
Introduction
Have you ever imagined how Amazon Prime, Netflix, and Google predict your taste in movies so easily? It is no rocket science, that after completing one movie/series you loved, and rated it on these platforms, a few more adds up to the suggested or ‘You May Like this ‘ section in seconds! It is Machine Learning. A recommendation system predicts and filters user preferences after learning about the user’s past choices. As simple as that!
There are generally two types of Recommendation Systems-
1. Content-Based Recommendation System-
A Content-Based Recommender System is one that follows a content-based filtration method to generate recommendations to the user. Content-Based filtration is mainly focused on recommending similar products to the user based on their history.
2. Collaborative Recommendation System-
A Collaborative Recommender System, on the other hand, does not take an individual user at a time but a cluster of similar or alike users (here, users with almost likely taste in movies), and based on those users’ ratings, recommends similar products to those group or cluster of users.
Tutorial Overview
In this article, we will develop a Content-Based Movie Recommendation System with the IMDB top 250 English Movies dataset.
Let us have a short overlook at what we will be covering-
1. Importing the Dependencies and Loading the Data
2. Text Preprocessing with NLP
3. Generating Word Representations using Bag Of Words
4. Vectorizing Words and Creating the Similarity Matrix
5. Training and Testing Our Recommendation Engine
Note – Before starting with this section, check if you have the dependencies installed! If not, create a file named ‘requirements.txt’ (in the same directory where you have your data and code) and paste the dependencies given below. Then open a fresh terminal, navigate to the target directory, and type in ‘pip install requirements.txt’. And there you go! You are ready for the project.
Dependencies –
1. pandas
2. numpy
3. sklearn
4. rake-nltk
So, let’s begin!
Importing the Dependencies and Loading the Data
So, let us begin by importing the necessary libraries first!
#ignore warnings import warnings warnings.simplefilter(action='ignore', category=FutureWarning) warnings.simplefilter(action='ignore', category=DeprecationWarning)#importsimport pandas as pdimport numpy as npfrom rake_nltk import Rakefrom sklearn.metrics.pairwise import cosine_similarityfrom sklearn.feature_extraction.text import CountVectorizer
Now let us load and print out our dataframe.
df = pd.read_csv('IMDB_Top250Engmovies2_OMDB_Detailed.csv')
df.head()Let’s have a quick overview of our dataset-
# data overview
print('Rows x Columns : ', df.shape[0], 'x', df.shape[1])
print('Features: ', df.columns.tolist())
print('nUnique values:')
print(df.nunique())
Output-
Rows x Columns : 250 x 5 Features: ['Title', 'Director', 'Actors', 'Plot', 'Genre'] Unique values: Title 250 Director 155 Actors 248 Plot 250 Genre 110 dtype: int64
Now, let’s check the missing values and print a short summary of statistics-
# type of entries, how many missing values/null fields
df.info()
print('nMissing values: ', df.isnull().sum().values.sum())
df.isnull().sum()
Output-
A short summary of statistics-
df.describe().T
Output-
So, let us now preprocess our data!
Text Preprocessing with NLP
Natural Language Processing techniques are our savior when we have to deal with textual data. Since our data cannot be fed to any machine-learning model unless we clean it, that’s where NLP comes to play!
Let’s clean our text data –
Firstly, let us create a new column in our dataframe that will hold all necessary keywords required for the model. We name it ‘Key_words’. Further, we use a very special NLP library known as RAKE (short for Rapid Automatic Keyword Extraction algorithm). RAKE is a keyword extraction algorithm that extracts those key phrases in a text corpus by determining the frequency of words and their relative occurrence with other words in the corpus.
Let’s implement it-
# to remove punctuations from Plot
df['Plot'] = df['Plot'].str.replace('[^ws]','')
# to extract key words from Plot to a list
df['Key_words'] = '' # initializing a new column
r = Rake() # using Rake to remove stop words
for index, row in df.iterrows():
r.extract_keywords_from_text(row['Plot']) # to extract key words
key_words_dict_scores = r.get_word_degrees() # to get dictionary with key words and their similarity scores
row['Key_words'] = list(key_words_dict_scores.keys()) # to assign it to new column
df
Let’s look at the keywords generated-
Next, we must make sure that our model is not confused with the actors and directors with similar first names, to be the same person. A lot of wrong recommendations can happen if it does so, and hence it needs to be feature engineered in such a way that the model can distinguish them as different entities. To do that, we simply need to merge the first names and surnames into one single word.
This will ensure the recommender detects a similarity only if the person associated with different movies is exactly the same-
# to extract all genre into a list, only the first three actors into a list, and all directors into a list
df['Genre'] = df['Genre'].map(lambda x: x.split(','))
df['Actors'] = df['Actors'].map(lambda x: x.split(',')[:3])
df['Director'] = df['Director'].map(lambda x: x.split(','))
# create unique names by merging firstname & surname into one word, & convert to lowercase
for index, row in df.iterrows():
row['Genre'] = [x.lower().replace(' ','') for x in row['Genre']]
row['Actors'] = [x.lower().replace(' ','') for x in row['Actors']]
row['Director'] = [x.lower().replace(' ','') for x in row['Director']]
Let’s now look at the ‘Directors’ and ‘Actors’ column-
Now we have unique identity values for each name.
