This article was published as a part of the Data Science Blogathon.

Introduction
Big Data is a very commonly heard term these days. A reasonably large volume of data that cannot be handled on a small capacity configuration of servers can be called ‘Big Data’ in that particular context. In today’s competitive world, every business organization relies on decision-making based on the outcome of the analyzed data they have on hand. The data pipeline starting from the collection of raw data to the final deployment of machine learning models based on this data goes through the usual steps of cleaning, pre-processing, processing, storage, model building, and analysis. Efficient handling and accuracy depend on resources like software, hardware, technical workforce, and costs. Answering queries requires specific data probing in either static or dynamic mode with consistency, reliability, and availability. When data is large, inadequacy in handling queries due to the size of data and low capacity of machines in terms of speed, memory may prove problematic for the organization. This is where sharding steps in to address the above problems.
This guide explores the basics and various facets of data sharding, the need for sharding, and its pros, and cons.
What is Data Sharding?
With the increasing use of IT technologies, data is accumulating at an overwhelmingly faster pace. Companies leverage this big data for data-driven decision-making. However, with the increased size of the data, system performance suffers due to queries becoming very slow if the dataset is entirely stored in a single database. This is why data sharding is required.
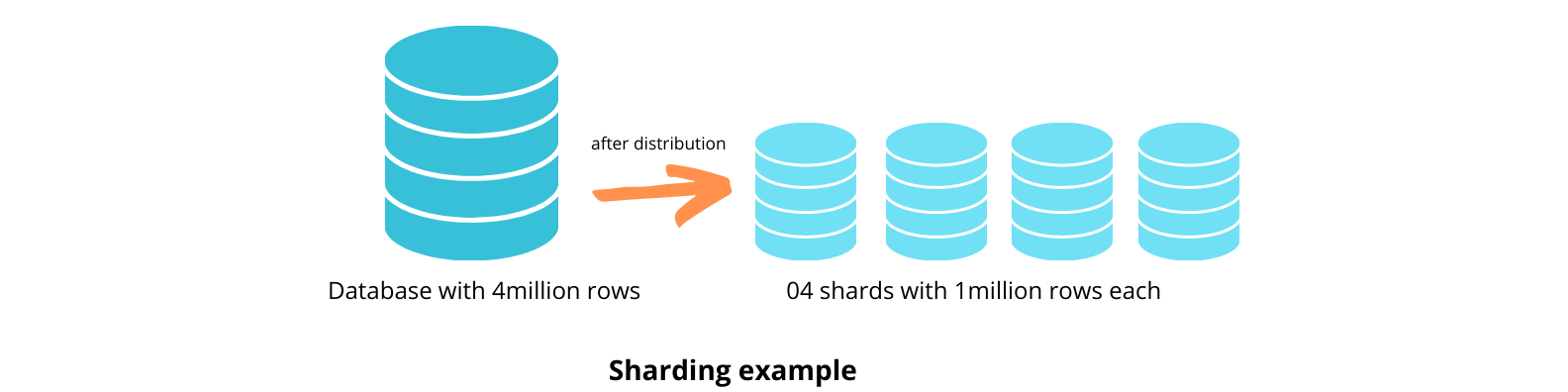
In simple terms, sharding is the process of dividing and storing a single logical dataset into databases that are distributed across multiple computers. This way, when a query is executed, a few computers in the network may be involved in processing the query, and the system performance is faster. With increased traffic, scaling the databases becomes non-negotiable to cope with the increased demand. Furthermore, several sharding solutions allow for the inclusion of additional computers. Sharding allows a database cluster to grow with the amount of data and traffic received.
Key terms used
Let’s look at some key terms used in the sharding of databases.
Scale-out and Scaling up: The process of creating or removing databases horizontally done to improve performance and increase capacity is called scale-out. Scaling up refers to the practice of adding physical resources to an existing database server, like memory, storage, and CPU, to improve performance.
Sharding: Sharding distributes similarly-formatted large data over several separate databases.
Chunk: A chunk is made up of sharded data subset and is bound by lower and higher ranges based on the shard key.
Shard: A shard is a horizontally distributed portion of data in a database. Data collections with the same partition keys are called logical shards, which are then distributed across separate database nodes.
Sharding Key: A sharding key is a column of the database to be sharded. This key is responsible for partitioning the data. It can be either a single indexed column or multiple columns denoted by a value that determines the data division between the shards. A primary key can be used as a sharding key. However, a sharding key cannot be a primary key. The choice of the sharding key depends on the application. For example, userID could be used as a sharding key in banking or social media applications.
