This article was published as a part of the Data Science Blogathon.
Introduction
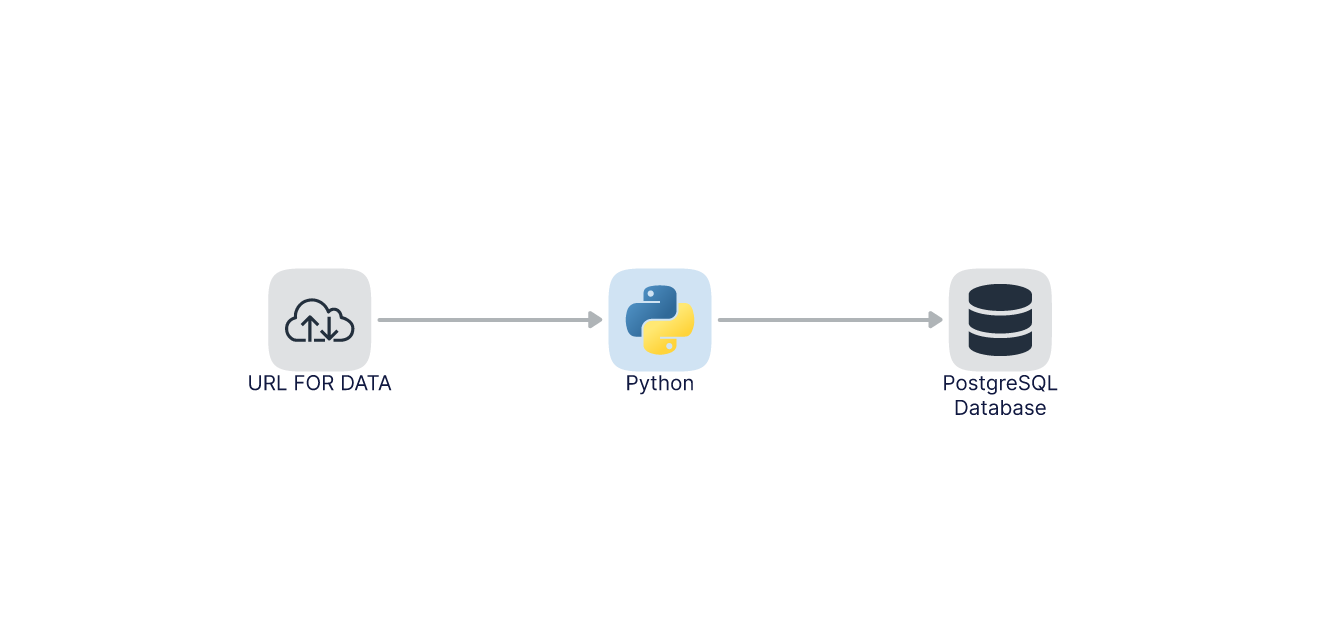
In this blog, we will explore one interesting aspect of the pandas read_csv function, the Python Iterator parameter, which can be used to read relatively large input data. Pandas library in python is an excellent choice for reading and manipulating data as data frames. It can handle file formats like CSV, EXCEL, JSON, XML files, etc. It is a known fact that pandas have some limitations when handling large datasets, and modern alternate tools such as Apache Spark provides an open-source cluster computing framework where data processing can be distributed and carried out in parallel operations by multiple nodes. We will keep our discussions to the pandas’ library and walk through a use case where we will pull data from a URL and ingest it into a Postgres database using a python script.
Python Iterators
Let’s say we have a python Iterator list, and to retrieve elements of this list we can use a for loop,
num = [7,9,12,45] for i in num: print(i,end=' ')
We can use the above list object as an python iterator using the following commands,
my_it = iter(num) print(my_it)
The print statement did not return the values but returned a list_iterator object. We can use print(my_it.__next__()) or print(next(my_it) to retrieve the values one by one . Each print statement will return the values one by one. The iterators have a few advantages, viz,
- they result in cleaner code,
- they can work with infinite sequences
- iterators save memory resources (the next element is kept in a sequence rather than the entire dataset in memory )
The Code Walk-Through (Python Iterator)
We had a brief look at iterators in the above example, and let’s jump into our code to understand the context of iterators with relevance to the pandas’ library. The use case we have chosen is to get a dataset from a URL and ingest the same into a Postgres database. We will work on a relatively large dataset to understand how to optimally use memory resources using pandas. The use case is a typical Data Engineering problem, where we extract the data and load it into a database for further processing. I have used PostgreSQL as the database in this case (you may also look at alternate options like MySql, SQLite, etc.). PostgreSQL is an open-source relational database management system and is a popular choice for Date Engineering pipelines as it provides reliability, data integrity, and correctness.