Generating Word Representations using Bag of Words
BoW or Bag of Words is an Information Retrieval(IR) model which is useful for creating a representation of text, which describes the occurrence of words in a document or simply implies to us whether a particular word is frequent in the text corpus or not.
It is very useful for creating vector representations of frequent words in a corpus and then computing the similarity scores (what we will see shortly as ‘similarity matrix’.)
So, let us implement the BoW model-
# to combine 4 lists (4 columns) of key words into 1 sentence under Bag_of_words column
df['Bag_of_words'] = ''
columns = ['Genre', 'Director', 'Actors', 'Key_words']
for index, row in df.iterrows():
words = ''
for col in columns:
words += ' '.join(row[col]) + ' '
row['Bag_of_words'] = words
# strip white spaces infront and behind, replace multiple whitespaces (if any)
df['Bag_of_words'] = df['Bag_of_words'].str.strip().str.replace(' ', ' ').str.replace(' ', ' ')
df = df[['Title','Bag_of_words']]
Let’s look into our new column, ‘Bag_of_words’-
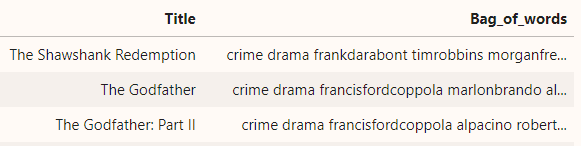
So our final input data to the model is now ready. But wait, a machine can only interpret numbers, not texts! Yes, you guessed it right; we need to vectorize our input now!
Vectorizing BoW and Creating the Similarity Matrix
Here, we will convert our BoW into vector representations with the help of much of a popular tool named Count Vectorizer. Count Vectorizer, gifted by our very own Scikit Learn library, converts words into their respective vector forms, on the basis of the frequency count of each word. Hence, the name, Count Vectorizer! Once the count vectorizer has done its job, and we have a matrix of all word counts, we will generate the similarity matrix with the help of cosine similarity.
Cosine similarity does a pretty straightforward high-school math! It measures the similarity between two vectors, by the cosine of the angle between them, and based on the value it gets, it decides whether the two vectors are moving in the same direction.
Let’s implement what we just discussed-
# to generate the count matrix count = CountVectorizer() count_matrix = count.fit_transform(df['Bag_of_words']) count_matrix
cosine_sim = cosine_similarity(count_matrix, count_matrix) print(cosine_sim)
Let’s examine the output-
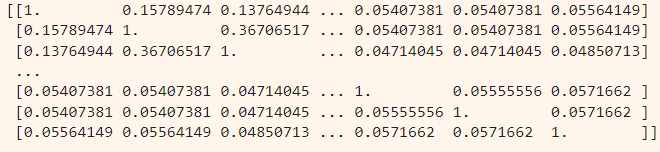
So, we have successfully computed our similarity matrix of 250 rows x 250 columns!
Now, let’s make sure that our Title column is well inclined with the row and column index of the similarity matrix.
indices = pd.Series(df['Title'])And we are now able to properly map the titles with the row and columns of our similarity matrix!
Training and Testing Our Recommendation Engine
Now that all the text-preprocessing and other NLP responsibilities are over, we will create a final method that will take a movie title as input, and returns the top 5 similar movies.
Steps involved in this method-
1. First, it takes in a movie title as user input.
2. Matches the input title with the respective index of the similarity matrix
3. Extracts the similarity values in the top to bottom or descending fashion
4. Extract (N+1) movies and remove the 1st one as it’s the user input itself
5. Give the Top N recommendations to the user
Let’s now implement it-
# this function takes in a movie title as input and returns the top 5 recommended (similar) movies
def recommend(title, cosine_sim = cosine_sim):
recommended_movies = []
idx = indices[indices == title].index[0] # to get the index of the movie title matching the input movie
score_series = pd.Series(cosine_sim[idx]).sort_values(ascending = False) # similarity scores in descending order
top_5_indices = list(score_series.iloc[1:6].index) # to get the indices of top 6 most similar movies
# [1:6] to exclude 0 (index 0 is the input movie itself)
for i in top_5_indices: # to append the titles of top 10 similar movies to the recommended_movies list
recommended_movies.append(list(df['Title'])[i])
return recommended_movies
recommend('The Avengers')
Now, let’s see what we got recommended-
['Avengers: Age of Ultron', 'Captain America: Civil War', 'The Incredible Hulk', 'Iron Man 3' 'Guardians of the Galaxy', ]
Great recommendations!
Conclusions
Congratulations on reaching the end of the blog and getting your movie recommender ready! I hope you had fun exploring how a recommender system works under the hood. I would suggest you try out this on your own with different data! Remember the more datasets you work with, the greater challenges you face.
All the best with that!
Read more articles on Recommendation Engine here.
The media shown in this article is not owned by Analytics Vidhya and are used at the Author’s discretion.
An ace multi-skilled programmer whose major area of work and interest lies in Software Development, Data Science, and Machine Learning. A proactive and detail-oriented individual who loves data storytelling, and is curious and passionate to solve complex value-oriented business problems with Data Science and Machine Learning to deliver robust machine learning pipelines that ensure maximum impact.
In my free time, I focus on creating Data Science and AI/ML content, providing 1:1 mentorships, career guidance and interview preparation tips, with a sole focus on teaching complex topics the easier way, to help people make a successful career transition to Data Science with the right skillset!




