This article was published as a part of the Data Science Blogathon.

Introduction
Style transfer is a developing field in neural networks and it is a very useful feature that can be integrated into social media and AI apps. Several neural networks can map and transfer image styles to an input image as per the training data. In this article, we will look into JojoGAN and the process of using just one reference style to train and generate sketches of any image with that style.
Impact of One-shot Face Stylization
One-shot face stylization can be used in AI apps, social media filters, fun applications, and business use cases. With the rising popularity of AI-generated image and video filters, along with their use in social media reels and short videos, images, one-shot face stylization is a useful feature that these apps and social media companies can integrate into their products for the end-user.
So let’s narrow down on a popular GAN architecture for generating face stylizations at one go – JojoGAN.
JojoGAN Architecture
JojoGAN architecture works on a simple process of mapping a style to an image and learning the mapping to reproduce it for other unseen images in one shot. It uses a reversal process for GANs and the style mixing property of StyleGAN to create a one-to-one combined dataset pair from just one style. This dataset then is used for fine-tuning StyleGAN, and new input images can be used which the JojoGAN will convert to that specific style based on GAN Inversion.
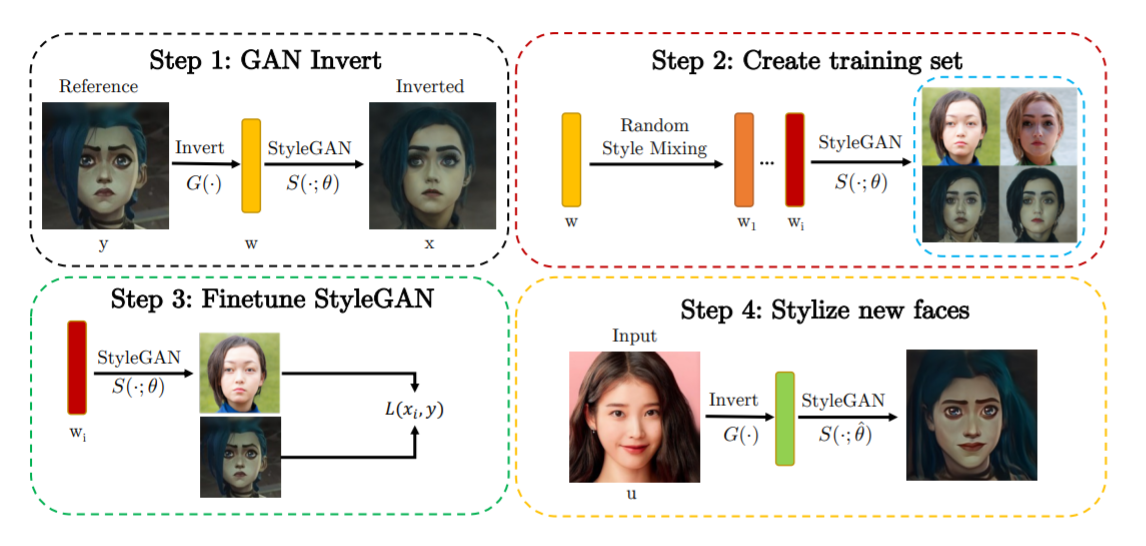
JojoGAN Architecture and Workflow
JojoGAN can be trained in very little time (less than 1 minute) with just one reference style and produces high-quality stylized images.
Some Examples of JojoGan
Some examples of JojoGAN generated stylized images:

JojoGAN Examples
The stylized images can be generated on a variety of different input stylizations and can be modified.
JojoGan Code Deep Dive
Let’s look at the implementation of JojoGAN to generate stylized portraits. Several pre-trained models are available, and they can be trained on our style images, or the model can be modified to change the styles at minute levels.
Setup and Imports for JojoGAN
Clone the JojoGAN repo and import the necessary libraries. Create some folders in Google Colab storage for storing the inversion code, style images, and models.
