This article was published as a part of the Data Science Blogathon.
One of the important use cases of Natural Language Processing (NLP) is generative text. Generative text is predicting what word must come next in a sentence. Applications of generative text are question-answering chatbots, sentence or word autocorrection, and autocompletion, grammar check, and these cases have now become indispensable and part of our day-to-day lives.
To help us know what word will come next we need to learn as much as we can what words previously came in a sentence. To fulfil this need and to understand what words came priorly is where parts of speech and syntactic parsing are very important and integral topics in NLP.

Language Syntax
The language syntax is fundamental for generative text and sets the foundation for parts of speech and parse trees.
The word syntax originates from the Greek word syntaxis, meaning “arrangement”, and refers to how the words are arranged together. Henceforth, language syntax means how the language is structured or arranged.
How are words arranged together?
There are many different ways to categorize these structures or arrangements. One way to classify how the words are arranged is by grouping them as the words behave as a single unit or phrase, which is also known as a constituent.
A sentence can have different language rules applied to it and have different types of structure. As different parts of the sentence are based on different parts of the syntax that follow the same grammar rules that are of a noun phrase, verb phrase, and prepositional phrase.
A sentence is structured as follows:
Sentence = S = Noun Phrase + Verb Phrase + Preposition Phrase
S = NP + VP + PP
The different word groups that exist according to English grammar rules are:
- Noun Phrase(NP): Determiner + Nominal Nouns = DET + Nominal
- Verb Phrase (VP): Verb + range of combinations
- Prepositional Phrase (PP): Preposition + Noun Phrase = P + NP
We can make different forms and structures versions of the noun phrase, verb phrase, and prepositional phrase and join in a sentence.
For instance, let us see a sentence: The boy ate the pancakes. This sentence has the following structure:
- The boy: Noun Phrase
- ate: Verb
- the pancakes: Noun Phrase (Determiner + Noun)
This sentence is correct both structurally and contextually.
However, now taking another sentence: The boy ate the pancakes under the door.
- The boy: Noun Phrase
- ate: Verb
- the pancakes: Noun Phrase (Determiner + Noun)
- under: preposition
- the door: Noun Phrase (Determiner + Noun)
Here, the preposition under is followed by the noun phrase the door, which is syntactically correct but not correct contextually.
Taking the same sentence in another way: The boy ate the pancakes from the jumping table.
- The boy: Noun Phrase
- ate: Verb
- the pancakes: Noun Phrase (Determiner + Noun)
- from: preposition
- jumping table: Verb Phrase
This sentence is syntactically incorrect as the preposition form is followed by a verb phrase jumping table.
Components of Text Syntactic
There are two imperative attributes of text syntactic: Part of Speech tags and Dependency Grammar.
Part of Speech tagging or POS tagging specifies the property or attribute of the word or token. Each word in a sentence is associated with a part of speech tag such as nouns, verbs, adjectives, adverbs. The POS tags define the usage and function of a word in the sentence.
Why do we need a dependency tree when POS tagging exists?
The part of speech only tags individual words and not phrases, hence it is not sufficient to create a parse tree. Parse trees are where we tag the phrases as noun Phrase, verb phrase, or prepositional phrase and it needs to be in that particular order.
Parsing essentially means how to assign a structure to a sequence of text. Syntactic parsing involves the analysis of words in the sentence for grammar and their arrangement in a manner that shows the relationships among the words.
Dependency grammar is a segment of syntactic text analysis. It determines the relationship among the words in a sentence. Each of these relationships is represented in the form of a triplet: relation, governor, and dependent. As a result of recursively parsing the observed relationship between the words is represented in a top-down manner and depicted as a tree, which is known as the dependency tree.
These grammar relations can be used as features for many NLP problems such as entity-wise sentiment analysis, entity identification, and text classification.
For example: let’s visually represent the sentence “Bills on ports and immigration were submitted by Senator Brownback, Republican of Kansas.” as a dependency tree:
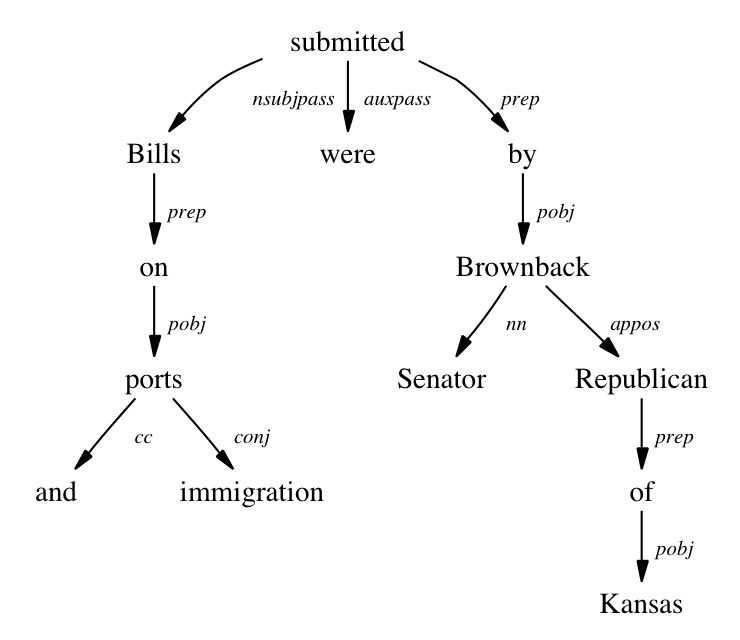
Source: https://nlp.stanford.edu/software/stanford-dependencies.html
A natural language parser is a program that figures out which group of words go together (as “phrases”) and which words are the subject or object of a verb. The NLP parser separates a series of text into smaller pieces based on the grammar rules. If a sentence that cannot be parsed may have grammatical errors.
How does a parser work?
The first step is to identify the subject of the sentence. As the parser splits the sequence of text into a bunch of words that are related in a sort of phrase. So, these bunch of words that we get that are related to each other is what is referred to as the subject.
Syntactic parsing and parts of speech, these language structures are context-free grammar is based on the structure or arrangement of words. It is not based on the context.
The important thing to note is that the grammar is always syntactically correct i.e. syntax wise and may not make contextual sense.
Implementation in Python
Now, lets’ see how to tag the words and create dependency trees in Python.
Using NLTK library:
The NLTK library includes:
- pre-trained Punkt tokenizer, which is used to tokenize the words.
- averaged_perceptron_tagger: is used to tag those tokenized words to Parts of Speech
The perceptron part-of-speech tagger implements part-of-speech tagging using the method called averaged_perceptron_tagger, a structured perceptron algorithm. This algorithm is used to figure out which word or token needs to be tagged along with the respective parts of speech.
import nltk
nltk.download('punkt')
nltk.download('averaged_perceptron_tagger')
from nltk import pos_tag, word_tokenize, RegexpParser
text = "Reliance Retail acquires majority stake in designer brand Abraham & Thakore."
tokens = word_tokenize(text)
tags = pos_tag(tokens)
tags
Chunk extraction or partial parsing is a process of extracting short phrases from the sentence (tagged with Part-of-Speech).
Chunking uses a special regexp syntax for rules that delimit the chunks. These rules must be converted to ‘regular’ regular expressions before a sentence can be chunked.
For this we need to call a Regex Formula, a Regex pattern — where we assign a pattern what is verb phrase or noun phrase and these small patterns can be recognized and it is called Chunk Extraction.
chunker = RegexpParser("""
NP: {?*} #To extract Noun Phrases
P: {} #To extract Prepositions
V: {} #To extract Verbs
PP: {
} #To extract Prepostional Phrases
VP: { *} #To extarct Verb Phrases
“””)
result = chunker.parse(tags)
print('Our Parse Notation:n', result)
result.draw()
Using spacy library:
import spacy
# Loading the model
nlp=spacy.load('en_core_web_sm')
text = "Reliance Retail acquires majority stake in designer brand Abraham & Thakore."
# Creating Doc object doc=nlp(text)
# Getting dependency tags
for token in doc:
print(token.text,'=>',token.dep_)