Logical shard and Physical Shard: A chunk of the data with the same shard key is called a logical shard. When a single server holds one or more than one logical shard, it is called a physical shard.
Shard replicas: These are the copies of the shard and are allotted to different nodes.
Partition Key: It is a key that defines the pattern of data distribution in the database. Using this key, it is possible to direct the query to the concerned database for retrieving and manipulating the data. Data having the same partition key is stored in the same node.
Replication: It is a process of copying and storing data from a central database at more than one node.
Resharding: It is the process of redistributing the data across shards to adapt to the growing size of data.
Are Sharding and Partitioning the same?
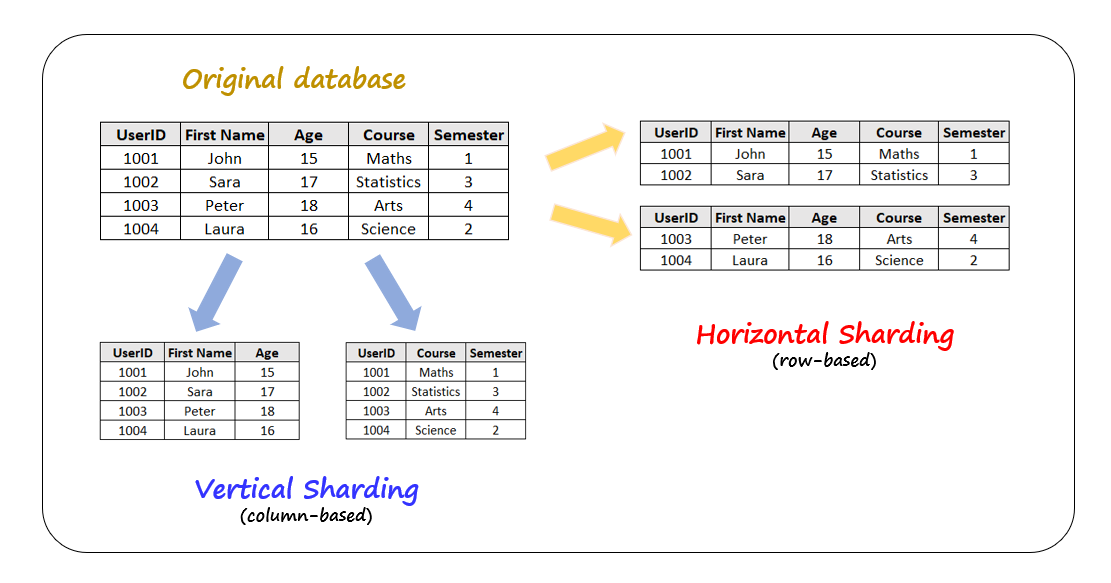
Both Sharding and Partitioning allow splitting and storing the databases into smaller datasets. However, they are not the same. Upon comparison, we can say that sharding distributes the data and is shared over several machines, but not with partitioning. Within a single unsharded database, partitioning is the process of grouping subsets of data. Hence, the phrases sharding and partitioning are used interchangeably when the terms “horizontal” and “vertical” are used before them. As a result, “horizontal sharding” and “horizontal partitioning” are interchangeable terms.
Vertical Sharding:
Entire columns are split and placed in new, different tables in a vertically partitioned table. The data in one vertical split is different from the data in the others, and each contains distinct rows and columns.
Horizontal Sharding:
Horizontal sharding or horizontal partitioning divides a table’s rows into multiple tables or partitions. Every partition has the same schema and columns but distinct rows. Here, the data stored in each partition is distinct and independent of the data stored in other partitions.
The image below shows how a table can be partitioned both horizontally and vertically.
The Process
Before sharding a database, it is essential to evaluate the requirements for selecting the type of sharding to be implemented.
At the start, we need to have a clear idea about the data and how the data will be distributed across shards. The answer is crucial as it will directly impact the performance of the sharded database and its maintenance strategy.
Next, the nature of queries that need to be routed through these shards should also be known. For read queries, replication is a better and more cost-effective option than sharding the database. On the other hand, workload involving writing queries or both read and write queries would require sharding of the database. And the final point to be considered is regarding shard maintenance. As the accumulated data increases, it needs to be distributed, and the number of shards keeps on growing over time. Hence, the distribution of data in shards requires a strategy that needs to be planned ahead to keep the sharding process efficient.
