This article was published as a part of the Data Science Blogathon.
Introduction
Natural Language Processing is a branch of artificial intelligence that deals with human language to make a system able to understand and respond to language. Data being the most important part of any data science project should always be represented in a way that helps easy understanding and modeling, especially when it comes to NLP machine learning. It is said that when we provide very good features to bad models and bad features to well-optimized models then bad models will perform far better than an optimized model. So in this article, we will study how features from text data can be extracted, and used in our NLP machine learning modeling process and why feature extraction from text is a bit difficult compared to other types of data.

Table of Contents
- Brief Introduction on Text Representation
- Why Feature Extraction from text is difficult?
- Common Terms you should know
- Techniques for Feature Extraction from text data
- One-Hot Encoding
- Bag of words Technique
- N-Grams
- TF-IDF
- End Notes
Introduction to Text Representation
The first question arises is what is Feature Extraction from the text? Feature Extraction is a general term that is also known as a text representation of text vectorization which is a process of converting text into numbers. we call vectorization because when text is converted in numbers it is in vector form.
Now the second question would be Why do we need feature extraction? So we know that machines can only understand numbers and to make machines able to identify language we need to convert it into numeric form.
Why Feature extraction from textual data is difficult?
If you ask any NLP practitioner or experienced data scientist then the answer will be yes that handling textual data is difficult? Now first let us compare text feature extraction with feature extraction in other types of data. So In an image dataset suppose digit recognition is where you have images of digits and the task is to predict the digit so in this image feature extraction is easy because images are already present in form of numbers(Pixels). If we talk about audio features, suppose emotion prediction from speech recognition so in this we have data in form of waveform signals where features can be extracted over some time Interval. But when I say I have a sentence and want to predict its sentiment How will you represent it in numbers? An image dataset, the speech dataset was the simple case but in a text data case, you have to think a little bit. In this article, we are going to study these techniques only.
Common Terms Used
These are common terms that we will use in further techniques so I want you to be familiar with these four basic terms
- Corpus(C) ~ The total number of combinations of words in the whole dataset is known as Corpus. In simple words concatenating all the text records of the dataset forms a corpus.
- Vocabulary(V) ~ a total number of distinct words which form your corpus is known as Vocabulary.
- Document(D) ~ There are multiple records in a dataset so a single record or review is referred to as a document.
- Word(W) ~ Words that are used in a document are known as Word.
Techniques for Feature Extraction
1 One-Hot Encoding
One hot encoding means converting words of your document in a V-dimension vector and by combining all this we get a single document so at the end we have a two-dimensional array. This technique is very intuitive means it is simple and you can code it yourself. This is only the advantage of One-Hot Encoding.
Now to perform all the techniques using python let us get to Jupyter notebook and create a sample dataframe of some sentences.
import numpy as np
import pandas as pd
sentences = ['Author writes on Analytics Vidhya', 'Vidhya reads and writes comment on Analytics Vidhya', 'Vidhya appreciates author']
df = pd.DataFrame({"text":sentences, "output":[1,1,0]})

Now we can perform one-hot encoding using sklearn pre-built class as well as you can implement it using python. After implementation, each sentence will have a different shape 2-D array as shown in below sample image of one sentence.