For setting up the database, one option is to install the PostgreSQL (or database of your choice ) on our local machine. The methodology I have chosen is to use Docker to run my Postgres instance in the local machine. If you are not familiar with Docker, I would recommend you to have a look at my article on Docker in Analytics Vidhya or other resources available on the internet. Using Docker will save us the effort of local installation of the database. However, you are required to install Docker Desktop on your local machine before starting the code walkthrough.
Creating a Project Environment
In the beginning, it is always a good practice to create a virtual environment for our project. This will enable us to create an isolated environment for our project and include all the dependencies required for the project in that environment. Again, there are multiple options available to create a virtual environment and I have used conda to create my virtual environment. I have also used Linux Environment inside Windows (WSL2) as my chosen OS and there could be small differences in approach depending upon the OS you have chosen. I would suggest you look up resources like Stack Overflow for any problems encountered on the way. So let’s start by creating our project folder and run some basic command line commands.
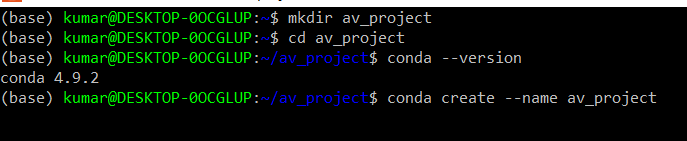

Now we are in a virtual environment called av_project. As a prior requirement, we need to have python3 and Docker-Desktop installed on your local machine. The readers may consider installing Anaconda as it provides a good solution to use a conda environment with python. Once installation of python3 and Docker is complete, use the following commands to verify the same on the terminal.
python3 --version docker --version
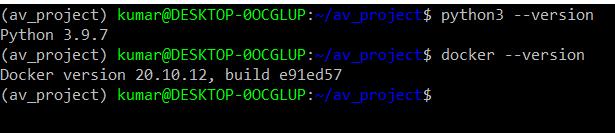
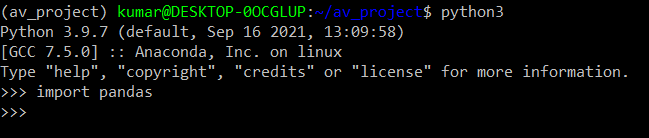
We have confirmed python and Docker are available to proceed with our code. We also need to install a couple of libraries, pandas, sqlalchemy and psycopg2, and we can use the following command on the terminal,
pip install pandas sqlalchemy psycopg2
We can check the libraries available in our environment by using the python shell (type python on command Line), and it opens the python interpreter. The import command in the shell should not throw any error.
Launching PostgreSQL Database in Docker Container
Now we can launch our PostgreSQL container, which is where our data will be stored. The advantage of using Docker to run the application is that it gives reproducibility (the application can be run on any machine without any problem). We can also test our application in a local environment before deployment in a production environment. We will use the PostgreSQL image from the docker hub and will also require to pass some config parameters while running the docker image. The database config parameters are passed as env variables, and we can pass with the -e flag in the command line for the docker run command. We will pass user, password and database name as env variables. In an actual production scenario, we have to be careful in passing database credentials as they can get compromised. But for now, in the testing scenario, we can adopt this methodology.
We will be required to map a folder in our local machine to a folder inside the docker container so that data persists even after we shut down the container and restart it. We will create a nz_postgres_data folder within our project folder.

We will also indicate a port mapping between our local machine and the docker container running inside the local machine so that we are able to communicate with the database in the container. This is done with -p flag in the docker run command. Let’s execute the docker run command from our command line:
docker run -it -e POSTGRES_USER="root" -e POSTGRES_PASSWORD="root" -e POSTGRES_DB="nz_data" -v $(pwd)/nz_postgres_data:/var/lib/postgresql/data -p 5432:5432 postgres:13
The following may be noted
- We are using docker image postgres:13 from the public repository.
