This article was published as a part of the Data Science Blogathon.
Artificial Neural Networks can be used to solve a wide variety of problems. Keras is an open-source library that can be used to implement artificial neural networks in Keras. Keras has all the major features required to build and train artificial neural networks. We shall be using Keras Sequential Model to authenticate banknotes. The dataset is taken from UCI Machine Learning. The dataset has information extracted from real and forged banknotes. The features from the images have been extracted using a Wavelet Transform tool.
The Data
The data contains the following features:
1. variance of Wavelet Transformed image (continuous)
2. skewness of Wavelet Transformed image (continuous)
3. kurtosis of Wavelet Transformed image (continuous)
4. entropy of image (continuous)
5. class (integer)
( Source: https://archive.ics.uci.edu/ml/datasets/banknote+authentication)
So, basically, 4 features have numeric data and one feature is the class that is to be trained/ predicted. The purpose of taking the data from UCI Machine Learning is that the data is consistent and reliable.
The data was extracted from genuine and forged banknote specimens. The problem at hand is to classify a banknote as genuine or fake. Differentiating a genuine banknote from a forged one is very important. Manually detecting fake banknotes is a very difficult task, especially if the notes are in the 100s. Deep Learning can help in this case. This problem of differentiating a real banknote and a fake banknote can be solved by using artificial neural networks.
What are Artificial Neural Networks?
Artificial Neural Networks are computational models which mimic the way the human brain functions. If we look back to history, the original purpose of Artificial Intelligence was to replicate the working of the human brain. The human neurons have inspired the working of Artificial Neural Networks. The major improvement of ANNs over traditional machine learning models is that ANNs can make adjustments as they receive new data and inputs. This feature makes them perfect for advanced modelling and functions.
Artificial Neural Networks have many layers that are interconnected. The first layer consists of input neurons, and the last layer consists of the output neurons. The inner layers are hidden. The data and information move from layer to layer and face a series of transformations.
An important fact about ANNs is that they use samples from the entire data to arrive at solutions, rather than using the entire data. ANNs also make use of backpropagation to adjust their output results. The weights are updated regularly to match how much they are responsible for the error.

( Image: https://www.pexels.com/photo/technology-computer-lines-board-50711/ )
There are, however, many limitations to the use of ANNs. First of all, they need a huge amount of data to perform properly, which is not always readily available. They are also not perfect at generalizing. The limitations of Neural Networks are clear as they often perform as black boxes, that is their functioning is opaque. They don’t perform well in solving mathematical equations. In Spite of all these limitations, ANNs are quite useful in many aspects, they can be used for predictive analysis, classification, NLP, chatbots and so on.
What is Keras?
Keras is an open-source deep learning framework that can be used in Python. It was written by Francois Chollet, an engineer at Google. Keras supports the fast and simple implementation of deep neural networks. Keras supports the use of Convolutional Networks as well as Recurrent Networks and also their combinations. Many big companies like Google, Microsoft, Netflix, Huawei and Uber are using Keras and they also contribute to the development of Keras.
Keras is very easy and simple to use as it focuses on user experience. Keras has large adoption in the industry and supports simple and fast prototyping. It doesn’t necessarily need GPUs to run and can run on CPUs as well. Keras is very easy to get started with and beginners can learn Keras easily. Building and implementing models is easy with Keras.
Keras is basically an API, which decreases the cognitive load on the user. Keras can be run using TensorFlow, Theano, CNTK, or MXNet as per the needs. Keras offers higher-end building blocks.
Keras has a huge community backing and a lot of people have knowledge about Keras. Many AI companies use Keras, so learning Keras is good for someone’s career. One important feature about Keras is that it supports Data Parallelism, which means it can be trained on multiple GPUs at one time. The layers in Keras are pre-configured, which can be both an advantage and a disadvantage. It is very good for beginners, but it makes things difficult if you want to have an abstract layer.
The overall Keras API can be divided into 3 parts:
- Model
- Layer
- Core Modules
Keras Models represent the ANNs. Every Keras Sequential Model is a composition of Keras layers. ANN layers are represented, like the Input layer, an output layer, convolution layer etc.