!git clone https://github.com/mchong6/JoJoGAN.git %cd JoJoGAN !pip install tqdm gdown scikit-learn==0.22 scipy lpips dlib opencv-python wandb !wget https://github.com/ninja-build/ninja/releases/download/v1.8.2/ninja-linux.zip !sudo unzip ninja-linux.zip -d /usr/local/bin/
import torch torch.backends.cudnn.benchmark = True from torchvision import transforms, utils from util import * from PIL import Image import math import random import os import numpy from torch import nn, autograd, optim from torch.nn import functional from tqdm import tqdm import wandb from model import * from e4e_projection import projection from google.colab import files from copy import deepcopy from pydrive.auth import GoogleAuth from pydrive.drive import GoogleDrive from google.colab import auth from oauth2client.client import GoogleCredentials
Model Files
Download the model files with Pydrive. A set of drive ids are available for pre-trained models. These pre-trained models can be used for generating stylized images on the go, and have different levels of accuracy. Later, user-created models can be trained.
#Download models #optionally enable downloads with pydrive in order to authenticate and avoid drive download limits. download_with_pydrive = True device = 'cuda' #['cuda', 'cpu']
!wget http://dlib.net/files/shape_predictor_68_face_landmarks.dat.bz2 !bzip2 -dk shape_predictor_68_face_landmarks.dat.bz2 !mv shape_predictor_68_face_landmarks.dat models/dlibshape_predictor_68_face_landmarks.dat %matplotlib inline
drive_ids = {
"stylegan2-ffhq-config-f.pt": "1Yr7KuD959btpmcKGAUsbAk5rPjX2MytK",
"e4e_ffhq_encode.pt": "1o6ijA3PkcewZvwJJ73dJ0fxhndn0nnh7",
"restyle_psp_ffhq_encode.pt": "1nbxCIVw9H3YnQsoIPykNEFwWJnHVHlVd",
"arcane_caitlyn.pt": "1gOsDTiTPcENiFOrhmkkxJcTURykW1dRc",
"arcane_caitlyn_preserve_color.pt": "1cUTyjU-q98P75a8THCaO545RTwpVV-aH",
"arcane_jinx_preserve_color.pt": "1jElwHxaYPod5Itdy18izJk49K1nl4ney",
"arcane_jinx.pt": "1quQ8vPjYpUiXM4k1_KIwP4EccOefPpG_",
"arcane_multi_preserve_color.pt": "1enJgrC08NpWpx2XGBmLt1laimjpGCyfl",
"arcane_multi.pt": "15V9s09sgaw-zhKp116VHigf5FowAy43f",
"sketch_multi.pt": "1GdaeHGBGjBAFsWipTL0y-ssUiAqk8AxD",
"disney.pt": "1zbE2upakFUAx8ximYnLofFwfT8MilqJA",
"disney_preserve_color.pt": "1Bnh02DjfvN_Wm8c4JdOiNV4q9J7Z_tsi",
"jojo.pt": "13cR2xjIBj8Ga5jMO7gtxzIJj2PDsBYK4",
"jojo_preserve_color.pt": "1ZRwYLRytCEKi__eT2Zxv1IlV6BGVQ_K2",
"jojo_yasuho.pt": "1grZT3Gz1DLzFoJchAmoj3LoM9ew9ROX_",
"jojo_yasuho_preserve_color.pt": "1SKBu1h0iRNyeKBnya_3BBmLr4pkPeg_L",
"art.pt": "1a0QDEHwXQ6hE_FcYEyNMuv5r5UnRQLKT",
}
# from StyelGAN-NADA
class Downloader(object):
def __init__(self, use_pydrive):
self.use_pydrive = use_pydrive
if self.use_pydrive:
self.authenticate()
def authenticate(self):
auth.authenticate_user()
gauth = GoogleAuth()
gauth.credentials = GoogleCredentials.get_application_default()
self.drive = GoogleDrive(gauth)
def download_file(self, file_name):
file_dst = os.path.join('models', file_name)
file_id = drive_ids[file_name]
if not os.path.exists(file_dst):
print(f'Downloading {file_name}')
if self.use_pydrive:
downloaded = self.drive.CreateFile({'id':file_id})
downloaded.FetchMetadata(fetch_all=True)
downloaded.GetContentFile(file_dst)
else:
!gdown --id $file_id -O $file_dst
downloader = Downloader(download_with_pydrive)
downloader.download_file('stylegan2-ffhq-config-f.pt')
downloader.download_file('e4e_ffhq_encode.pt')
Load the Generators
Load the original and finetuning generators. Set the transfomer for resizing and normalizing the images.
latent_dim = 512
# Load original generator
original_generator = Generator(1024, latent_dim, 8, 2).to(device)
ckpt = torch.load('models/stylegan2-ffhq-config-f.pt', map_location=lambda storage, loc: storage)
original_generator.load_state_dict(ckpt["g_ema"], strict=False)
mean_latent = original_generator.mean_latent(10000)
# to be finetuned generator generator = deepcopy(original_generator)
transform = transforms.Compose(
[
transforms.Resize((1024, 1024)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
]
)
Input Image
Set the input image location. Align and crop face and restyle the projection.
