This article was published as a part of the Data Science Blogathon.
Overview
1. Introduction
2. What are recommendation engines?
3. Types of recommendation systems
a. Content-Based filtering
b. Collaborative filtering
c. Hybrid filtering
4. Why content-based filtering is not used on a large scale?
5. Recommendation engine algorithms
6. How to solve recommender system problems?
7. End-to-End product recommendation system
8. Application demo
9. EndNote
Introduction
In today’s world all humans need to transfer towards online, everything that is earlier easily available offlines now they are available online, online market. When we talk about business, is present most businesses run over the internet, in the other words we can say that this is the kind of business activity that happens over the internet.
What can we say about running an online business? Running an online business can include buying and selling or providing an online service. You will probably come across to purchase or sell any item online, what do you think first when you have to purchase anything online? it’s almost the eCommerce website, true! or when we have to watch a movie online either we download it or go for Netflix, Amazon Prime, etc… So, the point of view is that most of the businesses run on online platforms,

Source: Link
When we talk about these vital industries having a role in online marketing, here’s the customer satisfaction comes, why do customers are usually reaching these platforms? yes for their satisfaction with what they are looking for. You usually experience this when you go for purchasing anything from forex. Flipkart, you saw that the product you are looking for along with them there is recommended products too! We all know that the recommender system plays a vital role in many industries ranging from retail, E-commerce, and entertainment to food delivery, etc. This component is a de-facto standard for any business.
So, here we will discuss detailed recommendation systems or engines, how they import more on business, and at the end of the article we will implement on over the fashion product dataset.
So, firstly we will discuss the Recommendation system>>>
What are Recommendation Engines?
When you probably visit e-commerce or any other platform for a specific product, you are searching for the product and the products found, but at the time product found there are so many other different products are also associated with them, they are recommendations for that specific products. Now first you think about what is the term recommendations means? the term recommendations suggest that the look like or the products which are similar to that specific product that delivers to the user as to buy or looking for relative one. So in easy words, we can say that the system recommends you anything from your perspective.
In recent years recommendation engines gain more popularity and are utilized in a variety of areas and domains including movies, books, movies, social, etc… mostly used on the e-commerce sites like Amazon, Flipkart, etc…