Types of Sharding Architectures
Sharding is frequently done at the application level. This means that the application includes code that specifies the routing for reads and writes to a particular shard. Some database management systems have sharding features, allowing you to implement sharding directly at the database level.
Once you have decided to shard the existing database, the following step is to figure out how to achieve it. It is crucial that during query execution or distributing the incoming data to sharded tables/databases, it goes to the proper shard. Otherwise, there is a possibility of losing the data or experiencing noticeably slow searches. In this section, we will look at some commonly used sharding architectures, each of which has a distinct way of distributing data between shards. There are three main types of sharding architectures – Key or Hash-Based, Range Based, and Directory-Based sharding.
To understand these sharding strategies, say there is a company that handles databases for its client who sell their products in different countries. The handled database might look like this and can often extend to more than a million rows.
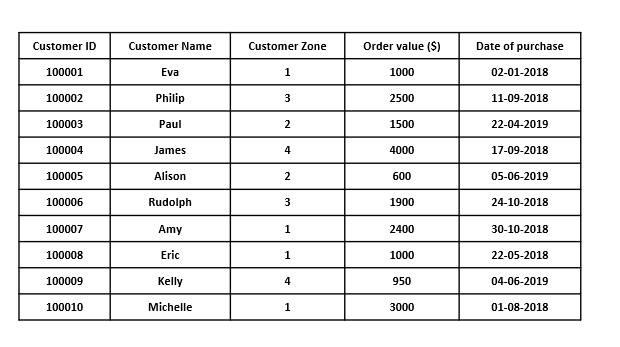
We will take a few rows from the above table to explain each sharding strategy.
So, to store and query these databases efficiently, we need to implement sharding on these databases for low latency, fault tolerance, and reliability.
Key Based Sharding
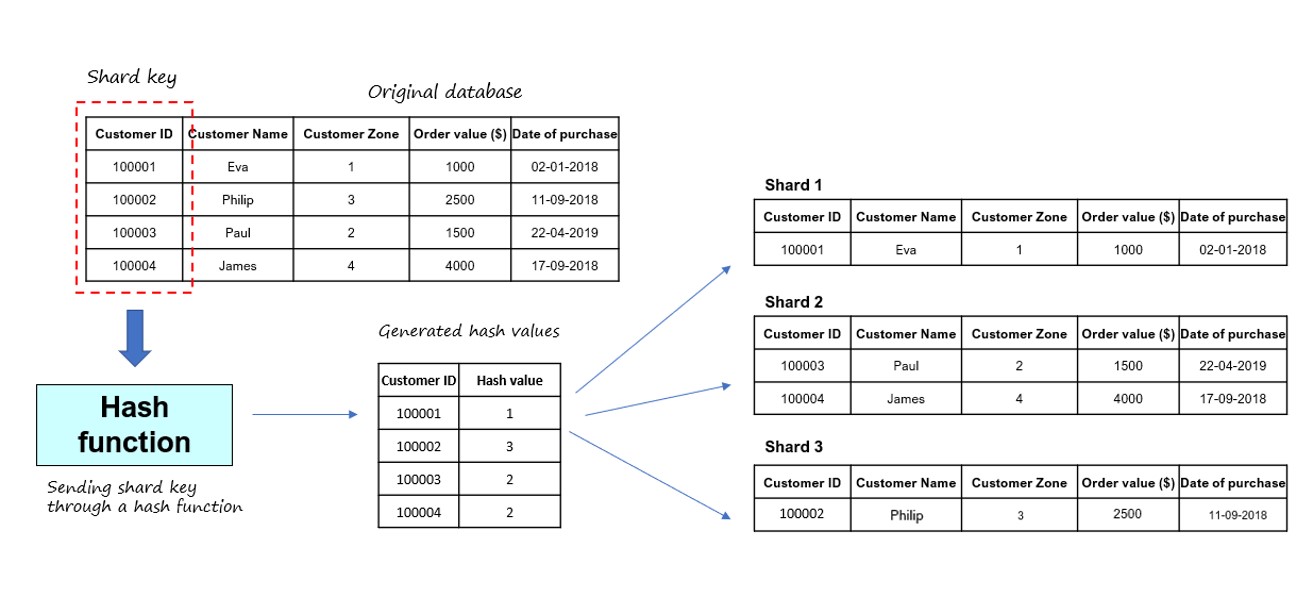
Key Based Sharding or Hash-Based Sharding, uses a value from the column data — like customer ID, customer IP address, a ZIP code, etc. to generate a hash value to shard the database. This selected table column is the shard key. Next, all row values in the shard key column are passed through the hash function.
