This article was published as a part of the Data Science Blogathon.
This is the 2nd blog of the MLOps series.
Introduction
This article is part of an ongoing blog series on Machine Learning Operations(MLOps).
In the previous article, we have gone through the introduction of MLOps. We have seen differences in traditional software development in deploying regular and ML-oriented applications. We also looked into some of the tools used by organizations for their operations—Link to the article.
MLOps Part 1: Revealing the Approach behind MLOps
This article will see the generic MLOps workflow from the start to the end. We will deep dive into them.
MLOps Workflow
Workflow is the sequence of tasks that repeats its process, occurring in a particular order.
This workflow can be used in any field or industry to build a proof of concept or operationalize ML solutions.
Workflow can be segmented into two modules:
1) MLOps pipeline – the upper layer
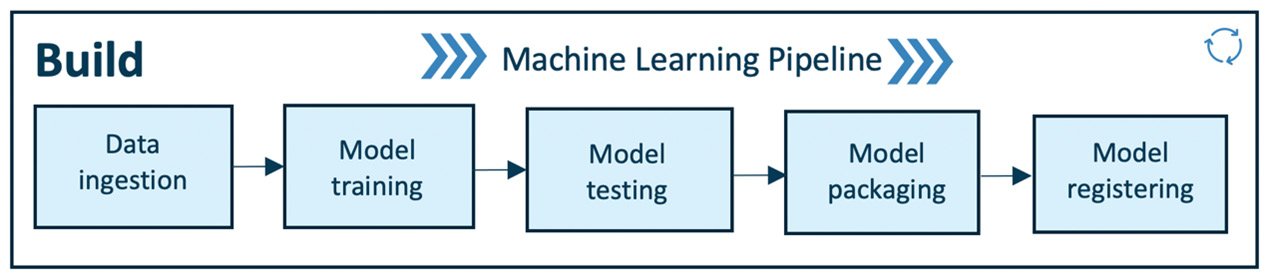
- Build
- Deploy
- Monitor
2) Drivers – Mid, Lower layer
- Data
- code
- Artefacts
- Middleware
- Infrastructure
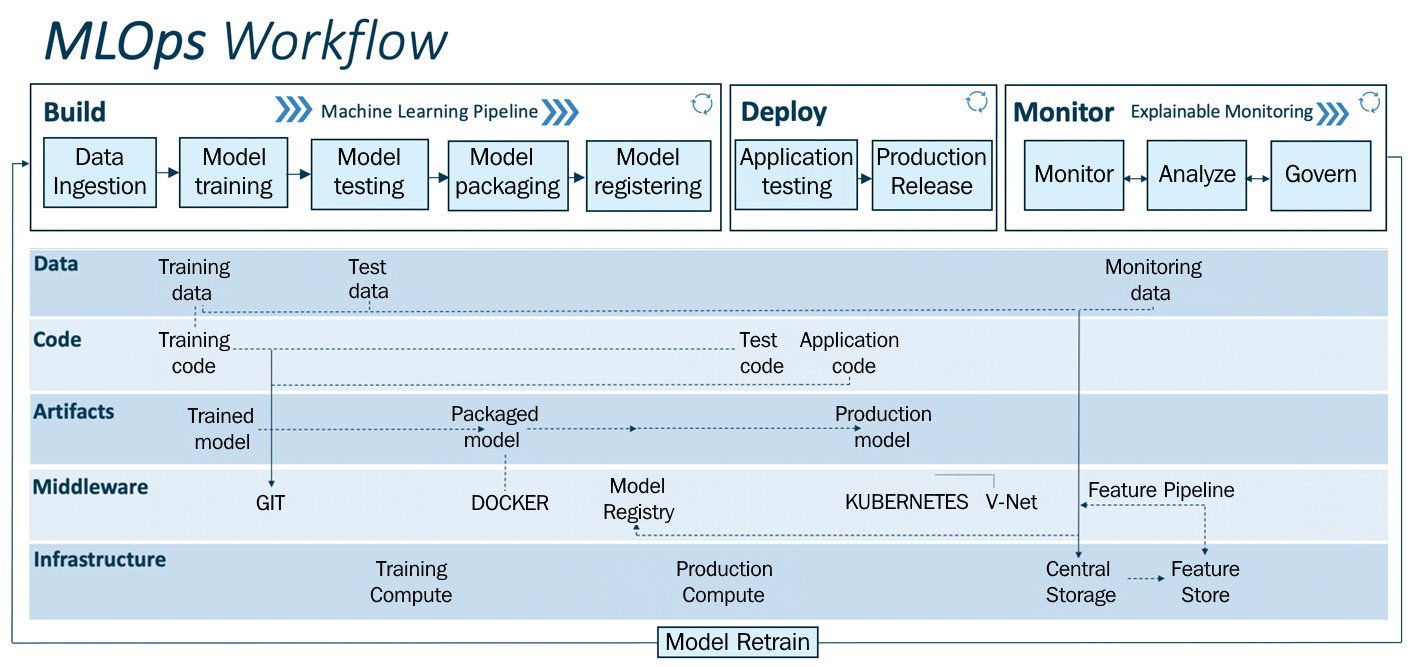
The upper layer is the MLOps pipeline which the Drivers enable. Using this pipeline, one can do quick prototyping, testing, validating and deploying models.
Let us have a detailed working of the modules.