In the machine learning language, the recommendation engine or system is the filtering system which is built using the machine learning algorithms which help to recommend the user perspective products based on several factors perspective.
Recommendation engines are the most important in the current e-commerce scenario, these engines or systems have a major contribution to the growth of e-commerce and other industries. A recommendation engine helps to address the challenges faced in the e-commerce space, it helps in the user interaction with the platform it saves the browsing time for the users or customers. Its personalization feature improves customer engagement and reservation.
Example:
Considered an example of the recommendation engine used by any eCommerce site, Flipkart, you mostly visit the Flipkart in your life at once!! so when you search for a particular product in the search bar, you probably encounter the scenario that along with the search result there is a recommendation of the search product also displayed, these recommendations are generated with our search data.
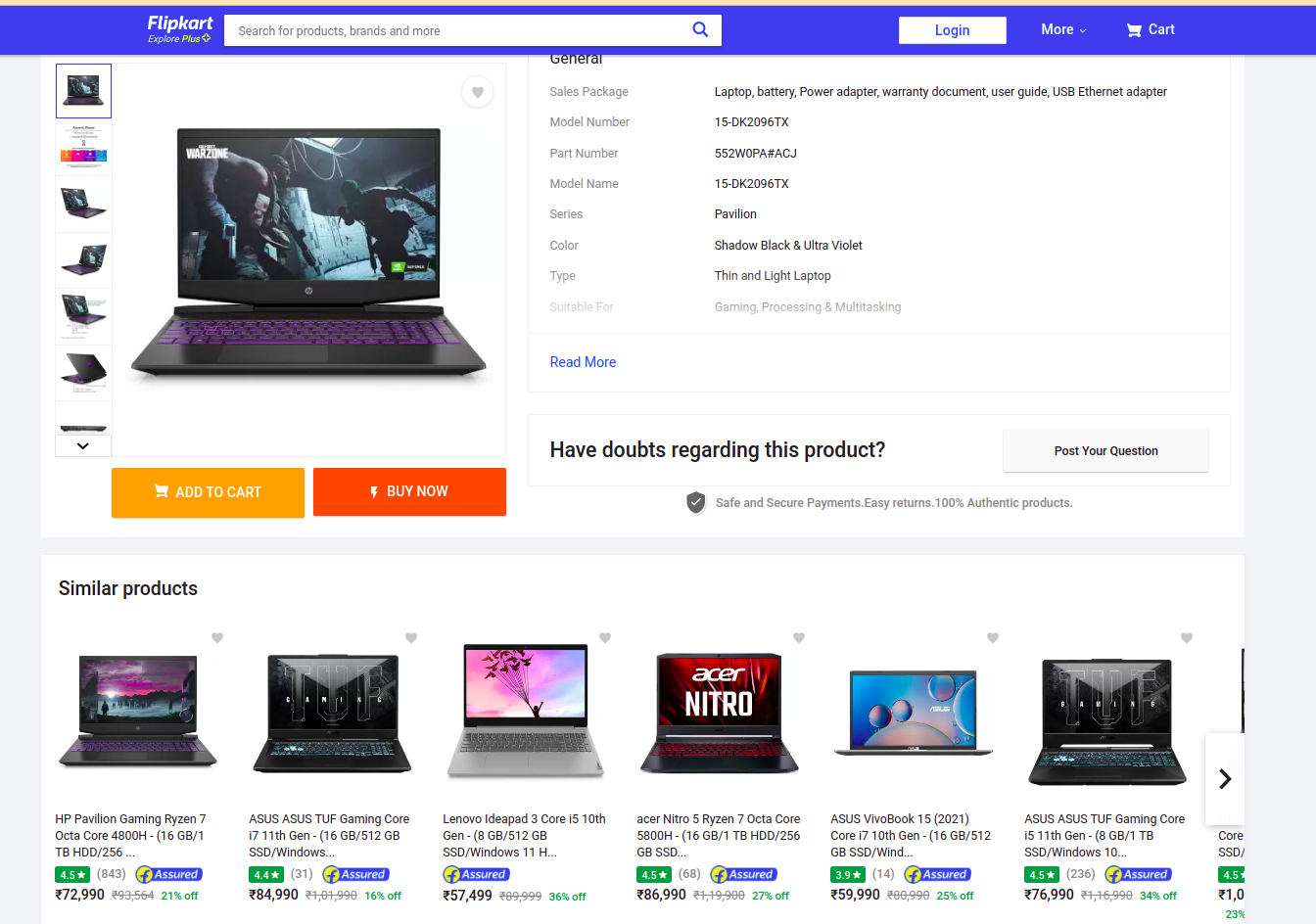
As you see in the image, we search for a laptop along with that laptop there is similar product is also displayed, those product data and details are quite similar to our search product. So this means that the recommendation engines are built in such a way that they will use the user data or product data for the recommendations. This recommendation has a goal that is to increase the order value of the product. to up-sell and cross-sell customers by providing product suggestions based on the items in their shopping cart or below products they’re currently looking at online.
As we talk about the recommendation engines using the data to recommend the product, this data is collected from different sources. so let’s talk about it in detail…
Types of Recommendation Engines
There are mainly three types of recommendation systems, mostly used in the industries. many other engines are developed by the companies for their uses but the core is these three types:
1. Content-Based filtering recommendation system.
2. Collaborative filtering recommendation system.
3. Hybrid recommendation system.
Let’s discuss all of this in detail…
Content-Based Filtering
Apart from today’s world we talk about earlier the recommendation systems are mainly based on the content-based filtering system, there is no advancement in the algorithm for better recommendations. when we talk about content-based filtering this is a simple filtering system that uses the data of the user and on the observations from the data that proposed recommendations.
In easy words, we can say that this filtering is based on the description of an item and a profile of the user’s choices. This filtering system tries to establish a relation between the user and item, besides, a user profile is built to state the type of item this user likes. A user likes the product, then the recommendation is based on the description of the product, which means this type of feature that the user wants in the respective product. This approach has its roots in information retrieval and information filtering.