Disadvantages
1) Sparsity – You can see that only a single sentence creates a vector of n*m size where n is the length of sentence m is a number of unique words in a document and 80 percent of values in a vector is zero.
2) No fixed Size – Each document is of a different length which creates vectors of different sizes and cannot feed to the model.
3) Does not capture semantics – The core idea is we have to convert text into numbers by keeping in mind that the actual meaning of a sentence should be observed in numbers that are not seen in one-hot encoding.
2 Bag Of Words
It is one of the most used text vectorization techniques. It is mostly used in text classification tasks. Bag of words is a little bit similar to one-hot encoding where we enter each word as a binary value and in a Bag of words we keep a single row and entry the count of words in a document. So we create a vocabulary and for a single document, we enter one entry of which words occur how many times in a document. Let us get to IDE and implement Bag-of words model using the Count vectorized class of sciket-learn.
from sklearn.feature_extraction.text import CountVectorizer cv = CountVectorizer() bow = cv.fit_transform(df['text'])
Now to see the vocabulary and the vector it has created you can use the below code as shown in the below results image.
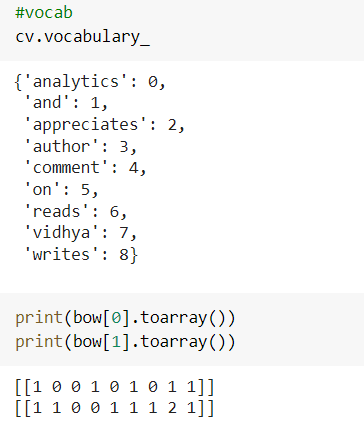
How it has been assigned the count is first it creates a vocabulary according to alphabetic order or words and then creates an array and check the count of occurrence of each term in a document and place that count at respective place in the array. Let us discuss the advantage and disadvantages of this technique.
Advantages
1) Simple and intuitive – Only a few lines of code are required to implement the technique.
2) Fix size vector – The problem which we saw in one-hot encoding where we are unable to feed data the data to machine learning model because each sentence forms a different size vector but here It ignores the new words and takes only words which are vocabulary so creates a vector of fix size.
Disadvantages
1) Out of vocabulary situation – It keeps count of vocabulary words so if new words come in a sentence it simply ignores it and tracks the count of the words that are in vocabulary. But what if the words it ignores are important in predicting the outcome so this is a disadvantage, only benefit is it does not throw an error.
2) Sparsity – when we have a large vocabulary, and the document contains a few repeated terms then it creates a sparse array.
3) Not considering ordering is an issue – It is difficult to estimate the semantics of the document.
3 N-Grams
The technique is similar to Bag of words. All the techniques till now we have read it is made up of a single word and we are not able to use them or utilize them for better understanding. So N-Gram technique solves this problem and constructs vocabulary with multiple words. When we built an N-gram technique we need to define like we want bigram, trigram, etc. So when you define N-gram and if it is not possible then it will throw an error. In our case, we cannot build after a 4 or 5-gram model. Let us try bigram and observe the outputs.
#Bigram model from sklearn.feature_extraction.text import CountVectorizer cv = CountVectorizer(ngram_range=[2,2]) bow = cv.fit_transform(df['text'])

You can try trigram with a range like [3,3] and try with N range so you get more clarification over the technique and try to transform a new document and observe how does it perform.
Advantages
1) Able to capture semantic meaning of the sentence – As we use Bigram or trigram then it takes a sequence of sentences which makes it easy for finding the word relationship.
2) Intuitive and easy to implement – implementation of N-Gram is straightforward with a little bit of modification in Bag of words.
Disadvantages
1) As we move from unigram to N-Gram then dimension of vector formation or vocabulary increases due to which it takes a little bit more time in computation and prediction
2) no solution for out of vocabulary terms – we do not have a way another than ignoring the new words in a new sentence.
4 TF-IDF (Term Frequency and Inverse Document Frequency)
Now the technique which we will study does not work in the same way as the above techniques. This technique gives different values(weightage) to each word in a document. The core idea of assigning weightage is the word that appears multiple time in a document but has a rare appearance in corpus then it is very important for that document so it gives more weightage to that word. This weightage is calculated by two terms known as TF and IDF. So for finding the weightage of any word we find TF and IDF and multiply both the terms.
Term Frequency(TF) – The number of occurrences of a word in a document divided by a total number of terms in a document is referred to as Term Frequency. For example, I have to find the Term frequency of people in the below sentence then it will be 1/5. It says how frequently a particular word occurs in a particular document.
People read on Analytics Vidhya
Inverse Document Frequency – Total number of documents in corpus divided by the total number of documents with term T in them and taking the log of a complete fraction is inverse document frequency. If we have a word that comes in all documents then the resultant output of the log is zero But in implementation sklearn uses a little bit different implementation because if it becomes zero then the contribution of the word is ignored so they add one in the resultant and because of which you can observe the values of TFIDF a bit high. If a word comes only a single time then IDF will be higher.
from sklearn.feature_extraction.text import TfidfVectorizer tfidf = TfidfVectorizer() tfidf.fit_transform(df['text']).toarray()

So one term keeps track of how frequently the term occurs while the other keeps track of how rarely the term occurs.
End Notes
We have read and performed hands-on machine learning techniques for feature extraction from text. These are techniques used when you go with machine learning modeling space. There are more advanced techniques that come under deep learning techniques for feature extraction from text like encoder-decoder, glove encoding, etc which is used when you use neural networks for NLP tasks and we will study all deep learning techniques in our next article.
I hope that it was easy to catch up with each technique we discussed in this article. If you have any doubts or feedback, feel free to share them in the comments section below, and you can connect with me.
Connect with me on Linkedin
Check out my other articles here and on Blogger
Thanks for giving your time!
The media shown in this article is not owned by Analytics Vidhya and are used at the Author’s discretion.
I am a software Engineer with a keen passion towards data science. I love to learn and explore different data-related techniques and technologies. Writing articles provide me with the skill of research and the ability to make others understand what I learned. I aspire to grow as a prominent data architect through my profession and technical content writing as a passion.







Your site, sir, is really good for a beginner like me Thank you very much