This hash function is a mathematical function that converts any text input size (usually a combination of numbers and strings) and returns a unique output called a hash value. The hash value is based on the chosen algorithm (depending on the data and application) and the total number of available shards. This value indicates the data should be sent to which shard number.
It is important to remember that a shard key needs to be both unique and static, i.e., it should not change over a period of time. Otherwise, it would increase the amount of work required for update operations, thus slowing down performance.
The Key Based Sharding process looks like this:
Features of Key Based Sharding are-
It is easier to generate hash keys using algorithms. Hence, it is good at load balancing since data is equally distributed among the available numbers of shards.
As all shards share the same load, it helps to avoid database hotspots (when one shard contains excessive data as compared to the rest of the shards).
Additionally, in this type of sharding, there is no need to have any additional map or table to hold the information of where the data is stored.
However, it is not dynamic sharding, and it can be difficult to add or remove extra servers from a database depending on the application requirement. The adding or removing of servers requires recalculating the hash key. Since the hash key changes due to a change in the number of shards, all the data needs to be remapped and moved to the appropriate shard number. This is a tedious task and often challenging to implement in a production environment.
To address the above shortcoming of Key Based Sharding, a ‘Consistent Hashing’ strategy can be used.
Consistent Hashing-
In this strategy, hash values are generated both for the data input and the shard, based on the number generated for the data and the IP address of the shard machine, respectively. These two hash values are arranged around a ring or a circle utilizing the 360 degrees of the circle. The hash values that are close to each other are made into a pair, which can be done either clockwise or anti-clockwise.
The data is loaded according to this combination of hash values. Whenever the shards need to be reduced, the values from where the shard has been removed are attached to the nearest shard. A similar procedure is adopted when a shard is added. The possibility of mapping and reorganization problems in the Hash Key strategy is removed in this way as the mapping of the number of shards is reduced noticeably. For example, in Key Based Hashing, if you are required to shuffle the data to 3 out of 4 shards due to a change in the hash function, then in ‘consistent hashing,’ you will require shuffling on a lesser number of shards as compared to the previous one. Moreover, any overloading problem is taken care of by adding replicas of the shard.
Range Based Sharding
Range Based Sharding is the process of sharding data based on value ranges. Using our previous database example, we can make a few distinct shards using the Order value amount as a range (lower value and higher value) and divide customer information according to the price range of their order value, as seen below:
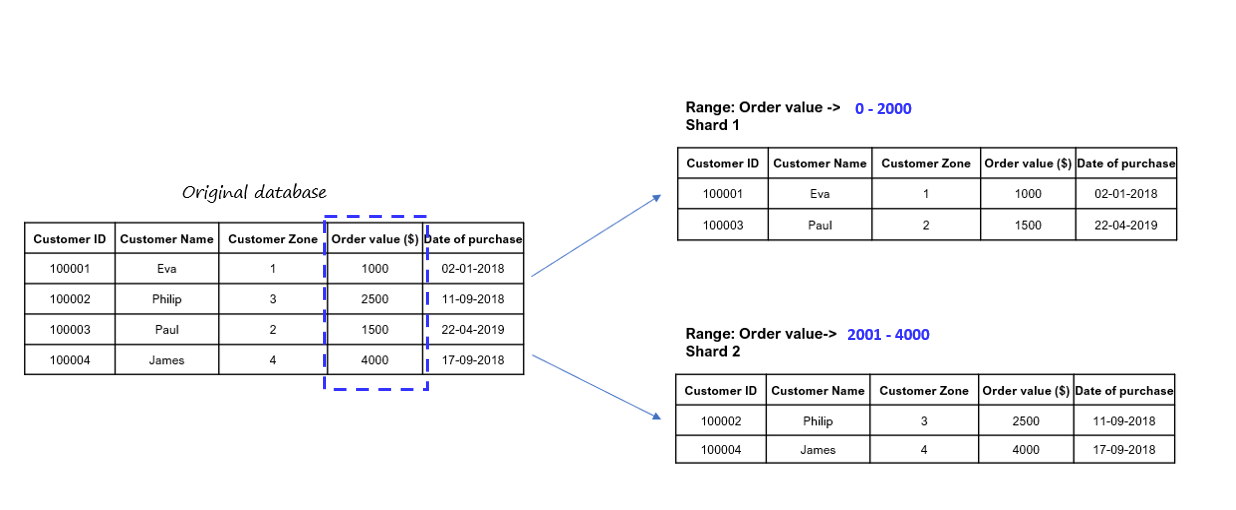
Features of Range Based Sharding are-
One major advantage of using the Range Based Sharding is its ease of implementation.
