This article was published as a part of the Data Science Blogathon.

Introduction
NLP or Natural Language Processing is one of the fastest-growing tech fields right now. From message spam filter to Medical diagnosis with a chatbot, NLP is everywhere. Some of the hot use cases of NLP right now are text summarization, chatbot, machine translation, text generation, etc.
Have you ever imagined getting a short summary of a big youtube tutorial or video for quick reading before watching the video, definitely this will help you to save a lot of your time by getting a quick understanding or summarization about the video in a short time. In this article, we are discussing a mini NLP project, a YouTube Summarizer which will summarize the content(subtitle) of the youtube video. For many videos, the main content of the videos is only 50-60% of the total length, so our youtube summarizer will summarize the content of the video by keeping all the important points and making it short and easily understandable. This will be useful in getting the summary of several lecture videos easily.
Let us understand the basics of the Mini NLP project.
First of all, let’s discuss what is summarization. Summarization is the technique of making short, understandable notes for a given large text document without excluding the important contents of the passage. There are 2 types of summarization in NLP, extractive summarization and abstractive summarization.
In extractive summarization, the system will extract the important paragraphs and contents from the given passage and combine these extracted paragraphs to create the summarized text.
In abstractive summarization, the system will create a summary based on the given passage with its own words. This is more complex than extractive summarization.
For our YouTube summarizer, we are using extractive summarization. For extractive summarization, we are using different summarization techniques like using BART or Bidirectional and Auto-Regressive Transformer, using TFIDF Vectorizer, etc.
Implementation
The basic structure of the youtube summarizer is that we are downloading the subtitles of the provided youtube video using the python module, Youtube-Transcript-API, and then performing the text preprocessing techniques and then finally doing different summarization algorithms for summarizing the given text.
So let’s import all the required libraries
import youtube_transcript_api from youtube_transcript_api import YouTubeTranscriptApi import nltk import re from nltk.corpus import stopwords import sklearn from sklearn.feature_extraction.text import TfidfVectorizer
The first step is to get the subtitles of the video that is to be summarized. For this, we are using the youtube_transcript_api module of python. For every youtube video, there will be a unique Id for it. For example, suppose the youtube link for a video is ” https://www.youtube.com/watch?v=WB-y7_yMPj4 “, the unique id will be ” WB-y7_yMPj4 “. We are using this unique Id to get the subtitle.
link = "https://www.youtube.com/watch?v=Y8Tko2YC5hA"
unique_id = link.split("=")[-1]
sub = YouTubeTranscriptApi.get_transcript(unique_id)
subtitle = " ".join([x['text'] for x in sub])
So we downloaded the subtitle using youtube_transcript_api. As we discussed earlier, in this article we are discussing 2 different text summarization algorithms. ie Using TF-IDF Vectorizer and using BART.
Summarization using TF-IDF vectorizer.
First, let’s discuss summarization using TF-IDF vectorizer.
TF-IDF or term frequency-inverse document frequency is a vectorizer that converts the text into a vector. It has 2 terms term frequency and inverse document frequency. TF-IDF value is the product of these 2 terms. Term frequency is the number of repetitions of words in a sentence by the total number of words in that sentence. Inverse document frequency is the log of no of sentences by the number of sentences containing the given word. So let’s start the implementation.
from nltk.tokenize import sent_tokenize
We are using sentence_tokenizer of nltk library for tokenization.
subtitle = subtitle.replace("n","")
sentences = sent_tokenize(subtitle)
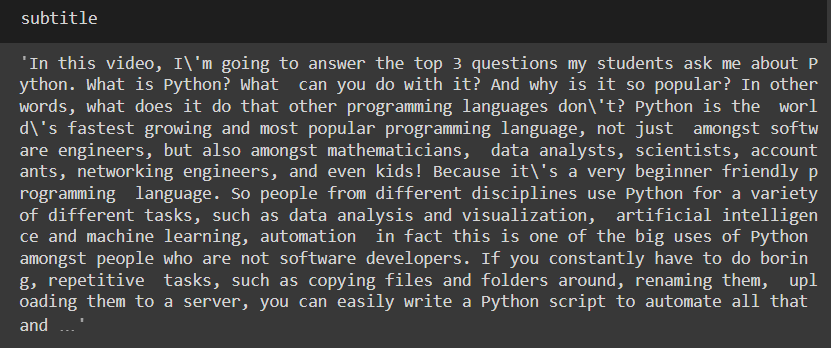
Now we are organizing the tokenized sentences into the dictionary with the sentence as the key and corresponding index to its value.