Keras Models are mainly sequential models. A linear composition of Keras layers forms a sequential model. It is simple and easy to implement.
Getting Started with the Code
First, we import the necessary libraries.
import numpy as np import pandas as pd import seaborn as sns import matplotlib.pyplot as plt %matplotlib inline
Now, we read the data. All the code will be shared in a Kaggle notebook.
banknotes= pd.read_csv('/kaggle/input/banknote-authentication-uci/BankNoteAuthentication.csv' )
Let us now have a look at the data.
banknotes.head()
Output:
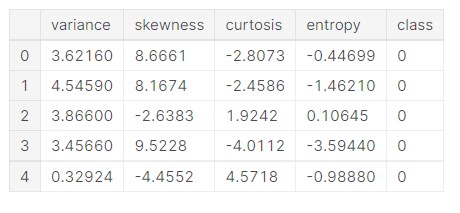
The data is as we had discussed earlier, there are 4 continuous data features and one class variable.
- variance – variance is the amount by which something changes or is different from something else
- skewness – skewness is the amount by which something changes or is different from something else
- kurtosis – kurtosis refers to the pointedness of a peak in the distribution curve.
- entropy – entropy is the measure of disorder or uncertainty
Now, let us implement some data distribution metrics to understand the data.
# Use pairplot and set the hue to be our class
sns.pairplot(banknotes,hue='class')
# Describe the data
print('Dataset stats: n', banknotes.describe())
Output:
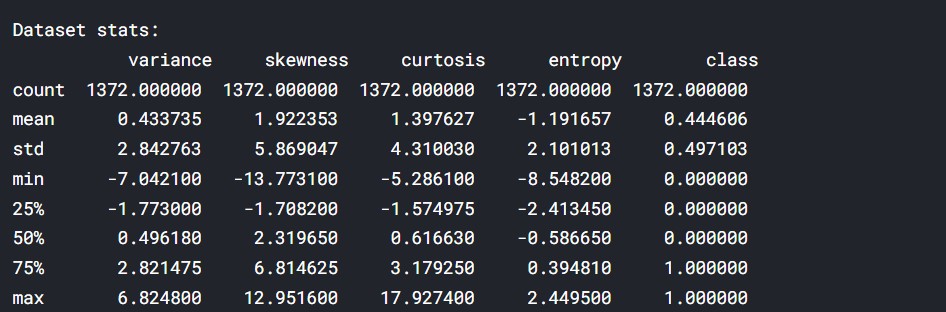
Here, we can analyse the mean and distribution of data. The mean of the class is close to 0.5 which makes it clear that the data is balanced.
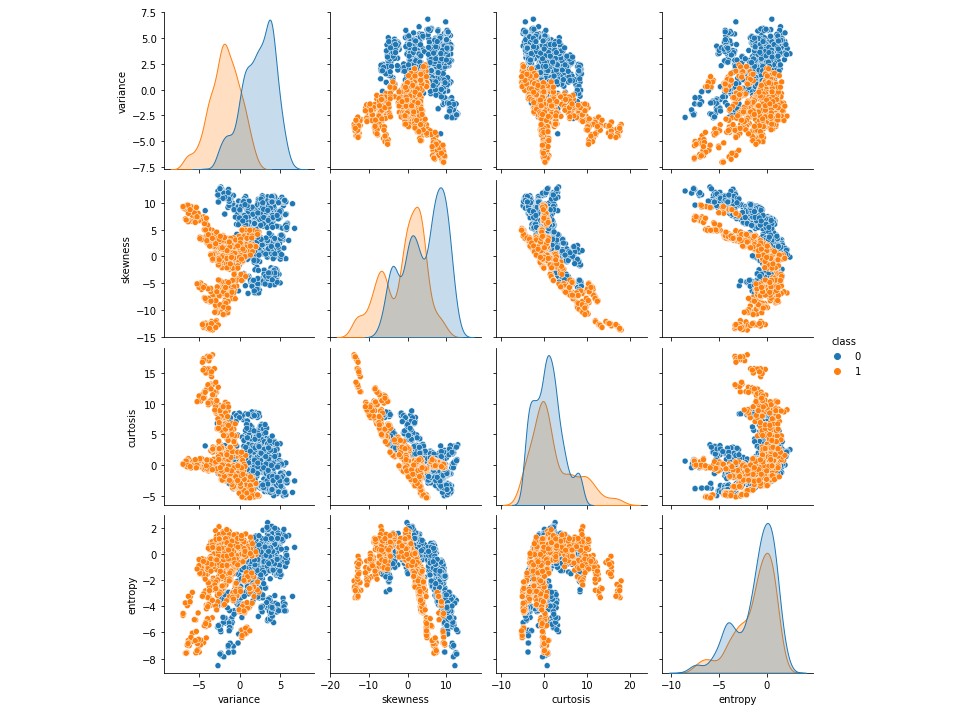
The scatter plots show that the classes are distinct and separate.