It is simply Item-User based filtering system, let’s see the mathematical structure of content-based filtering…
A content-based recommendation engine, represent Item (Ij) and User (Uj)>>
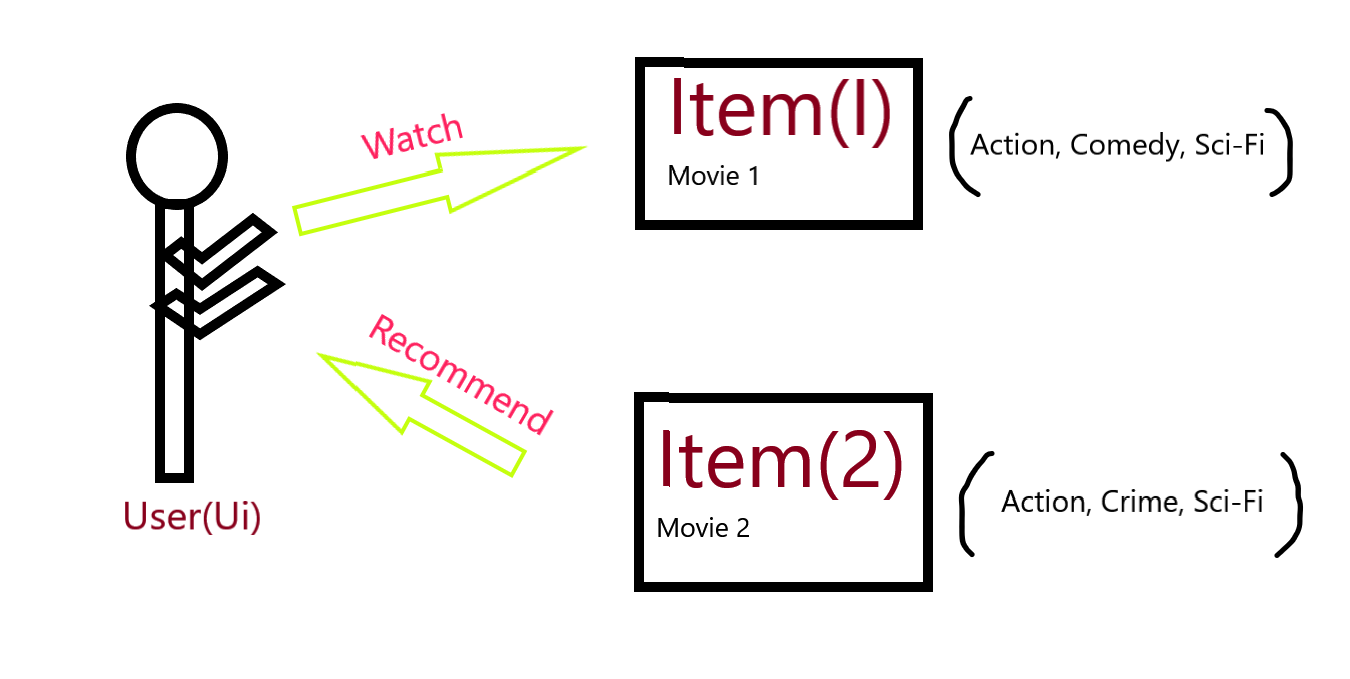
Example:
Let’s take an example for easy understanding, take movie I which is an action, drama, and sci-fi type movie this is watched by a user, there is another movie with the type of action, crime and sci-fi type this movie is recommended to the user to watch because the content is so similar of both the movie.
Why Content-Based Filtering is not used on a Large Scale?
A major problem or issue with content-based filtering is the system learns from the user’s actions or preferences from one content and reflects all other content that the user uses. Suppose a user already using the same content in 5 of 10 products, so there is no change in the other 5 content because the system or engine does not have valuable information which can recommend new content to the user. The value from the recommendation system is significantly less when any other content types from any other services can be recommended. There is no other new variety of content for the user to recommend.
An easy example of this is supposed, a song that is romantic and sad this type of content is similarly applicable for all other songs you listen to if you want to listen to chill songs, but this system can be able to recommend you this.
How to identify the problem is specific to content-based recommendations?
Content-based engines are completed in the following cases or phases…
1. There is a single user is present in the data. User(i), the consumer of the content.
2. There is a list of items or contents in the dataset, like music, videos, articles, blogs, etc…
3. A user-perceived value of an item is present, such as ratings, behaviour, etc…
4. The component definitions and the algorithms used for the recommendation.
Collaborative Filtering
Above we discussed the heuristic and simple approach for the recommendation of the content. The major problem with the above engine is that it does not recommend the new test of the product to the user, new test refers to something different apart from the user scenarios. To overcome this big problem there is new filtering method is discovered, which helps users to explore content apart from their preferences and priorities.
So, collaborative filtering is the method in which the machine learning system identifies the two users’ behaviour, activities, and preferences and uses them in proportion to recommend the products or items. In simple words, we can say that this filtering method gathers the information and take look into data on user behaviour, conceptional activities, and preferences to predict what they will like based on the similarities with the other user. To make it more simple this filtering system automatically predicts the interest of a user by collecting taste information from many users.
Example:
Let’s take an example to demonstrate the working of collaborative filtering based recommendation system:
We take an example of a movie recommendation system that recommends the movie with a collaborative filtering approach, let’s suppose we have multiple users, we have user1 who likes and watch movie1, movie2, and movie3, imagine there is user2 who likes movie2, movie3, and movie4, let there be a user3 who likes movie1 and our job is nothing but we have to recommend the next new movie to user3 on the data we have from user1 and user2.