With Range Based Sharding, each shard has a unique data collection, and they all share the same schema of the main database. The application code reads the data range and directs it to the concerned range value shard.
Besides, there is no hashing function involved. Hence, it is possible to easily add more machines or reduce the number of machines. And there is no need to shuffle or reorganize the data.
On the other hand, this type of sharding does not ensure evenly distributed data. It can result in overloading a particular shard, commonly referred to as a database hotspot.
Directory-Based Sharding
This type of sharding relies on a lookup table (with the specific shard key) that keeps track of the stored data and the concerned allotted shards. It tells us exactly where the particular queried data is stored or located on a specific shard. This lookup table is maintained separately and does not exist on the shards or the application. The following image demonstrates a simple example of a Directory-Based Sharding.
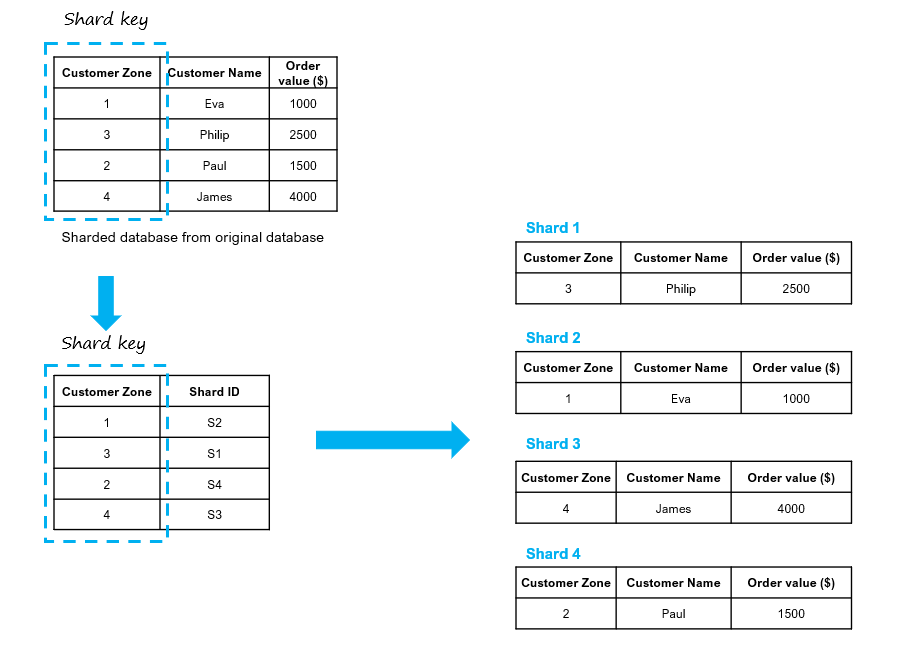
Let’s say in our previously defined database; there are a limited number of customer zones. Then, the Customer Zone column can be defined as a shard key, and we can divide the data based on customer zones. So, each zone can be mapped to one particular shard only. Thus, when there is a write/read query, the application code reads the zone and location from the lookup table; then, the application connects to the concerned shard by routing the query accordingly.
Features of Directory-Based Sharding are –
The directory-Based Sharding strategy is highly adaptable. While Range Based Sharding is limited to providing ranges of values, Key Based Sharding is heavily dependent on a fixed hash function, making it challenging to alter later if application requirements change. Directory-Based Sharding enables us to use any method or technique to allocate data entries to shards, and it is convenient to add or reduce shards dynamically.
The only downside of this type of sharding architecture is that there is a need to connect to the lookup table before each query or write every time, which may increase the latency.
Furthermore, if the lookup table gets corrupted, it can cause a complete failure at that instant, known as a single point of failure. This can be overcome by ensuring the security of the lookup table and creating a backup of the table for such events.
Other than the three main sharding strategies discussed above, there can be many more sharding strategies that are usually a combination of these three.
After this detailed sharding architecture overview, we will now understand the pros and cons of sharding databases.
Benefits of Sharding
Horizontal Scaling: For any non-distributed database on a single server, there will always be a limit to storage and processing capacity. The ability of sharding to extend horizontally makes the arrangement flexible to accommodate larger amounts of data.