A correlation heat map will show which features are related to each other.
sns.heatmap(banknotes.corr(),annot=True,cmap='mako',linewidths=0.2) fig=plt.gcf() fig.set_size_inches(12,6) plt.show()
Output:
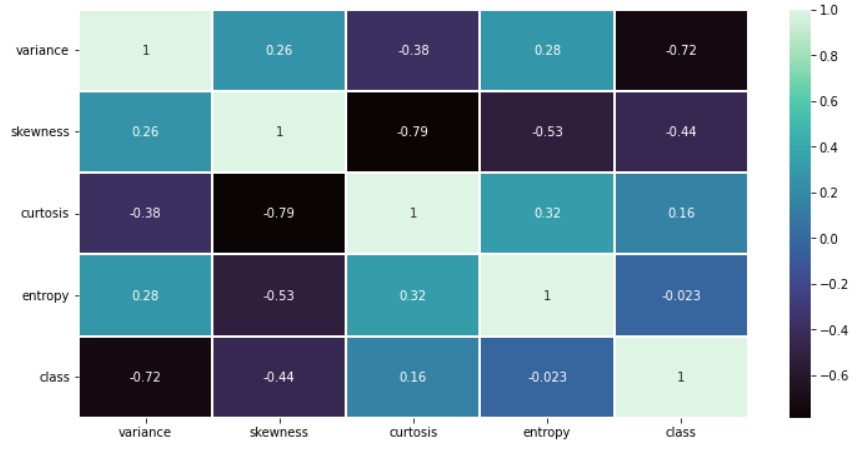
There is a high negative correlation between kurtosis and skewness. Moderate high relation is there between kurtosis and entropy. The correlations are all over the place, but these show that the data is appropriate for training a neural network.
Data Distribution Plots
Let us plot the data distribution for each of the variables.
sns.displot(banknotes["variance"], height= 5, aspect=1.8)
plt.xlabel("Variance")
Output:
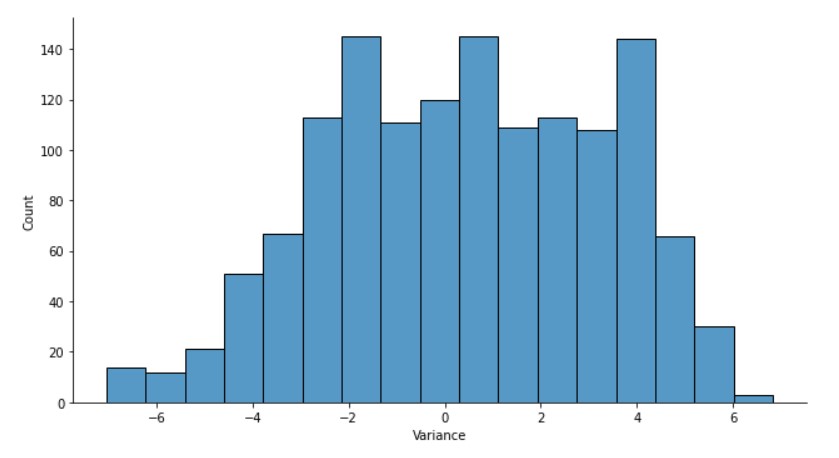
Variance seems to follow a somewhat Normal distribution.