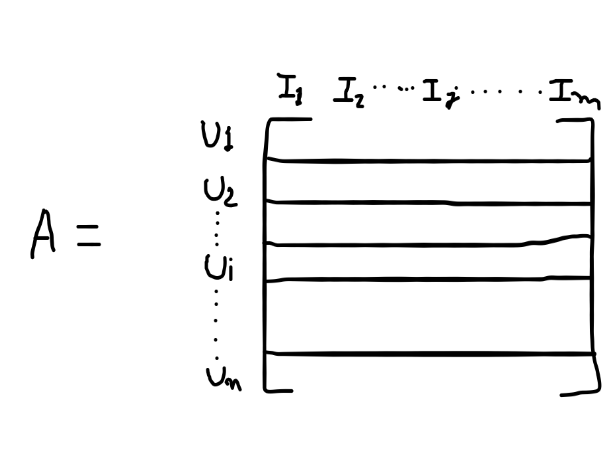
So, this is nothing but this is a matrix representation of the data that we collect from the users, let’s all this information be available in matrix A, where we have a rating of user I for movie j. What happens now we know that all the user’s tastes and preferences, as we compare the user3 with user1 and user2, we observe that both the users like movie1 which is very similar to the taste the user3 has since user3 also likes movie1, and user1 and user2 both of them like movie3 here, so there is a very high chance the new movie recommend to user3 is movie3. The core idea about this is that users who agreed in the past was tends to also agree in the future.
Hybrid Recommendation Engines
After working with both approaches this is the approach in which the machine learning model is trained in such a way that it has both the functionality of content-based and collaborative filtering approaches. The above two approaches have their problem for a recommendation, this method faces the problem when there is less amount or not enough data to learn the relation between users and items. To overcome this issue there is hybrid approach is discovered, in this approach, we add the power of content and collaborative filtering.
The hybrid recommendation system is a special type of system that used data of both collaborative data and content-based data simultaneously which helps to suggest a similar or close item to the users. Combining the two above approaches helps to resolve the big problems in more effective cases sometimes. In this, the system suggests similar items which are already used by the user or suggests the items which are likely to be used by another user with some similarities.
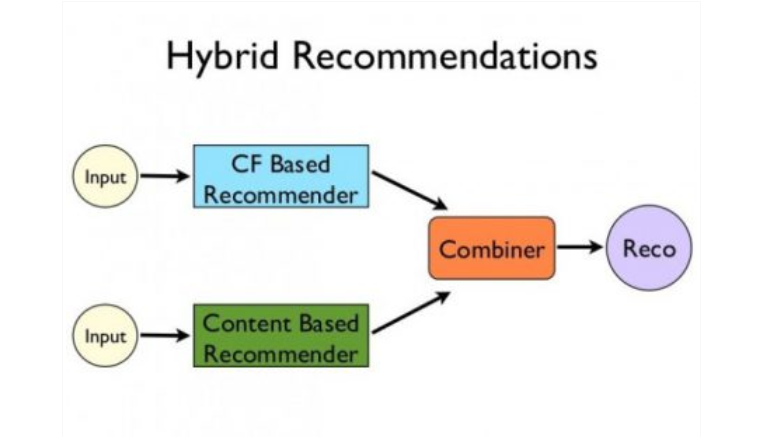
Source link: here
As you see in the image we separate put input to both the recommender systems and their predictions are combined in the last to make a hybrid system. There are several observations that when we compare the above heuristic approaches with the hybrid approach we found that hybrid systems are more effective them both of them, hybrid systems give better recommendations.
Above this are the approaches, below we discuss the algorithms which are mostly used for building recommendation engines.
Recommendation Engines Algorithms
Some of the simplest recommender system algorithms we design or build are called similarities based algorithms, It means there are certain factors similarities are recommended items to the users. There are broadly two types of similarities we always used to build the recommendation system.
1. User-User based similarities
2. Item-Item based similarities
User-User Based Similarities
The logic behind the user-user-based similarities is simple, the product is recommended to the user based on ratings the user gives and the ratings given by another user.
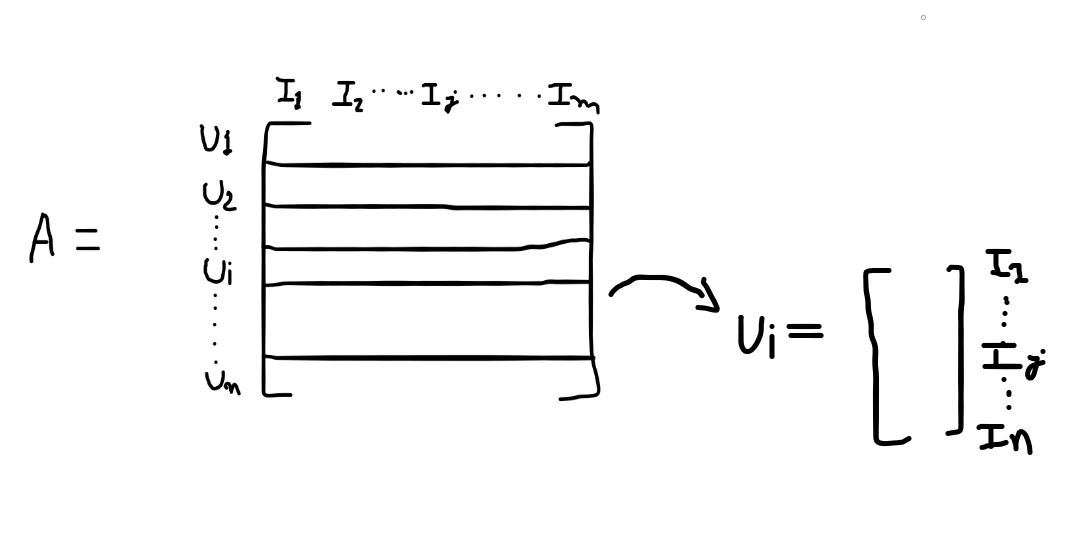
We have a matrix A where we have user1 to userN, there are such N users are present, similarly, there are N items are present in each user block. So let us take a vector from the matrix Ui, we write it as a column vector as simplicity, In this vector, the first cell will be the ratings given by Ui to item1, Ui to item2, and so on to itemM. This vector Ui is thought of as a user vector which is a sparse vector.

