Introduction
Keyphrase extraction is concerned with automatically extracting a set of representative phrases from a document that concisely summarize its content (Hasan and Ng, 2014). A key phrase is a short phrase (usually one to three words) that provides a key idea of a document and reflects the content of one document, thus capturing the main topics discussed and providing a summary of its content.
In this tutorial, we are going to show you how to extract keywords from text documents in a smooth and simple way step by step, using TFIDF with Python. The Keyword/phrases extraction process consists of the following steps:
- Pre-processing: Documents processing to eliminate noise.
- Forming candidate tokens: Forming n-gram tokens as candidate keywords.
- Keyword weighting: calculating TFIDF weight for each n-gram token using vectorizer TFIDF.
- Ranking the candidate words in descending order according to their TFIDF weights.
- Select Top n keywords.
Prepare Dataset
In this tutorial, we will use the Theses 100 standard dataset for evaluating our keyword extraction method. These 100 dataset consists of 100 complete masters and doctoral dissertations from the University of Waikato, New Zealand. Here we use a version that contains only 99 files. A file has been deleted because it does not contain keywords. Dissertation topics are very diverse: from chemistry, computer science and economics to psychology, philosophy, history and others. The average number of gold keywords per document is about seven 7.67.
There is a set of datasets (Here). You can download the data set you want to your drive. For this tutorial, we chose These 100 and assumed that the database folder is stored on your drive. I will write a function to retrieve documents and their keywords and store the output as a dataframe.
Read the data
import os path = "/content/drive/MyDrive/Data/theses100/theses100/" all_files = os.listdir(path+"docsutf8") all_keys = os.listdir(path+ "keys") print(len(all_files)," files n",all_files, "n", all_keys) # won't necessarily be sorted
all_documents =[]
all_keys = []
all_files_names = []
for i, fname in enumerate(all_files):
with open(path+'docsutf8/'+fname) as f:
lines = f.readlines()
key_name= fname[:-4]
with open(path+'keys/'+key_name+'.key') as f:
k = f.readlines()
all_text = ' '.join(lines)
keyss = ' '.join(k)
all_documents.append(all_text)
all_keys.append(keyss.split("n"))
all_files_names.append(key_name)
#------------------------------------------------------------------------------
import pandas as pd
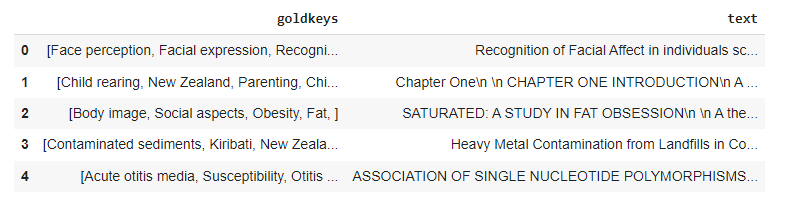
dtf = pd.DataFrame({‘goldkeys’: all_keys, ‘text’: all_documents})
dtf.head()
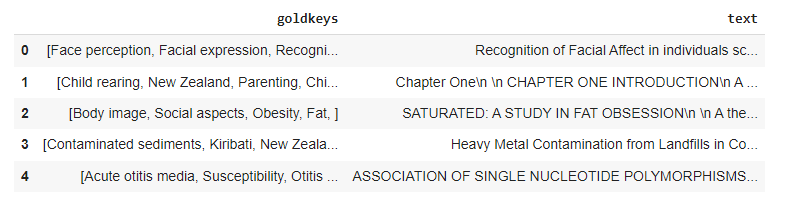
Now we have the data that needs to be cleaned up to remove unwanted noise.
Text Pre-Processing
Preprocessing includes tokenization, lemmatization, lowercasing, removing numbers, white spaces and words shorter than three letters, removing stop words, remove symbols and punctuation. We are not going to explain these functions because that is not the purpose of this article.
For lemmatization, WordNetLemmatizer was used. I do not recommend performing the steaming because it changes the root of the word in some cases.
#clean text applying all the text preprocessing functions dtf['cleaned_text'] = dtf.text.apply(lambda x: ' '.join(preprocess_text(x))) dtf.head()
However, before using this line of code you must define the function preprocess_text first. Make sure to write the following code and then apply the preprocess_text function to the dataframe.
Importing the used libraries
import nltknltk.download('stopwords')
nltk.download('wordnet')
# For cleaning the text
import spacy
import nltk
from nltk.tokenize import word_tokenize
from nltk.corpus import stopwords
import regex as re
import string
import numpy as np
import nltk.data
import re
nltk.download('punkt')
nltk.download('averaged_perceptron_tagger')
from nltk.stem import WordNetLemmatizer
from nltk import word_tokenize, sent_tokenize, pos_tag
Function for preprocessing:
def preprocess_text(text):
# 1. Tokenise to alphabetic tokens
text = remove_numbers(text)
text = remove_http(text)
text = remove_punctuation(text)
text = convert_to_lower(text)
text = remove_white_space(text)
text = remove_short_words(text)
tokens = toknizing(text)
# 2. POS tagging
pos_map = {'J': 'a', 'N': 'n', 'R': 'r', 'V': 'v'}
pos_tags_list = pos_tag(tokens)
#print(pos_tags)
# 3. Lowercase and lemmatise
lemmatiser = WordNetLemmatizer()
tokens = [lemmatiser.lemmatize(w.lower(), pos=pos_map.get(p[0], 'v')) for w, p in pos_tags_list]
return tokens
#------------------------------------------------------------------------------
def convert_to_lower(text):
return text.lower()
#------------------------------------------------------------------------------
def remove_numbers(text):
text = re.sub(r'd+' , '', text)
return text
#------------------------------------------------------------------------------
def remove_http(text):
text = re.sub("https?://t.co/[A-Za-z0-9]*", ' ', text)
return text
#------------------------------------------------------------------------------
def remove_short_words(text):
text = re.sub(r'bw{1,2}b', '', text)
return text
#------------------------------------------------------------------------------
def remove_punctuation(text):
punctuations = '''!()[]{};«№»:'",`./?@=#$-(%^)+&[*_]~'''
no_punctuation = ""
for char in text:
if char not in punctuations:
no_punctuation = no_punctuation + char
return no_punctuation
#------------------------------------------------------------------------------
def remove_white_space(text):
text = text.strip()
return text
#------------------------------------------------------------------------------
def toknizing(text):
stop_words = set(stopwords.words('english'))
tokens = word_tokenize(text) ## Remove Stopwords from tokens result = [i for i in tokens if not i in stop_words] return result