#image to the test_input directory and put the name here
filename = 'face.jpeg' #@param {type:"string"}
filepath = f'test_input/{filename}'
name = strip_path_extension(filepath)+'.pt'
# aligns and crops face aligned_face = align_face(filepath)
# my_w = restyle_projection(aligned_face, name, device, n_iters=1).unsqueeze(0) my_w = projection(aligned_face, name, device).unsqueeze(0)

Input Image – Elon Musk
Pre-trained Sketches
Select the pre-trained sketch type and choose the checkpoint without color preservation for better results.
plt.rcParams['figure.dpi'] = 150 pretrained = 'sketch_multi' #['art', 'arcane_multi', 'sketch_multi', 'arcane_jinx', 'arcane_caitlyn', 'jojo_yasuho', 'jojo', 'disney'] #Preserve color tries to preserve color of original image by limiting family of allowable transformations.
if preserve_color:
ckpt = f'{pretrained}_preserve_color.pt'
else:
ckpt = f'{pretrained}.pt'
Generate Results
Load the checkpoint and generator and set a seed value, and start generating the stylized image. The input image used for Elon Musk will be stylized according to the sketch type.
#Generate results
n_sample = 5#{type:"number"}
seed = 3000 #{type:"number"}
torch.manual_seed(seed)
with torch.no_grad():
generator.eval()
z = torch.randn(n_sample, latent_dim, device=device)
original_sample = original_generator([z], truncation=0.7, truncation_latent=mean_latent)
sample = generator([z], truncation=0.7, truncation_latent=mean_latent)
original_my_sample = original_generator(my_w, input_is_latent=True)
my_sample = generator(my_w, input_is_latent=True)
# display reference images
if pretrained == 'arcane_multi':
style_path = f'style_images_aligned/arcane_jinx.png'
elif pretrained == 'sketch_multi':
style_path = f'style_images_aligned/sketch.png'
else:
style_path = f'style_images_aligned/{pretrained}.png'
style_image = transform(Image.open(style_path)).unsqueeze(0).to(device)
face = transform(aligned_face).unsqueeze(0).to(device)
my_output = torch.cat([style_image, face, my_sample], 0)

Generated Result
The results are generated for pre-trained sketch type ‘Jojo’ and look fairly accurate.
Now let’s look at training the GAN on self-created styles/sketches.
Train with your style images
Select some sketches of faces or even create some face sketches of your own and load these image(s) for training the GAN, and set the path. Crop and Align the face and perform GAN inversion.
names = ['1.jpg', '2.jpg', '3.jpg']
targets = []
latents = []
for name in names:
style_path = os.path.join('style_images', name)
assert os.path.exists(style_path), f"{style_path} does not exist!"
name = strip_path_extension(name)
# crop and align the face
style_aligned_path = os.path.join('style_images_aligned', f'{name}.png')
if not os.path.exists(style_aligned_path):
style_aligned = align_face(style_path)
style_aligned.save(style_aligned_path)
else:
style_aligned = Image.open(style_aligned_path).convert('RGB')
# GAN invert
style_code_path = os.path.join('inversion_codes', f'{name}.pt')
if not os.path.exists(style_code_path):
latent = projection(style_aligned, style_code_path, device)
else:
latent = torch.load(style_code_path)['latent']
latents.append(latent.to(device))
targets = torch.stack(targets, 0)
latents = torch.stack(latents, 0)
.png)
Finetune StyleGAN
Finetune StyleGAN by adjusting the alpha, color preservation, and setting the number of iterations. Load the discriminator for perceptual loss and reset the generator.