- It flag indicates the interactive mode of execution
- Database user and password is the root
- The database name is nz_data
- We have mapped the folder in the local machine with the container folder using the -v flag
- you may have to use the absolute path of the folder in your machine in the -v flag (especially if you are on a windows machine)
- The command maps port 5432 on the host machine to port 5432 on the docker container
It may take a couple of minutes to get the container going as docker pulls the image from the repo and sets up the database connection. The expected output is as follows:

Open another terminal, and get into the same project environment (av_project in my case ) . we can run the docker ps command to confirm our container is running,

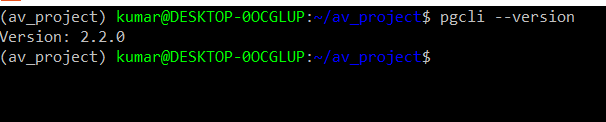
The output indicates that the docker container is running. As I did not specify a particular name for the container, a random name was assigned to the container. We can access the database using a PostgreSQL client. There are a couple of options available for us. I will use a command-line client called pgcli for accessing the database. There are also GUI tools like pgadmin, DBeaver, which can connect to the database in a visually appealing manner. Please feel free to explore alternate options for accessing the database. If you are using pgcli then check the reference link for installation. The successful installation can be confirmed using the pgcli –version command.
Use the following command to connect to the database through pgcli,
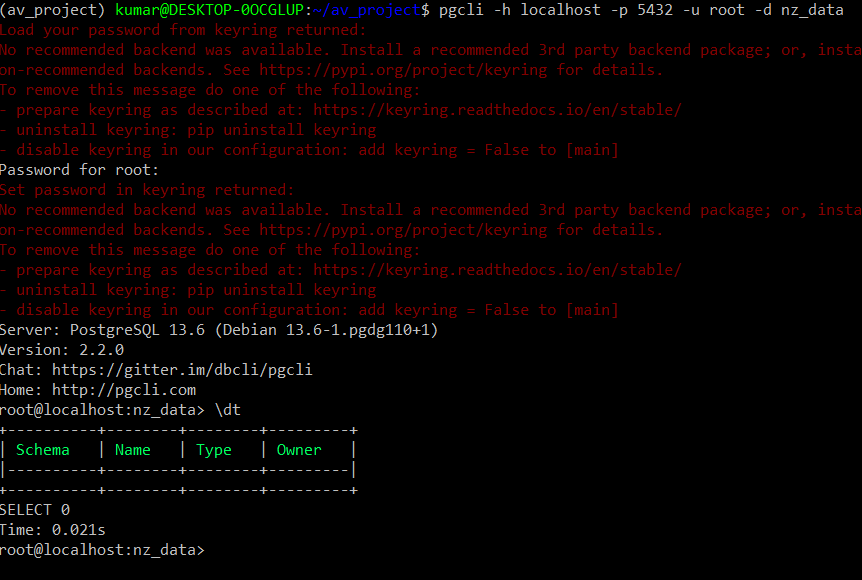
pgcli -h localhost -p 5432 -u root -d nz_data
The system asks for a password (which is the root in our case, and I am ignoring the warnings for the time being ) and opens up the prompt. Type dt to look at the tables in the database.
Python Script for Data Ingestion
As expected, the database is empty. Let’s head to write our python script to ingest the data into the database. I will be using VS Code to write my code as it provides a nice platform to write and test our python code. Open VS code (or whatever editor you are using ) and navigate to our project folder. Create a file named ingest_data.py in the project folder and step over to edit the file on the editor window. I have used a synthetic sales dataset of 5 million rows and 111.96 MB of memory space from the public domain to test our pipeline. The data is in 7z compressed format, and we will have to factor in to decompress the data before ingesting it into the table. I have used print statements intermittently to get the progress of pipeline execution on the terminal.