So we can define the similarity between the user I and J as cosine similarities as you see in the above image, using these user vectors we can compute the similarity values of users, we name as Sij(similarities of user i and j)
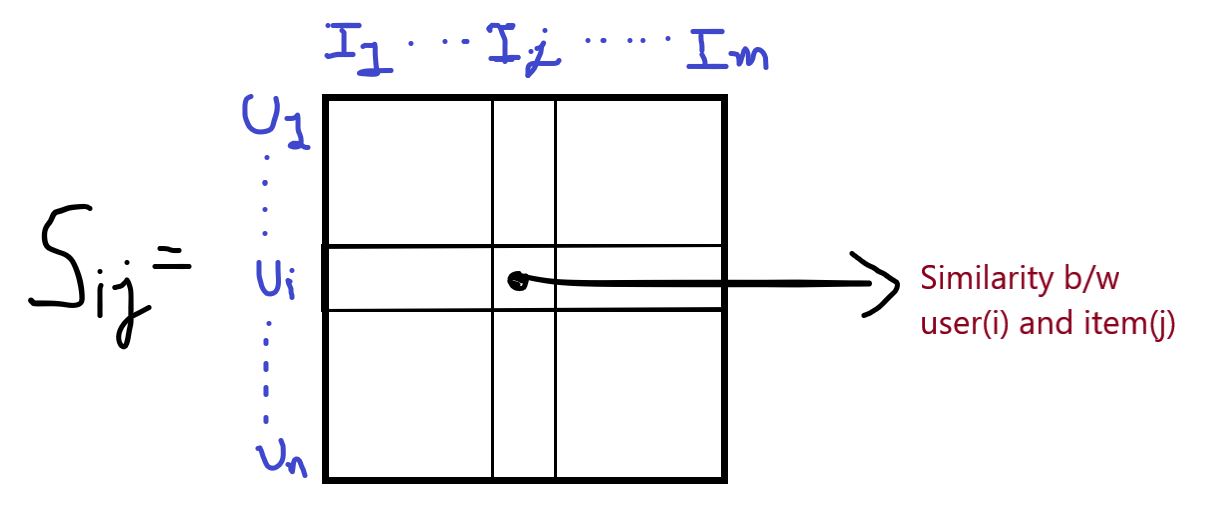
Suppose you have to recommend a product to user10, so we look at the similarity matrix and find the large values because a larger value means more similar. if we say that U1, U2, and U4 have the largest similarities with the U10, the engine will recommend the product to U10 which is similar in all their other users and not used by U10.
The problem with the user_user system is that the user preferences are changed over time.
So the alternative approach is discovered which is item-item-based similarities. let’s see below…
Item-Item Based Similarities
Item-Item similarities algorithm is popularised by amazon in 1998 or early in 2001. it is nothing but simply the popularity-based algorithm between items, it is a form of a collaborative approach on the similarities between items, which was calculated by the user’s preferences and data.
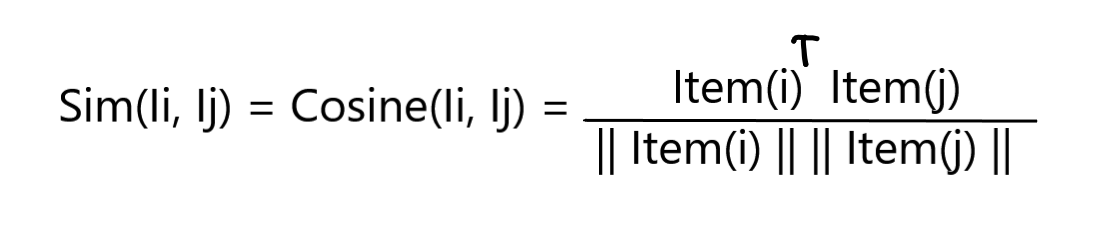
Here we will represent each item as a vector and this vector is obtained from matrix A, which consists of items, vector i, and j, we take these vectors from the matrix
item-item models resolve these problems in systems that have more users rather than items. item-item models use eating distributions per item, not per user. with more users than items, each item tends to have more ratings than reach user, so an item average rating usually doesn’t change quickly. This leads to more stable rating distributions in the model, so the model doesn’t have to be rebuilt as often. When users consume and then rate an item, that item’s similar items are picked from the existing model and added to the user’s recommendations.