Speed: Speed is one more reason why sharded database design is preferred is to improve query response times. Upon submitting a query to a non-sharded database, it likely has to search every row in the table before finding the result set, you’re searching for. Queries can become prohibitively slow in an application with an unsharded single database. However, by sharding a single table into multiple tables, queries pass through fewer rows, and their resulting values are delivered considerably faster.
Reliability: Sharding can help to improve application reliability by reducing the effect of system failures. If a program or website is dependent on an unsharded database, a failure might render the entire application inoperable. An outage in a sharded database, on the other hand, is likely to affect only one shard. Even if this causes certain users to be unable to access some areas of the program or website, the overall impact would be minimal.
Challenges in Sharding
While sharding a database might facilitate growth and enhance speed, it can also impose certain constraints. We will go through some of them and why they could be strong reasons to avoid sharding entirely.
Increased complexity: Companies usually face a challenge of complexity when designing shared database architecture. There is a risk that the sharding operation will result in lost data or damaged tables if done incorrectly. Even if done correctly, shard maintenance and organization are likely to significantly influence the outcome.
Shard Imbalancing: Depending on the sharding architecture, distribution on different shards can get imbalanced due to incoming traffic. This results in remapping or reorganizing the data amongst different shards. Obviously, it is time-consuming and expensive.
Unsharding or restoring the database: Once a database has been sharded, it can be complicated to restore it to its earlier version. Backups of the database produced before it was sharded will not include data written after partitioning. As a result, reconstructing the original unsharded architecture would need either integrating the new partitioned data with the old backups or changing the partitioned database back into a single database, both of which would undesirable.
Not supported by all databases: It is to be noted that not every database engine natively supports sharding. There are several databases currently available. Some popular ones are MySQL, PostgreSQL, Cassandra, MongoDB, HBase, Redis, and more. Databases namely MySQL or MongoDB has an auto-sharding feature. As a result, we need to customize the strategy to suit the application requirements when using different databases for sharding.
Of course, these are only a few considerations to think about before sharding. Depending on the application in focus, there might be some other disadvantages to sharding a database.
Now that we have discussed the pros and cons of sharding databases, let us explore situations when one should select sharding.
When should one go for Sharding?
Although sharding is advantageous for database scaling, it is not always the best choice. This necessitates an evaluation of the need for sharding before implementing it. Choosing a sharded architecture depends on the database size, resources, and technical expertise for handling the complexity. Following are some situations where a sharded architecture can be beneficial.
- When the application data outgrows the storage capacity and can no longer be stored as a single database, sharding becomes essential.
- When the volume of reading/writing exceeds the current database capacity, this results in a higher query response time or timeouts.
- When a slow response is experienced while reading the read replicas, it indicates that the network bandwidth required by the application is higher than the available bandwidth.
Excluding the above situations, it is possible to optimize the database instead. These could include carrying out server upgrades, implementing caches, creating one or more read replicas, setting up remote databases, etc. Only when these options cannot solve the problem of increased data, sharding is always an option.
Conclusion
We have covered the fundamentals of sharding in Data Engineering and by now have developed a good understanding of this topic
With sharding, businesses can add horizontal scalability to the existing databases. However, it comes with a set of challenges that need to be addressed. These include considerable complexity, possible failure points, a requirement for additional resources, and more. Thus, sharding is essential only in certain situations.
I hope you enjoyed reading this guide! In the next part of this guide, we will cover how sharding is implemented step-by-step using MongoDB.
Author Bio
Devashree holds an M.Eng degree in Information Technology from Germany and a background in Data Science. She likes working with statistics and discovering hidden insights in varied datasets to create stunning dashboards. She enjoys sharing her knowledge in AI by writing technical articles on various technological platforms.
She loves traveling, reading fiction, solving Sudoku puzzles, and participating in coding competitions in her leisure time.
You can follow her on LinkedIn, GitHub, Kaggle, Medium, Twitter.
The media shown in this article is not owned by Analytics Vidhya and are used at the Author’s discretion.
Devashree has an M.Eng degree in Information Technology from Germany and a Data Science background. As an Engineer, she enjoys working with numbers and uncovering hidden insights in diverse datasets from different sectors to build beautiful visualizations to try and solve interesting real-world machine learning problems.
In her spare time, she loves to cook, read & write, discover new Python-Machine Learning libraries or participate in coding competitions.