After that, we clean the golden keywords for each document and perform lemmatization to facilitate the matching process later with the words that will be produced by the TFIDF with Python algorithm.
# Clean the basic keywords and remove the spaces and noise
def clean_orginal_kw(orginal_kw):
orginal_kw_clean =[]
for doc_kw in orginal_kw:
temp =[]
for t in doc_kw:
tt = ' '.join(preprocess_text(t))
if len(tt.split())>0:
temp.append(tt)
orginal_kw_clean.append(temp)
return orginal_kw_clean
#_______________________________________________
orginal_kw= clean_orginal_kw(dtf['goldkeys'])
TFIDF Keywords Extraction
1. Generating n-grams (keyphrases) and weighing them
First we import Tfidf Vectorizer from the text feature extraction package. In the second line we set idf=true i.e. we want to use the inverse document frequency IDF with the term frequency. Its maximum value is 0.5, which means that we only want terms that occur in 50 per cent of the documents (for our case in 49 documents, out of 99). If a term appears in more than 50 documents, it will be deleted because it is considered non-discriminatory at the corpus level. We specify the range of n-grams from one to three (you can set it to a larger number, but according to the statistics of the current data set, the largest proportion is for keywords that are 1-3 in length)
The third line generates documents’ vectors.
from sklearn.feature_extraction.text import TfidfVectorizer vectorizer = TfidfVectorizer(use_idf=True, max_df=0.5,min_df=1, ngram_range=(1,3)) vectors = vectorizer.fit_transform(dtf['cleaned_text'])
Then for each document, we want to build a dictionary (dict_of_tokens) where the key is the word and the value is the TFIDF weight. We create a list of tfidf_vectors to store the dictionaries of all documents.
dict_of_tokens={i[1]:i[0] for i in vectorizer.vocabulary_.items()}
tfidf_vectors = [] # all deoc vectors by tfidf
for row in vectors:
tfidf_vectors.append({dict_of_tokens[column]:value for (column,value) in zip(row.indices,row.data)})
Let’s see what this dictionary contains for the first document