sns.displot(banknotes["skewness"], height= 5, aspect=1.8)
plt.xlabel("Skewness")
Output:
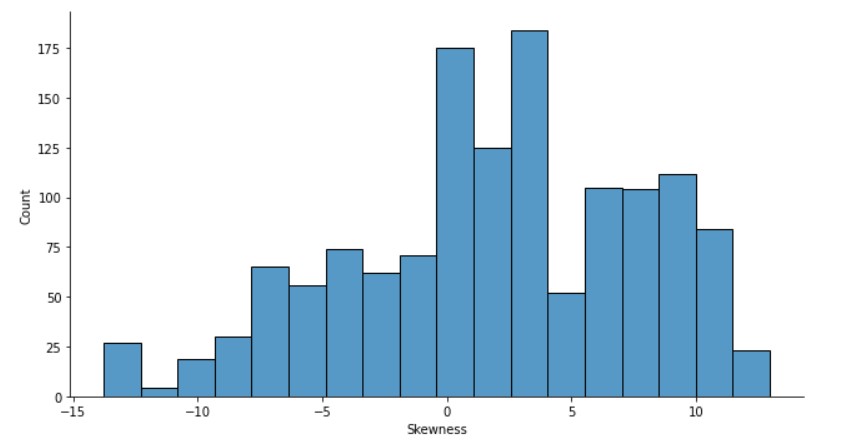
Skewness is more distributed to the positive side.
sns.displot(banknotes["curtosis"], height= 5, aspect=1.8)
plt.xlabel("Curtosis")
Output:
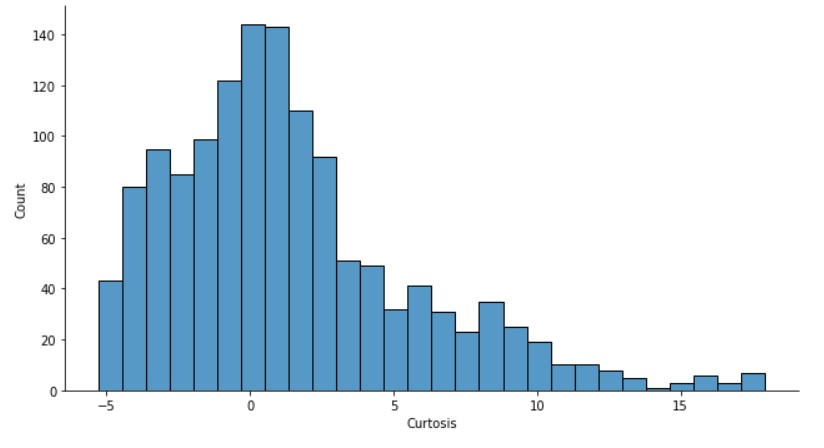
Kurtosis is more skewed to the negative side, with maximum data points being near zero.
sns.displot(banknotes["entropy"], height= 5, aspect=1.8)
plt.xlabel("Entropy")
Output:
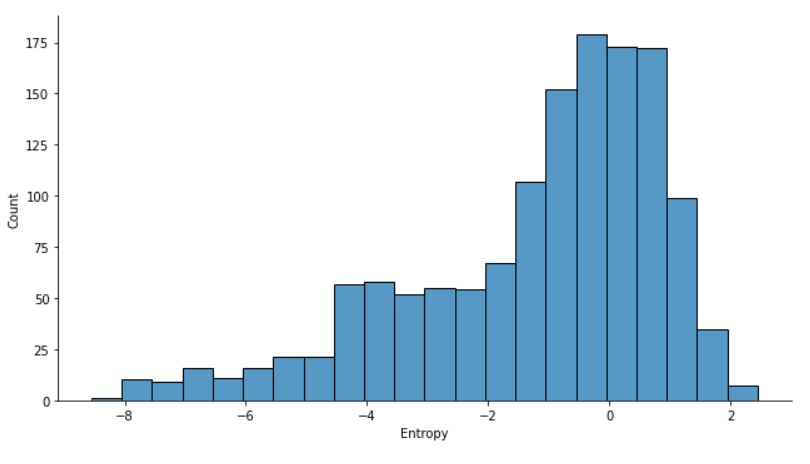
The data distribution of Entropy seems to be the opposite of Kurtosis.