The broad sequence of our automated data pipeline is as follows,
- Import necessary libraries
- Download the data (7zip file) and extract the contents to the local folder
- Create a Postgres DB engine and connect the engine to our database in our container
- Read a sample of our CSV file using pandas(using the nrows parameter) and use the header information to create an empty table (where the data will be stored) in our database.
- Once a table is created, we will read the data in chunks using the pandas iterator parameter and ingest the data into the table.
We will require wget and py7zr for automated downloading of 7z file from URL and extracting the contents to our project folder. Use pip install in the terminal to install these libraries.
import pandas as pd
from sqlalchemy import create_engine
import subprocess
import py7zr
import glob
from time import time
LOCAL_PATH = "/home/kumar/av_project"
#function to use subprocess to download file from URL
def runcmd(cmd, verbose = False, *args, **kwargs):
process = subprocess.Popen(
cmd,
stdout = subprocess.PIPE,
stderr = subprocess.PIPE,
text = True,
shell = True
)
std_out, std_err = process.communicate()
if verbose:
print(std_out.strip(), std_err)
pass
runcmd(“wget https://eforexcel.com/wp/wp-content/uploads/2020/09/5m-Sales-Records.7z “, verbose = True)
print(“Data downloaded into local folder”)
archive = py7zr.SevenZipFile(‘5m-Sales-Records.7z’, mode=’r’)
archive.extractall(path=LOCAL_PATH)
archive.close()
print(“Data extracted from 7z file to CSV file in local folder”)
The pipeline part, which includes downloading of data from URL, is handled by the python function runcmd(). This function runs a Linux command wget to download the compressed file. Thereafter, the python library py7z is used to extract the compressed file to the project folder. We can create a database engine using sqlalchemy to connect to our Postgres database running in the container. We have to pass database credentials as a parameter to the create_engine function.
#create an DB engine
engine = create_engine('postgresql://root:root@localhost:5432/nz_data')
engine.connect()
#read small part of data to create our table
path = LOCAL_PATH # use your path
all_files = glob.glob(path + "/*.csv")
#loop through to files in project folder to read csv file
for filename in all_files:
if "csv" in filename:
df = pd.read_csv(filename,nrows=10)
#creata a table in nz_data database
df.head(n=0).to_sql(name='nz_stat_data', con=engine, if_exists='replace')
print("Table Created..")
#read data as a iterator in chunnksize of 100,000
for filename in all_files:
if "csv" in filename:
df_iter = pd.read_csv(filename, iterator=True, chunksize=100000)
The above snippet of code creates a loop to traverse through the files in LOCAL_PATH to search for a CSV file and read in 10 rows into a data frame. We will create an empty table in our database with only headers of the data frame using the df.to_sql() method. Once a table is created, we will use the iterator parameter of pandas read_csv() function to read the entire data set. I have used iterator-True and a chunk size of 100,000 (rows) to read the data. Next (df_iter) will sequentially load 100,000 rows into the memory. We will again use the df.to_sql() method to load 100,000 rows into a temporary data frame and ingest them into the database. The loop will exit once our 5 million rows have been ingested into the database.
loop_start = time()
# data ingestion into DB in chunks of 100,000 rows
while True:
try:
print('Data ingestion in progress ..')
t_start = time()
df = next(df_iter) #loads chunk of data into df
# ingest data to table ,append rows
df.to_sql(name='nz_stat_data', con=engine, if_exists='append')
t_end = time()
print(f'Inserted another 100,000 rows into DB, took {round((t_end - t_start),2)} secs')
except StopIteration:
print('Data ingestion completed.')
print(f'Overall Data Ingestion time {round((loop_start -time()),2)} secs')
break
Execution of Data Pipeline
We have completed ingest_data.py, which will automate our downloading of data from URL, decompress the 7z file and ingest it into a table in a data frame in steps. We can head over to the terminal again and run the command(please ensure your container is running).
