ=' '.join([str(i) for i in summarized])
Unnecessary symbols are removed using replace function.
summ=summ.replace("{","")
summ=summ.replace("''","")
summ=summ.replace("\x92","")
print cleaned text
summ

The split() function was used to count the number of words in the final string.
summ1=len(summ.split())
print(" The no. of words in the summarization is :" +str(summ1))

Text Summarization using Cosine Similarity
The cosine similarity falls under the extractive text summarization method. A measure of similarity between two non-zero vectors is cosine similarity. It can be used to identify similarities between sentences because we’ll be representing our sentences as a collection of vectors. It calculates the angle between two vectors’ cosine. If the sentences are comparable, the angle will be zero.
The cosine Similarity approach is as follows:
Cosine Similarity measures the similarity between two sentences or documents in terms of the value within the range of [-1, 1] whichever you want to measure. That is the Cosine Similarity. Cosine Similarity extracted TF and IDF by using the following formulae:
TFIDF
TF (term, document) = Frequency of term / No of Terms
The IDF (inverse document frequency) method determines if a word is uncommon or frequent throughout all documents. The IDF (term, document) is trained by dividing the total number of documents by the number of documents that contain that term and keeping track of the results.
IDF (term, document) = log (total number of documents / Number of documents containing term)
For a given word, TF-IDF is the multiplication of the TF and IDF values. The value of TF-IDF grows as the number of occurrences inside a document grows, as does the variety of terms used across the content.
tfidf= tf * idf
As an example consider a document containing 100 words wherein the word “Sachin” appears 3 times. The term frequency (tf) for “Sachin” is then TF=(3/100)=0.03. Now, assume we have 100 documents, and the word “Sachin” appears in 10 of these. Then, the inverse document frequency (IDF) is calculated as IDF = log(100 / 10) = 1.
Thus, the Tf-idf weight is the product of these quantities
TF-IDF = 0.03 * 1 = 0.03.
Summary Generation
Relevant sentences are extracted and merged into one utilizing the cosine similarity approach after assessing the similarity-based approach and document relevancy. As a result, it generates a final summary after integrating the data.
The summarization using the above method is implemented below using python codes.
Import all necessary libraries
from nltk.corpus import stopwords
from nltk.cluster.util import cosine_distance
import numpy as np
import networkx as nx
Generate Clean sentence
def read_article(file_name):
file = open(file_name, "r")
filedata = file.readlines()
article = filedata[0].split(". ")
sentences = []
for sentence in article:
print(sentence)
sentences.append(sentence.replace("[^a-zA-Z]", " ").split(" "))
sentences.pop()
return sentences
Similarity Matrix
cosine similarity to find similarity between sentences.
def build_similarity_matrix(sentences, stop_words):
# Create an empty similarity matrix
similarity_matrix = np.zeros((len(sentences), len(sentences)))
for idx1 in range(len(sentences)):
for idx2 in range(len(sentences)):
if idx1 == idx2: #ignore if both are same sentences
continue
similarity_matrix[idx1][idx2] = sentence_similarity(sentences[idx1], sentences[idx2], stop_words)
return similarity_matrix
Generate Summary Method
The method will keep calling all other helper functions to keep our summarization pipeline going.
def generate_summary(file_name, top_n=5):
stop_words = stopwords.words('english')
summarize_text = []
# Step 1 – Read the text and tokenize
sentences = read_article(file_name)
# Step 2 – Generate Similarly Matrix across sentences
sentence_similarity_martix = build_similarity_matrix(sentences, stop_words)
# Step 3 – Rank sentences in the similarity matrix
sentence_similarity_graph = nx.from_numpy_array(sentence_similarity_martix)
scores = nx.pagerank(sentence_similarity_graph)
# Step 4 – Sort the rank and pick top sentences
ranked_sentence = sorted(((scores[i],s) for i,s in enumerate(sentences)), reverse=True)
print("Indexes of top ranked_sentence order are ", ranked_sentence)for i in range(top_n):
summarize_text.append(" ".join(ranked_sentence[i][1]))
# Step 5 – Offcourse, output the summarized text, and five important sentences are selected
print("Summarize Text: n", ". ".join(summarize_text))
generate_summary( "/content/drive/MyDrive/Text.txt",5)

Conclusion
The article on Sachin Tendulkar was condensed into a 259-word document from a 691-word original using the conventional method and ended up in a 461-word document using the Hugging Face Transformer method. Moreover using the Cosine Similarity method we got five important sentences and applying all these methods the obtained condensed document contains vital information that is the essence of the entire piece, making it understandable in a short amount of time.
My Linkedin ID is: Linkedin