How to Solve Recommendation Engines Problem?
So the Matrix Factorization is used to solve the recommender system problems, before we go ahead we need to take an understanding of what is matrix factorization and then connect it with a recommender system.
The objective of matrix factorization is that suppose we have given a matrix A if somehow we decompose this matrix into the product of another matrix such as B, C, and D(metrics). So the core idea of matrix factorization is that given a matrix A, we have to decompose into a product of two or more matrics.
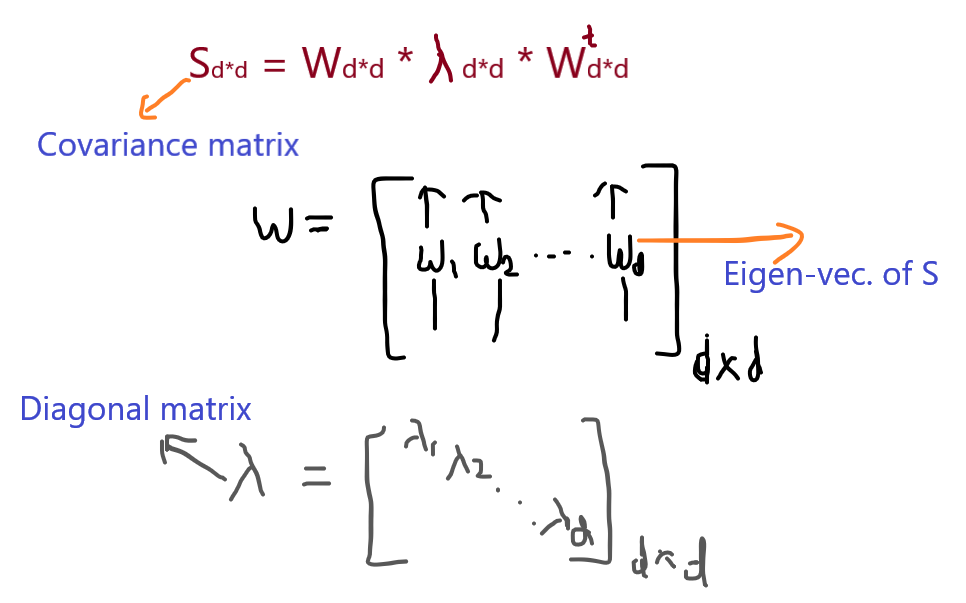
First of all, we have to compute the covariance matrix of data matrix A, then this covariance matrix Sd*d can be decomposed as a product of three matrics such that the first matrix is formed by the eigenvalues of our covariance matrix, the second matrix is the diagonal matrix formed by the eigenvalues of S and the third matrix is the transpose of the first matrix. This all decomposition is referred to as eigendecomposition of S.
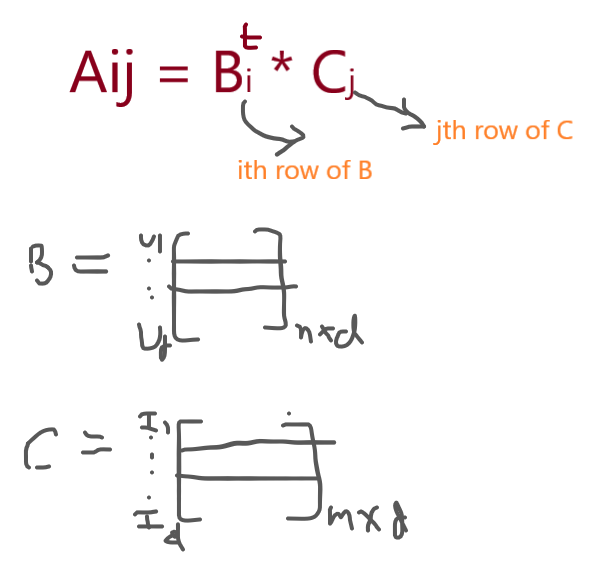
So, imagine we have a matrix A contains ratings between user I and item J (Aij), and this is a very sparse matrix with many empty shells, so somehow we decompose this matrix into a product of two matrics such as B*Ct s, Then the Aij is the product of an ith row of B matrix and a jth row of c matrix, so we predict the values by the existing values to solve the recommendation problem. Easy words, we decompose the matrix into parts in a way that when we do the product of these parts this will generate the original matrix.
End to End Product Recommendation Engines Using Deep Learning
This all is about the theory on recommendation system, but of the particle, we need to take a practical example.