Let us see the class distribution.
sns.countplot(data= banknotes, y="class")
plt.xlabel("Class")
Output:
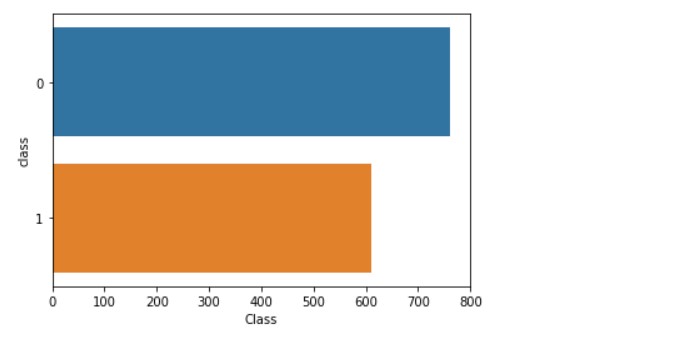
So, we can confirm that the classes are balanced.
Creating the Model
Now, let us proceed with creating the model.
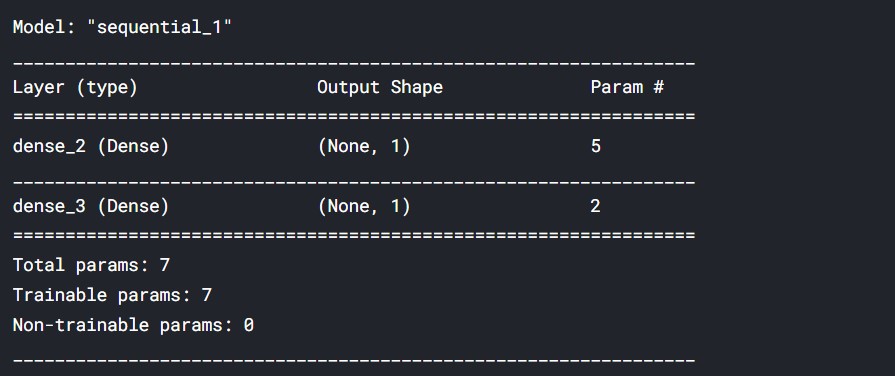
# Import the sequential model and dense layer from keras.models import Sequential from keras.layers import Dense from keras.callbacks import EarlyStopping # Create a sequential model model = Sequential() # Add a dense layer model.add(Dense(1, input_shape=(4,), activation='sigmoid')) model.add(Dense(1, input_shape=(3,), activation='sigmoid')) # Compile your model model.compile(loss='binary_crossentropy', optimizer='sgd', metrics=['accuracy'])
Let us now have a look at the model summary.
# Display a summary of your model model.summary()
Output:
Let us take the input and output variables.
X=banknotes[['variance','skewness', 'curtosis','entropy']]
y=banknotes[["class"]]
Now, we split the data into test and train sets.
#splitting the data into test and train sets from sklearn.model_selection import train_test_split train_X, test_X, train_y, test_y = train_test_split(X, y, test_size=0.35, random_state = 7)
Now, we train the model and evaluate it.