The MLOps Pipeline
MLOps pipeline is the upper layer, and it performs operations such as build, deploy and monitor.
Build
This module is for training, packaging, and versioning the ML models.
Use Case:
Let us illustrate the workflow of MLOps with a use case.
We will operationalize(prototyping and deploying for production) an Image Classification service to classify cars and trucks in real-time from the CCTV camera installed on the highway.
Data: The highway authority has given you access to their data lake containing 100,000 labelled images of cars and trucks, which we will use for training the model.
The first step of the workflow is data ingestion.
- Data Ingestion
Data ingestion is the process of importing, gathering and storing data for immediate use or stored in a database for further use.
It deals with extracting data from various data sources(Example: database, data warehouse, data lake) and ingesting the required data for model training. The data may be of a different variety, different volumes, coming in with different velocities, with different veracities. The pipeline connected to the data sources performs ETL operations – Extract, Transform, Load.
Volume: Size of the data
Velocity: Speed of the incoming data
Veracity: How accurate the data is
Variety: Refers to different formats of data.
Data lake: It is a centralized repository for storing various forms of structured and unstructured data on a large scale.

Now, we have gathered the data. The collected data is split for training and testing purposes. These data are versioned so that any experiments can be back-traceable. We can keep track of this versioned data till the next cycle of data reaches the pipeline.
Use Case Implementation:
As we have access to the highway authority’s data lake, we can build the pipeline.
- Extract, Transform, Load 100,000 images of cars and trucks.
- Split and version the data into train and test split(Train-80%, Test-20%)
Model Training
After obtaining the required data for Machine Learning training in the ingestion step, now we will enable model training. It consists of modular code or scripts that perform all the traditional ML actions, including data preprocessing, data cleaning, feature engineering and feature scaling, standardizing, etc. After this, the model is trained on the preprocessed training data. It also performs hyperparameter tuning. This tuning can be done manually, but some efficient and automatic solutions such as Grid search or random Search methods are also available. This step gives the trained model as the output.
Use Case Implementation:
Here, we implement all the steps to train the image classification model.
The main goal is to prepare an ML model to classify cars and trucks.
We use a convolution neural network(CNN) for image classification.
Steps involved: data preprocessing, feature engineering, feature scaling, training the model with hyperparameter tuning. As a result, we have a CNN model to classify cars and trucks with 97% accuracy.
Model Testing
Now, we evaluate the trained model’s performance on test data separated and versioned during Data ingestion. This phase gives the performance output of the trained model, and a specific evaluation metric evaluates the arrangement as per the use case.
Use Case Implementation:
We have already segregated the test data during ingestion, and we have to test these data against the trained model and evaluate the performance. In this case of classification, we look for precision and recall scores to validate the model’s performance in classifying cars and trucks to assess false positives and true positives to get clarity in understanding the model’s performance. If we are satisfied with the results, we can proceed to the next step of the pipeline. Otherwise, we have to iterate the previous steps to get the model’s good performance for classifying cars and trucks.
Model Packaging
After testing the trained model, the model can be serialized into a file or containerized(using Docker) to be exported to the production environment. This helps to deploy the application without any dependencies error. This wraps the data and code together and packs the model.
Docker: Docker is an open-source containerizing platform. It enables us to pack the whole application into containers (i.e.,) executable components along with the source code, operating system libraries, dependencies required to run the code.
Use Case Implementation:
The CNN trained model for classifying cars and trucks is now packed into a container and kept ready for further processes.
Model Registering
Once the model is serialized or containerized in the Model packaging phase, that model is registered and stored in the model registry.
A registered model collects one or more files that assemble, represent and execute our model.
Example: A classification model may comprise a vectorizer, model weights, serialized model files, etc. All these files can be registered as a single model. After writing the model, it can be downloaded and deployed as needed in the production environment.
Use Case Implementation:
The serialized model for classification is registered in this phase, and it is available for rapid deployment into the highway vehicle classification production environment.
—————————————————————————————————————————————
As of now, we have executed the ML pipeline. Now the trained model is ready to be deployed in the production environment. In the next phase, we will look into the deployment pipeline.
EndNotes
In this article, we have explored the model building pipeline and seen a use case implementation for car and truck classification.
If you haven’t read the previous article, here is the link: MLOps Part 1
If you liked this article and want to know more, visit my other articles on Data Science and Machine Learning by clicking on the Link.
I hope you enjoyed the article and increased your knowledge. Please feel free to contact me at [email protected] Linkedin.
Read more articles on the blog.
The media shown in this article is not owned by Analytics Vidhya and are used at the Author’s discretion.
I am a Machine Learning professional with a strong background in Natural Language Processing (NLP). I am passionate about predictive modeling, data analysis, and deep learning, as they provide unique opportunities to uncover valuable insights from complex datasets.
Recently, my focus has been on Language Models (LLMs), an exciting area within NLP. I have been actively involved in researching, developing, and refining LLMs to enhance their capabilities and applicability in real-world scenarios. Through my work, I strive to advance the field of NLP and contribute to the development of intelligent systems that can understand and generate human-like language.
Sharing knowledge and collaborating with others is an essential part of my professional journey. I find great joy in exchanging ideas, insights, and expertise with fellow professionals and enthusiasts. By sharing my knowledge, I aim to contribute to the growth of the Machine Learning and NLP community, fostering an environment of continuous learning and innovation.







nice pair of articles. thank you