organized_sent = {k:v for v,k in enumerate(sentences)}
Next, we are using the tf-idf vectorizer, with the help of this we will get the scores of each sentence that we created during tokenization.
tf_idf = TfidfVectorizer(min_df=2,
strip_accents='unicode',
max_features=None,
lowercase = True,
token_pattern=r'w{1,}',
ngram_range=(1, 3),
use_idf=1,
smooth_idf=1,
sublinear_tf=1,
stop_words = 'english')
sentence_vectors = tf_idf.fit_transform(sentences) sent_scores = np.array(sentence_vectors.sum(axis=1)).ravel()
Now let’s find out the top N sentences that have a larger score.
N = 3 top_n_sentences = [sentences[index] for index in np.argsort(sent_scores, axis=0)[::-1][:N]]
Now let’s order the top sentences based on the order in the subtitles.
# mapping the scored sentences with their indexes as in the subtitle mapped_sentences = [(sentence,organized_sent[sentence]) for sentence in top_n_sentences] # Ordering the top-n sentences in their original order mapped_sentences = sorted(mapped_sentences, key = lambda x: x[1]) ordered_sentences = [element[0] for element in mapped_sentences] # joining the ordered sentence summary = " ".join(ordered_sentences)
Summarization using BART
BART(Bidirectional and Auto-Regressive Transformer) is a transformer that is now commonly used for sequence-to-sequence problems. Its architecture mainly consists of a Bidirectional encoder and a left-to-right decoder. BART is suitable for summarization, machine translation, question-answering, etc.
So let’s start the implementation. First, we are installing the transformers.
!pip install transformers
Let’s import the necessary libraries.
import transformers from transformers import BartTokenizer, BartForConditionalGeneration
Now let’s import the Bart pre-trained tokenizer and Bart pre-trained model for the summarization.
tokenizer = BartTokenizer.from_pretrained('facebook/bart-large-cnn')
model = BartForConditionalGeneration.from_pretrained('facebook/bart-large-cnn')
We have our subtitle downloaded in the first part of the article. Let’s encode this subtitle using the Bart Tokenizer.
input_tensor = tokenizer.encode( subtitle, return_tensors="pt", max_length=512)
Now let’s generate the output summarization using the Bart Summarization model.
outputs_tensor = model.generate(input_tensor, max_length=160, min_length=120, length_penalty=2.0, num_beams=4, early_stopping=True) outputs_tensor
The outputs will be a tensor in order to get text out of it, we need to decode it using the same Bart Tokenizer model.
print(tokenizer.decode(outputs_tensor[0]))
.png)
Summarization using BART will give pretty good results than TF-IDF vectorizer summarization. You can also fine-tune the BART for better results.
In addition, let’s try the summarization using transformers’ summarization pipeline.
So let’s import the pipeline from the transformer module.
from transformers import pipeline
We can set up the summarizer.
summarizer = pipeline('summarization')
Now let’s find the summary.
summary = summarizer(subtitle, max_length = 180, min_length = 30)
Image source: Colab
This is a low-level or basic implementation of the summarization model using transformers. Similar to BART, there are distilbart, BERT, GPT-2, etc which will give us a good accuracy summary.
Conclusion
In general, the Youtube summarizer will give us a brief summary of the video which will be useful for saving a lot of time(Note that, it is suitable for video with subtitles). I hope you liked this article and the mini NLP project. We can discuss interesting NLP projects in the coming articles.
Thank You!
Read more articles about NLP on our website.
The media shown in this article is not owned by Analytics Vidhya and are used at the Author’s discretion.
Python Developer, ML Enthusiast, Blogger and an Electronics and Communication Engineering aspirant determined and motivated to finish tasks with atmost sincerity and dedication.I'am a good learner who ready to accept challenges to bring up my best even in the worst. Wish for a world with enough advancements and opportunities for the people.