The content of the dictionary for the first document
Everything makes sense! The number of dictionaries is the same as the number of documents, and we see that the dictionary of the first document contains every n-gram with its TFIDFweight.
2. Sorting keyphrases by TFIDF weights
The next step is to simply sort the n-grams in each dictionary according to the TFIDF weight in descending order. Set “reverse=True” to make the order descend.
doc_sorted_tfidfs =[] # list of doc features each with tfidf weight #sort each dict of a document for dn in tfidf_vectors: newD = sorted(dn.items(), key=lambda x: x[1], reverse=True) newD = dict(newD) doc_sorted_tfidfs.append(newD)
Now you can get a list of keywords without their weights.
tfidf_kw = [] # get the keyphrases as a list of names without tfidf values
for doc_tfidf in doc_sorted_tfidfs:
ll = list(doc_tfidf.keys())
tfidf_kw.append(ll)
For example, let’s choose the Top 5 keywords for the first document.

Great, it works!
Performance Evaluation
The above is sufficient to use the method in extracting keywords or keyphrases, but in the following, we want to evaluate the effectiveness of the method in a scientific way according to a standard metric for this type of task.
First I would like to note that we use an exact match for the evaluation, where the keyphrase automatically extracted from the document must exactly match the document’s gold standard keyphrase.
Keyword extraction is a ranking problem. One of the most commonly used measures for ranking is “Mean average precision at K, MAP@K. To calculate MAP@K, the precision at K elements p@k is first considered as the basic metric of the ranking quality for one document.
def apk(kw_actual, kw_predicted, top_k=10):
if len(kw_predicted)>top_k:
kw_predicted = kw_predicted[:top_k]
score = 0.0
num_hits = 0.0
for i,p in enumerate(kw_predicted):
if p in kw_actual and p not in kw_predicted[:i]:
num_hits += 1.0
score += num_hits / (i+1.0)
if not kw_actual:
return 0.0
return score / min(len(kw_actual), top_k)
def mapk(kw_actual, kw_predicted, top_k=10):
return np.mean([apk(a,p,top_k) for a,p in zip(kw_actual, kw_predicted)])
This function apk accepts two parameters: the list of keywords predicted by the TFIDF method (kw_predicted), and the list of gold standard keywords (kw_actual). The default value for k is 10. Here we print MAP value at k=[5,10,20,40].
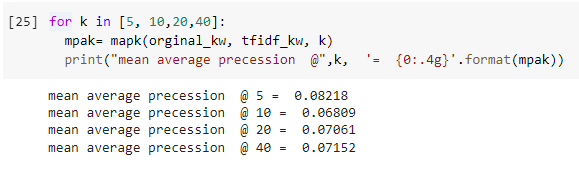
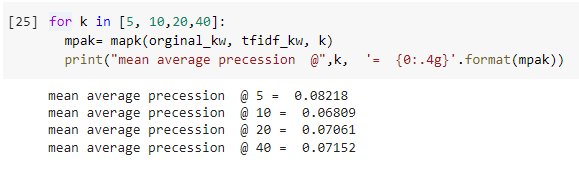
for k in [5, 10,20,40]:
mpak= mapk(orginal_kw, tfidf_kw, k)
print("mean average precession @",k, '= {0:.4g}'.format(mpak))
Conclusion
In this article, we have presented an easy and simple way to extract keywords from documents using TFIDF with Python. The code was written in Python and explained step by step. The performance of the method was evaluated using the MAP criterion as a ranking task. This method, despite its simplicity, is very effective and is considered one of the strong baselines in this field. I hope the content was useful for you. You can check the code on my repository at GitHub. I would be grateful for any feedback.



All images are screenshots by me (Author: Ali Mansour)
Want to know more about TFIDF with Python? Read here.
The media shown in this article is not owned by Analytics Vidhya and are used at the Author’s discretion.







Thank you it is very helpful
[…] post Fast and Effective ways to Extract Keyphrases using TFIDF with Python appeared first on Analytics […]
[…] Source link […]
Thanks for sharing!! please reformat the text beautifully. The font is large and untidy