So, let’s take an example of a fashion product recommendation system in which we recommend similar types of products to the user they prefer. It is the item-item similarity recommendation system approach, here we will take a detailed discussion on it below…
The concept of this project is that a user gives an image of the product to the system, in response the system recommends the 5 most similar items with the product. For example, you have already used google lens, when you search with a photo then google responds the similar photos with that photos, so this is the concept we are using here. We are using the deep learning model ResNet50 which is pre-trained on imagenet dataset.
So, let’s start>>>>
Load Dataset
So the first step of building the recommendation system model is we have to collect the data first, there are multiple methods for collecting data, here we download data from Kaggle.
Dataset link: click_here
This dataset consists of almost 45000 images, these images are of clothing fashion accessories and have JSON files of styles, which point to each image id. Each product is identified by an ID like 42431. You will find a map to all the products in style.csv, from here you can fetch the image for this product from images/42431.jpg and the complete metadata from styles/42431.json.
The next step is importing important libraries,
Note: This recommender system is solved using a machine learning approach, but here we are using a deep learning approach to solve this problem. If you have a basic understanding of deep learning that’s great, if not then you must study the basic prerequisites of deep learning. Go for this prerequisite:
1. CNN
2. Transfer learning => ResNET50
Importing Modules
In this step, we import all the libraries which are used for the further processes.
import pandas as pd import numpy as np import tensorflow import tensorflow.keras as tf from tensorflow.keras.preprocessing import image from tensorflow.keras.layers import GlobalMaxPooling2D from tensorflow.keras.applications.resnet50 import ResNet50, preprocess_input from numpy.linalg import norm import os from PIL import Image import pickle from sklearn.neighbors import NearestNeighbors
Here we are importing Numpy, Pandas, Numpy is used for adding large multi-dimensional arrays and matrices, and Pandas is used for loading the data and other data-related works. Tensorflow focuses on the training and inference of deep neural nets. Keras is used as an interface for TensorFlow. Sklearn has supported all machine learning algorithms. Here we are importing all the important deep learning models such as resnet50, GlobalMaxPooling2D layer, preprocess_input this are used for developing our deep learning model for recommendations. Here NearestNeighbors algorithm is used for finding all the nearest items to our existing items from the dataset.
In the next step, we are moving forward towards importing our ResNET50 model, this model is used for training and testing of our data.
Import Model
In this step we are loading the convolutional neural network model, the name of this model is ResNet. Let’s take a brief understanding of the ResNet model. This model is created by the well knows data scientist, this model is very accurate, it is already trained on the most famous dataset which is known as ImageNet. This is high performing model its accuracy is high.
If we are not using this model in place there is another option which is we create our own CNN model and train on our data, there are two main problems faced when we do this is training time is so high and our accuracy is not matchable to ResNet model.
# our resent model is pre-trained on the imagenet dataset,
# so we have to use this resnet model for the feature extraction
# create a model variable
# we are not including the top layer in our model
model = ResNet50(include_top = False, weights='imagenet',input_shape=(224,224,3))
# we don't have to train the model
model.trainable = False
model = tensorflow.keras.Sequential([
model,
# we add our own layer
GlobalMaxPooling2D()
])
# this gives the summary of our resnet model
print(model.summary)
Output:
We create a new variable model here we initialized our ResNet50 model, which is 50 layers neural net, we update the model with one more layer which is GlobalMaxPooling2D. At last, we print the summary of our model.
The main Question is arise if this model is pre-trained then why do we use this model? For this, we go for our next step>>>>
Extract Features
Why we are using because We are using this CNN ResNet model for extraction of the features from the dataset, What is the mean of feature extraction here? suppose we have 44k images and we have 1 image, we have to compare this 1 image with 44k images. In these 44k images which are 5 closest to our given image is our recommendation, So we have to analyze these 44k images for this we do feature extraction. Features refer to the parts or patterns of an object in an image that helps to identify it. For example, the image of the classroom consists of a duster, blackboard, tables, etc… these are the features of the image.
Here is the code for feature extraction…
# Make a function which extract the feature from image
# we combine all the steps that perform above
def extract_feature(image_path, model):
imag = image.load_img(image_path, target_size=(224, 224))
imag_array = image.img_to_array(imag)
# we have to expand the dimensions of the image array,
# because keras accept the batch of the images
image_expand = np.expand_dims(imag_array, axis=0)
# using preprocess_input, which convert the image input array into resnet considerable manner
processed_image = preprocess_input(image_expand)
result = model.predict(processed_image).flatten()
norm_result = result / np.linalg.norm(result)
return norm_result
filenames = []
for file in os.listdir(‘Path of the Images’):
filenames.append(os.path.join(‘Path of the Images’,file))
features_list = []
for files in tqdm(filenames):
features_list.append(extract_feature(files,model))
# this files used in the recommendation while testing
pickle.dump(features_list,open(’embiddings.pkl’,’wb’))
pickle.dump(filenames,open(‘filenames.pkl’,’wb’))
return norm_result
# create a list of filenames with the required path
# create a list of features name
# we will use this list of filenames and features so we make a pickle file of both
Here we create a function named extract_features which helps to extract features from the given image, in this function we perform several; operations such as loading the image then we converted it into an array, then we expand or reshape the array into (1, 225,225, 3) shape then we flatten the expanded an array. At last, we return the normalized array.