python3 ingest_data.py
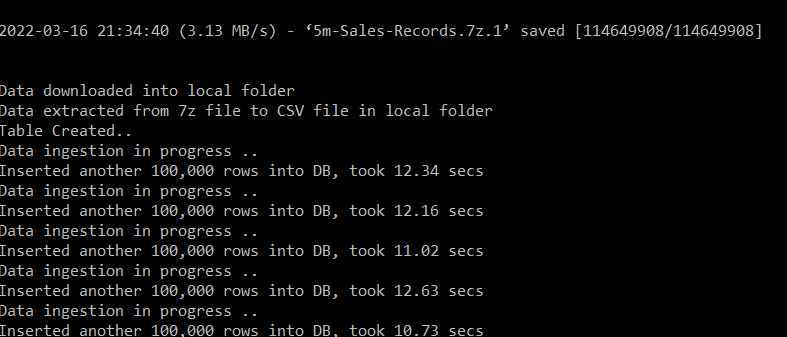
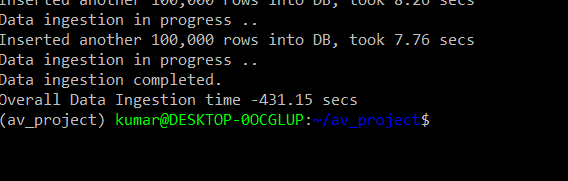
The output of running our script is as shown above. If you look at the project folder, you can see both the compressed and CSV data files. Let’s check our table in the database to see if the data is correctly ingested. We will again use the terminal and client tool pgcli, and type the earlier command to enter the database promptly. We should be able to execute some basic SQL commands to verify the contents of the database.
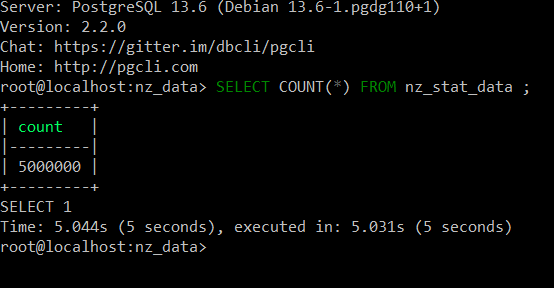
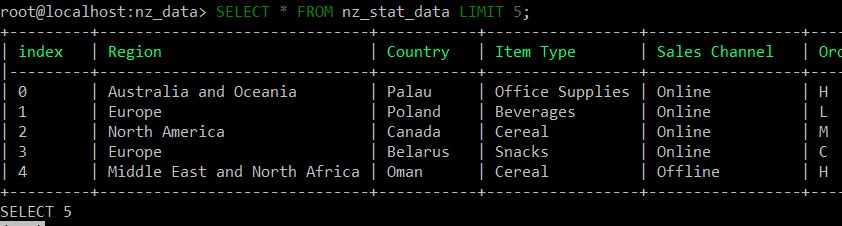
The above visuals indicate that the 5 million records have been ingested into the database table. We can be happy and proud that our data pipeline is working fine !!
Conclusion
This article demonstrated a use case to build a simple data pipeline to demonstrate the use of python iterator in a python script to handle a dataset with a large number of rows. We have used a Data Pipeline, which pulls data from a URL and ingests it into a database using a python script. Our focus area in this article was the use of Python iterator to handle a relatively large dataset consisting of 5 million rows using the Python iterator parameter in the pandas read_csv() function. This helped us to manage the data ingestion in chunks, thereby optimally using our memory resources. I would like to recommend to the readers to explore other modern tools to handle big data and their use cases. To summarize, the following are the key takeaways:-
- Use of Python iterator datatype with python script can result in a clean code and efficient memory usage
- Python iterator parameter in pandas read_csv() function can be optimally used to handle relatively large datasets
- Docker containers provide excellent flexible solutions to package and deploy our application
- Python language provides good flexibility to build a data pipeline with excellent libraries
I would also like to acknowledge that this article is a result of my learnings while attending lectures on Data Engineering by Mr. Alexey Grigorev ( DataTalks Club) in Data Engineering Zoom Camp.
The media shown in this article is not owned by Analytics Vidhya and are used at the Author’s discretion.
A Marine Engineering professional with more than 29 years experience with a passion to leverage data for business solutions. I am a post graduate In Mechanical Engineering with experiences ranging from Operations, Production, Project Management, Quality Management and Data Analytics. I have also completed Advanced Certification in Data Science from Thayer School of Engineering , University of Dartmouth. I strongly believe learning is continuous process for growth in life and sharing knowledge builds a sense of community