# Train your model
model.fit(train_X, train_y, epochs=30)
# Evaluate your model accuracy on the test set
accuracy = model.evaluate(test_X, test_y)[1]
# Print accuracy
print('Accuracy:',accuracy)
Output:
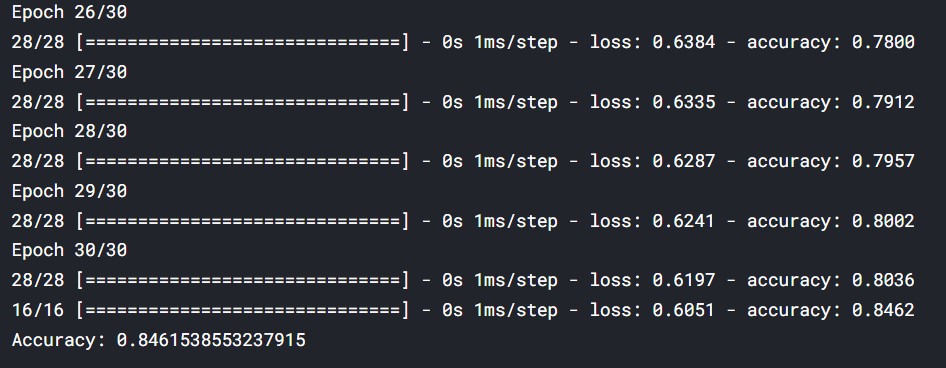
We see that the accuracy is 0.84.
The early stopping callback is a useful feature. It allows us to stop the model training if it no longer improves after a given number of epochs. To use it, we need to pass the callback inside a list to the model’s callback parameter in the .fit() method.
monitor_val_acc = EarlyStopping(monitor='accuracy', mode="max",
patience=6)
# Train your model using the early stopping callback
model.fit(train_X, train_y,
epochs=100, validation_data=(test_X, test_y),
callbacks=[monitor_val_acc])
Output:
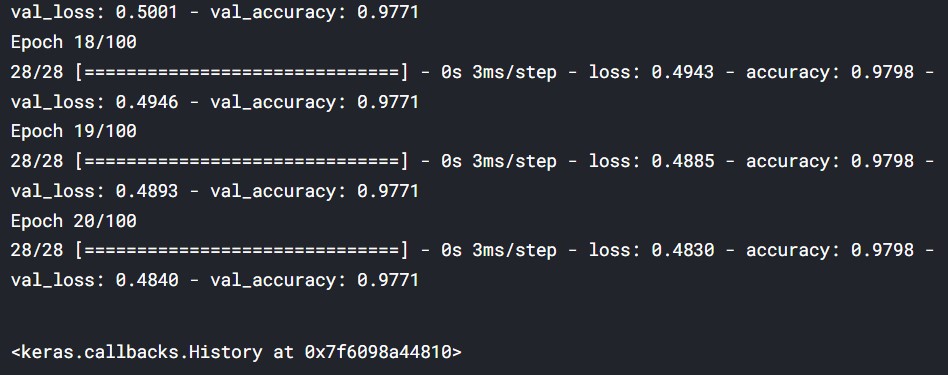
We had given the model up to 100 epochs, but the training stopped at 20 epochs.
The accuracy was 0.97.
Let us evaluate it again one last time.
print(model.evaluate(test_X, test_y)[1])
Output:

So, the result stays the same.
We can see that using Neural Networks to do the predictions gave great results.
Conclusion
The sequential API is the simple way to arrange Keras layers in sequential order. The data flow from the input layer to the output layer. The installation and usage of Keras is also very easy and simple, so beginners can also use it.
The vast amount of resources to learn and use Keras make it a great choice for implementing neural networks.
Code:
https://www.kaggle.com/prateekmaj21/banknote-authentication-using-keras
About me
Prateek Majumder
Analytics | Content Creation
Connect with me on Linkedin.
My other articles on Analytics Vidhya: Link.
Thank You.
Prateek is a dynamic professional with a strong foundation in Artificial Intelligence and Data Science, currently pursuing his PGP at Jio Institute. He holds a Bachelor's degree in Electrical Engineering and has hands-on experience as a System Engineer at TCS Digital, where he excelled in API management and data integration. Prateek also has a background in product marketing and analytics from his time with start-ups like AppleX and Milkie Way, Inc., where he was involved in growth campaigns and technical blog management. Recognized for his structured thinking and problem-solving abilities, he has received accolades like the Dr. Sudarshan Chakraborty Award for Best Student Performance. Fluent in multiple languages and passionate about technology, Prateek continues to expand his expertise in the rapidly evolving AI and tech landscape.