The filenames and this normalized array result are stored in a formal list. At last, we save our files with the information of filename and features vectors using pickle.
Creating New Python File For Testing
Now we create a new python file named Test.py in which we are testing our model on test data.
Test.py
First, we have to import those pickle files.
feature_list = pickle.load(open('embiddings.pkl','rb'))
filenames = pickle.load(open('filenames.pkl','rb'))
In this python file, we load our saved files using pickle. and we import a test image for testing purposes. We repeat all the above exact steps, but we conclude it for the only testing image.
model = ResNet50(include_top = False, weights='imagenet',input_shape=(224,224,3))
# we don't have to train the model
model.trainable = False
model = tensorflow.keras.Sequential([
model,
# we add our own layer
GlobalMaxPooling2D()
])
# we create a function which extract the features from image
def extract_function(model, image_path):
imag = image.load_img(image_path, target_size=(224, 224))
imag_array = image.img_to_array(imag)
imag_expand = np.expand_dims(imag_array,axis=0)
processed_image = preprocess_input(imag_expand)
result = model.predict(processed_image).flatten()
result_norm = result/norm(result)
return result_norm
Here we will perform all the same operations, for the single image only because we have to find the similarity between the given image and the trained images.
Now we have to find the similarities between this new norm_results and our pre-trained images.
Distance Calculation Using NearestNeighbor
We have to calculate the distance b/w our single image vector and the features_files data. After then our NearestNeighbor algorithm finds the 5 nearest neighbours of the given image.
def recommend(features_list, feature):
neighbor = NearestNeighbors(n_neighbors=5, algorithm='brute', metric='cosine')
neighbor.fit(features_list)
distance, index = neighbor.kneighbors([feature])
return index
We created a function that recommends the 5 nearest or similar items related to a given image. the distance metric we are using is cosine which is used for finding the cosine distance b/w vectors. And this function returns the index of all the recommended images.
As we are creating an end-to-end project so, now we are using a streamlit python library for creating a GUI interface.
Streamlit GUI Interface
Before moving further we take a brief discussion on what is streamlit? A streamlit is a python open-source library, which makes it easy to create and share interactive custom web apps for machine learning and data science models. With the use of streamlit, we can easily build an app and make interactions with users.
More about streamlit: click_here
Here is the code for creating a GUI interface using streamlit
# importing streamlit
import streamlit
if __name__ =='__main__':
# steps
# upload image
# load image
# extract features from uploaded file
# recommend 5 images same as uploaded image....
streamlit.sidebar.title('Fashion Recommender')
file = streamlit.sidebar.file_uploader('')
if file is not None:
if save_file(file):
# display image
i = Image.open(file)
streamlit.image(i,width=400)
feature = extract_function(model,os.path.join('uploaded',file.name))
index = recommend(features_list,feature)
print(index)
data_json = fetching_json(index[0][0])
#create a columns for each image recommendation
for each_index in index:
col1, col2, col3, col4, col5 = streamlit.columns(5)
with col1:
print(each_index[0])
streamlit.image(filenames[each_index[0]],caption=data_json['data']['productDisplayName']) #image1
with col2:
streamlit.image(filenames[each_index[1]]) #image2
with col3:
streamlit.image(filenames[each_index[2]]) #image3
with col4:
streamlit.image(filenames[each_index[3]]) #image4
with col5:
streamlit.image(filenames[each_index[4]]) #image5
First, we import the streamlit library, then we use those functions which is created by us, which tasks image id and features_list as a parameter. then by using streamlit inbuild functions we make a GUI interface.
Application Demo
This project is also available on Github: Fashion_product_recommender
Here is the demo of our created application, it is a full end-to-end application we browse an image from the system and give it to the model then the model will display 5 similar images with the given image.
.gif)
Above is the output of the following project that we have built above.
Conclusion
So, this was all about the recommendation engines, here discussed in detail of recommendation engines, How they build, what algorithms where we used and also create an end to end product recommendation system using streamlit.
I hope you like this article, I wich this article is helpful for you. Thank you for reading this article on recommendation engines, investing your valuable time into my article.
Connect with me on LinkedIn: Mayur_badole.
Read our latest articles on the website.
Thank You.
The media shown in this article is not owned by Analytics Vidhya and are used at the Author’s discretion.







{kind=link}
How do we recommend newly-released content using user-user collaborative filtering?