#Finetune StyleGAN #alpha controls the strength of the style alpha = 1.0 # min:0, max:1, step:0.1 alpha = 1-alpha
#preserve color of original image by limiting family of allowable transformations preserve_color = False #Number of finetuning steps. num_iter = 300 #Log training on wandb and interval for image logging use_wandb = False log_interval = 50
if use_wandb:
wandb.init(project="JoJoGAN")
config = wandb.config
config.num_iter = num_iter
config.preserve_color = preserve_color
wandb.log(
{"Style reference": [wandb.Image(transforms.ToPILImage()(target_im))]},
step=0)
# load discriminator for perceptual loss
discriminator = Discriminator(1024, 2).eval().to(device)
ckpt = torch.load('models/stylegan2-ffhq-config-f.pt', map_location=lambda storage, loc: storage)
discriminator.load_state_dict(ckpt["d"], strict=False)
# reset generator del generator generator = deepcopy(original_generator) g_optim = optim.Adam(generator.parameters(), lr=2e-3, betas=(0, 0.99))
Train the generator to generated image from the latent space, and optimize the loss.
if preserve_color:
id_swap = [9,11,15,16,17]
z = range(numiter)
for idx in tqdm( z):
mean_w = generator.get_latent(torch.randn([latents.size(0), latent_dim]).to(device)).unsqueeze(1).repeat(1, generator.n_latent, 1)
in_latent = latents.clone()
in_latent[:, id_swap] = alpha*latents[:, id_swap] + (1-alpha)*mean_w[:, id_swap]
img = generator(in_latent, input_is_latent=True)
with torch.no_grad():
real_feat = discriminator(targets)
fake_feat = discriminator(img)
loss = sum([functional.l1_loss(a, b) for a, b in zip(fake_feat, real_feat)])/len(fake_feat)
if use_wandb:
wandb.log({"loss": loss}, step=idx)
if idx % log_interval == 0:
generator.eval()
my_sample = generator(my_w, input_is_latent=True)
generator.train()
wandb.log(
{"Current stylization": [wandb.Image(my_sample)]},
step=idx)
g_optim.zero_grad()
loss.backward()
g_optim.step()
Generate the Results using JojoGAN
Now generate the results. Below the results have been generated for both the original and sample images for comparison.
#Generate results
n_sample = 5
seed = 3000
torch.manual_seed(seed)
with torch.no_grad():
generator.eval()
z = torch.randn(n_sample, latent_dim, device=device)
original_sample = original_generator([z], truncation=0.7, truncation_latent=mean_latent)
sample = generator([z], truncation=0.7, truncation_latent=mean_latent)
original_my_sample = original_generator(my_w, input_is_latent=True)
my_sample = generator(my_w, input_is_latent=True)
# display reference images
style_images = []
for name in names:
style_path = f'style_images_aligned/{strip_path_extension(name)}.png'
style_image = transform(Image.open(style_path))
style_images.append(style_image)
face = transform(aligned_face).to(device).unsqueeze(0)
style_images = torch.stack(style_images, 0).to(device)
my_output = torch.cat([face, my_sample], 0) output = torch.cat([original_sample, sample], 0)
.png)
.png)
That’s All! Now you can generate your style of image sketches using JojoGAN. The results are fairly impressive, but can further be improved by tweaking the training methods and having more variety in features in the training images.
Conclusion
JojoGAN has been able to accurately map and transfer user-defined styles in a fast and effective manner. The key takeaways are:
- JojoGAN can be trained with just one style to map it easily and create stylized images of any face
- JojoGAN is very fast and effective and can be trained in less than a minute
- The results are highly accurate and resemble realistic portraits
- JojoGAN can be easily fine-tuned and modified which makes it suitable for AI apps
Thus JojoGAN is the ideal neural network for style transfer regardless of the style type, shapes and color and can thus be a very useful feature in various social media apps and AI applications.
References
Featured Image Architecture Examples Elon MuskMona Lisa Paper
About the Author
Suvojit is a Senior Data Scientist at DunnHumby. He enjoys exploring new and innovative ideas and techniques in the field of AI and tries to solve real-world machine learning problems by thinking out of the box. He writes about the latest advancements in Computer Vision and Natural Language processing. You can follow him on LinkedIn.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Suvojit Hore
22 Jan, 2024