# Importing visualizer from spacy import displacy
# Visualizing dependency tree
displacy.render(doc,jupyter=True)
Endnote
Part-of-speech (POS) and syntactic parsing are used to extract noun, verb, and prepositional phrases and are context-free grammar. As these are syntactically correct and may not be contextually correct therefore we need some form of association i.e. word embeddings that will help to add context to the sentence.
The simplest approach for POS tagging using a structured perceptron algorithm is to break down the sentence into a sort of tagging and go from left to right.
I hope the article was helpful to you and you learned something new. Thank You so much for stopping by to read and helping in sharing the article with your network 🙂
Happy Learning!
About me
Hi there! I am Neha Seth. I hold a Postgraduate Program in Data Science & Engineering from the Great Lakes Institute of Management and a Bachelors in Statistics. I have been featured as Top 10 Most Popular Guest Authors in 2020 on Analytics Vidhya (AV).
My area of interest lies in NLP and Deep Learning. I have also passed the CFA Program. You can reach out to me on LinkedIn and can read my other blogs for AV.
The media shown in this article is not owned by Analytics Vidhya and are used at the Author’s discretion.
Hi there! I am Neha Seth. I work as a Data Scientist in Larsen & Toubro Infotech (LTI). I hold a Postgraduate Program in Data Science & Engineering from the Great Lakes Institute of Management and a Bachelors in Statistics. I have been featured as Top 10 Most Popular Guest Authors in 2020 on Analytics Vidhya (AV).
My area of interest lies in NLP and Deep Learning. I have also passed the CFA Program. You can reach out to me on LinkedIn and can read my other blogs for AV.







i have been trying to find more people who know this natural language very interested in talking with you further you might be intrigued on what we have to say